簡述幾種常用的排序算法
摘要:歸併排序和快速排序是兩種稍微複雜的排序算法,它們用的都是分治的思想,代碼都通過遞歸來實現,過程非常相似。理解歸併排序的重點是理解遞推公式和 merge() 合併函數。
本文分享自華為雲社區《深入淺出八種排序算法》,作者:嵌入式視覺 。
歸併排序和快速排序是兩種稍微複雜的排序算法,它們用的都是分治的思想,代碼都通過遞歸來實現,過程非常相似。理解歸併排序的重點是理解遞推公式和 merge() 合併函數。
一,冒泡排序(Bubble Sort)
排序算法是程序員必須瞭解和熟悉的一類算法,排序算法有很多種,基礎的如:冒泡、插入、選擇、快速、歸併、計數、基數和桶排序等。
冒泡排序只會操作相鄰的兩個數據。每次冒泡操作都會對相鄰的兩個元素進行比較,看是否滿足大小關係要求,如果不滿足就讓它倆互換。一次冒泡會讓至少一個元素移動到它應該在的位置,重複 n 次,就完成了 n 個數據的排序工作。
總結:如果數組有 n 個元素,最壞情況下,需要進行 n 次冒泡操作。
基礎的冒泡排序算法的 C++ 代碼如下:
// 將數據從小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}實際上,以上的冒泡排序算法還可以優化,當某次冒泡操作已經不再進行數據交換時,説明數組已經達到有序,就不需要再繼續執行後續的冒泡操作了。優化後的代碼如下:
// 將數據從小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
// 提前退出冒泡循環發標志位
bool flag = False;
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
flag = True; // 表示本次冒泡操作存在數據交換
}
}
if(!flag) break; // 沒有數據交換,提交退出
}
}冒泡排序的特點:
- 冒泡過程只涉及相鄰元素的交換,只需要常量級的臨時空間,故空間複雜度為 O(1)O(1),是原地排序算法。
- 當有相鄰的兩個元素大小相等的時候,我們不做交換,相同大小的數據在排序前後不會改變順序,所以是穩定排序算法。
- 最壞情況和平均時間複雜度都為 O(n2)O(n2),最好時間複雜度是 O(n)O(n)。
二,插入排序(Insertion Sort)
- 插入排序算法將數組中的數據分為兩個區間:已排序區間和未排序區間。最初始的已排序區間只有一個元素,就是數組的第一個元素。
- 插入排序算法的核心思想就是取未排序區間的一個元素,在已排序區間中找到一個合適的位置插入,並保證已排序區間數據一直有序。
- 重複這個過程,直到未排序區間元素為空,則算法結束。
插入排序和冒泡排序一樣,也包含兩種操作,一種是元素的比較,一種是元素的移動。
當我們需要將一個數據 a 插入到已排序區間時,需要拿 a 與已排序區間的元素依次比較大小,找到合適的插入位置。找到插入點之後,我們還需要將插入點之後的元素順序往後移動一位,這樣才能騰出位置給元素 a 插入。
插入排序的 C++ 代碼實現如下:
void InsertSort(int a[], int n){
if (n <= 1) return;
for (int i = 1; i < n; i++) // 未排序區間範圍
{
key = a[i]; // 待排序第一個元素
int j = i - 1; // 已排序區間末尾元素
// 從尾到頭查找插入點方法
while(key < a[j] && j >= 0){ // 元素比較
a[j+1] = a[j]; // 數據向後移動一位
j--;
}
a[j+1] = key; // 插入數據
}
}插入排序的特點:
- 插入排序並不需要額外存儲空間,空間複雜度是 O(1)O(1),所以插入排序也是一個原地排序算法。
- 在插入排序中,對於值相同的元素,我們可以選擇將後面出現的元素,插入到前面出現元素的後面,這樣就可以保持原有的前後順序不變,所以插入排序是穩定的排序算法。
- 最壞情況和平均時間複雜度都為 O(n2)O(n2),最好時間複雜度是 O(n)O(n)。
三,選擇排序(Selection Sort)
選擇排序算法的實現思路有點類似插入排序,也分已排序區間和未排序區間。但是選擇排序每次會從未排序區間中找到最小的元素,將其放到已排序區間的末尾。
選擇排序的最好情況時間複雜度、最壞情況和平均情況時間複雜度都為 O(n2)O(n2),是原地排序算法,且是不穩定的排序算法。
選擇排序的 C++ 代碼實現如下:
void SelectSort(int a[], int n){
for(int i=0; i<n; i++){
int minIndex = i;
for(int j = i;j<n;j++){
if (a[j] < a[minIndex]) minIndex = j;
}
if (minIndex != i){
temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
}冒泡插入選擇排序總結
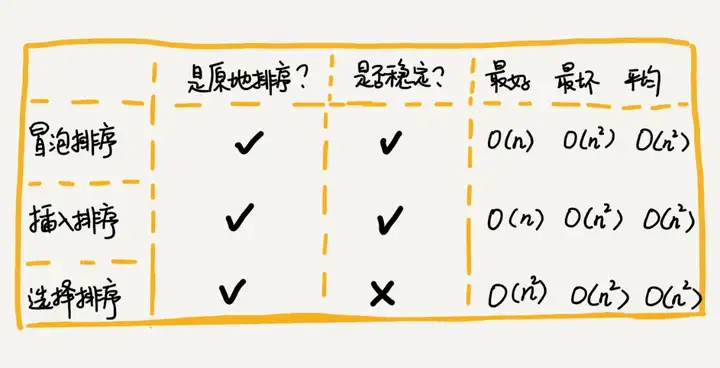
這三種排序算法,實現代碼都非常簡單,對於小規模數據的排序,用起來非常高效。但是在大規模數據排序的時候,這個時間複雜度還是稍微有點高,所以更傾向於用時間複雜度為 O(nlogn)O(nlogn) 的排序算法。
特定算法是依賴特定的數據結構的。以上三種排序算法,都是基於數組實現的。
四,歸併排序(Merge Sort)
歸併排序的核心思想比較簡單。如果要排序一個數組,我們先把數組從中間分成前後兩部分,然後對前後兩部分分別排序,再將排好序的兩部分合並在一起,這樣整個數組就都有序了。
歸併排序使用的是分治思想。分治,顧名思義,就是分而治之,將一個大問題分解成小的子問題來解決。小的子問題解決了,大問題也就解決了。
分治思想和遞歸思想有些類似,分治算法一般用遞歸實現。分治是一種解決問題的處理思想,遞歸是一種編程技巧,這兩者並不衝突。
知道了歸併排序用的是分治思想,而分治思想一般用遞歸實現,接下來的重點就是如何用遞歸實現歸併排序。寫遞歸代碼的技巧就是,分析問題得出遞推公式,然後找到終止條件,最後將遞推公式翻譯成遞歸代碼。所以,要想寫出歸併排序的代碼,得先寫出歸併排序的遞推公式。
遞推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
終止條件:
p >= r 不用再繼續分解,即區間數組元素為 1 歸併排序的偽代碼如下:
merge_sort(A, n){
merge_sort_c(A, 0, n-1)
}
merge_sort_c(A, p, r){
// 遞歸終止條件
if (p>=r) then return
// 取 p、r 中間的位置為 q
q = (p+r)/2
// 分治遞歸
merge_sort_c(A[p, q], p, q)
merge_sort_c(A[q+1, r], q+1, r)
// 將A[p...q]和A[q+1...r]合併為A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}4.1,歸併排序性能分析
1,歸併排序是一個穩定的排序算法。分析:偽代碼中 merge_sort_c() 函數只是分解問題並沒有涉及移動元素和比較大小,真正的元素比較和數據移動在 merge() 函數部分。在合併過程中保證值相同的元素合併前後的順序不變,歸併排序排序就是一個穩定的排序算法。
2,歸併排序的執行效率與要排序的原始數組的有序程度無關,所以其時間複雜度是非常穩定的,不管是最好情況、最壞情況,還是平均情況,時間複雜度都是 O(nlogn)O(nlogn)。分析:不僅遞歸求解的問題可以寫成遞推公式,遞歸代碼的時間複雜度也可以寫成遞推公式:

3,空間複雜度是 O(n)。分析:遞歸代碼的空間複雜度並不能像時間複雜度那樣累加。儘管算法的每次合併操作都需要申請額外的內存空間,但在合併完成之後,臨時開闢的內存空間就被釋放掉了。在任意時刻,CPU 只會有一個函數在執行,也就只會有一個臨時的內存空間在使用。臨時內存空間最大也不會超過 n 個數據的大小,所以空間複雜度是 O(n)O(n)。
五,快速排序(Quicksort)
快排的思想是這樣的:如果要排序數組中下標從 p 到 r 之間的一組數據,我們選擇 p 到 r 之間的任意一個數據作為 pivot(分區點)。我們遍歷 p 到 r 之間的數據,將小於 pivot 的放到左邊,將大於 pivot 的放到右邊,將 pivot 放到中間。經過這一步驟之後,數組 p 到 r 之間的數據就被分成了三個部分,前面 p 到 q-1 之間都是小於 pivot 的,中間是 pivot,後面的 q+1 到 r 之間是大於 pivot 的。
根據分治、遞歸的處理思想,我們可以用遞歸排序下標從 p 到 q-1 之間的數據和下標從 q+1 到 r 之間的數據,直到區間縮小為 1,就説明所有的數據都有序了。
遞推公式如下:
遞推公式:
quick_sort(p,r) = quick_sort(p, q-1) + quick_sort(q, r)
終止條件:
p >= r歸併排序和快速排序總結
歸併排序和快速排序是兩種稍微複雜的排序算法,它們用的都是分治的思想,代碼都通過遞歸來實現,過程非常相似。理解歸併排序的重點是理解遞推公式和 merge() 合併函數。同理,理解快排的重點也是理解遞推公式,還有 partition() 分區函數。
除了以上 5 種排序算法,還有 3 種時間複雜度是 O(n)O(n) 的線性排序算法:桶排序、計數排序、基數排序。這八種排序算法性能總結如下圖:
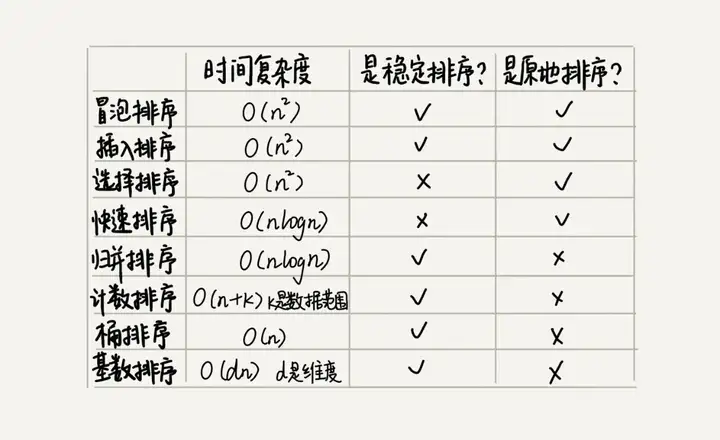
參考資料
- 排序(上):為什麼插入排序比冒泡排序更受歡迎?
- 排序(下):如何用快排思想在O(n)內查找第K大元素?
- 使用卷積神經網絡實現圖片去摩爾紋
- 內核不中斷前提下,Gaussdb(DWS)內存報錯排查方法
- 簡述幾種常用的排序算法
- 自動調優工具AOE,讓你的模型在昇騰平台上高效運行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及代碼實現
- CosineWarmup理論與代碼實戰
- 淺談DWS函數出參方式
- 代碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種數據預處理的方式:AIPP和DVPP
- 詳解ResNet 網絡,如何讓網絡變得更“深”了
- 帶你掌握如何查看並讀懂昇騰平台的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網絡卷積層?
- 在昇騰平台上對TensorFlow網絡進行性能調優
- 介紹3種ssh遠程連接的方式
- 分佈式數據庫架構路線大揭祕
- DBA必備的Mysql知識點:數據類型和運算符
- 5個高併發導致數倉資源類報錯分析