ChunJun框架在數據還原上的探索和實踐 | Hadoop Meetup精彩回顧
Hadoop是Apache基金會旗下最知名的基礎架構開源項目之一。自2006年誕生以來,逐步發展成為海量數據存儲、處理最為重要的基礎組件,形成了非常豐富的技術生態。
作為國內頂尖的 Hadoop 開源生態技術峯會,第四屆 China Apache Hadoop Meetup於 2022年9月24日在上海成功舉辦。
圍繞“雲數智聚 砥柱篤行”的主題,來自華為、阿里、網易、字節跳動、bilibili、平安銀行、袋鼠雲、英特爾、Kyligence、Ampere等多所企業單位,以及來自Spark、Fluid、ChunJun、Kyuubi、Ozone、IoTDB、Linkis、Kylin、Uniffle等開源社區的多位嘉賓均參與了分享討論。

作為此次Meetup參與社區之一,也是大數據領域的項目,ChunJun也帶來了一些新的聲音:
ChunJun框架在實時數據採集和還原上的實現和原理是怎樣的?這段時間以來,ChunJun有哪些新發展,對於未來發展又有着怎樣的新想法?
作為袋鼠雲資深大數據引擎開發專家,徐超帶來了他的分享,將從一個獨特的角度來介紹ChunJun數據集成在數據還原上的探索和實踐。 
一、ChunJun框架介紹
第一個問題:ChunJun這個框架是什麼?能幹啥?
ChunJun(原FlinkX) 是袋鼠雲基於Flink 基座自研的數據集成框架,經過4年多的迭代,已經成為一個穩定,高效,易用的批流一體的數據集成工具,可實現多種異構數據源高效的數據同步,目前已有3.2K+Star。
開源項目地址:
http://github.com/DTStack/chunjun
http://gitee.com/dtstack_dev_0/chunjun
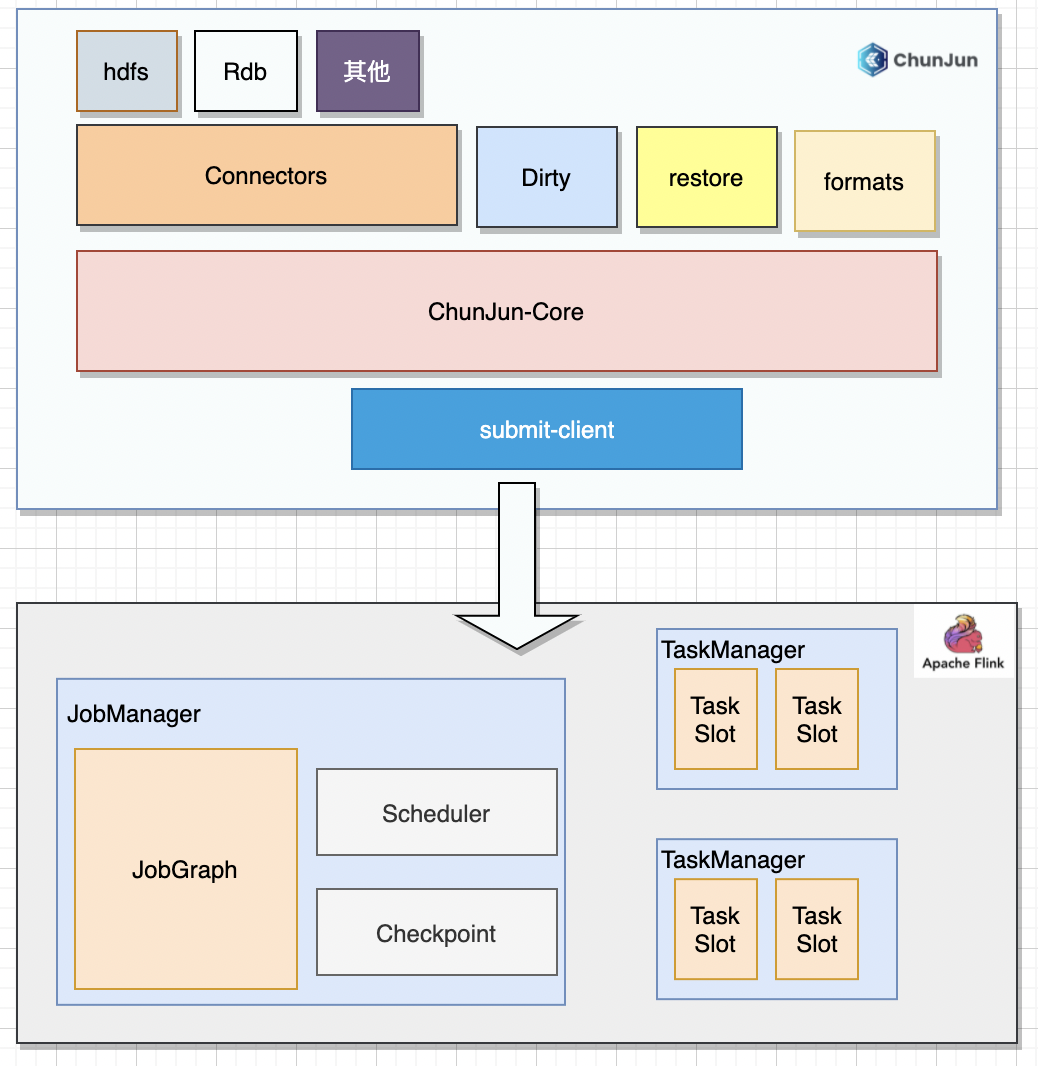
01 ChunJun框架結構
ChunJun 框架基於Flink 進行開發,提供了豐富的插件,同時添加了斷點續傳、髒數據管理、數據還原等特性。
02 ChunJun批量同步
• 支持增量同步
• 支持斷點續傳
• 支持多通道&併發
• 支持髒數據(記錄和控制)
• 支持限流
• 支持transformer
03 ChunJun離線
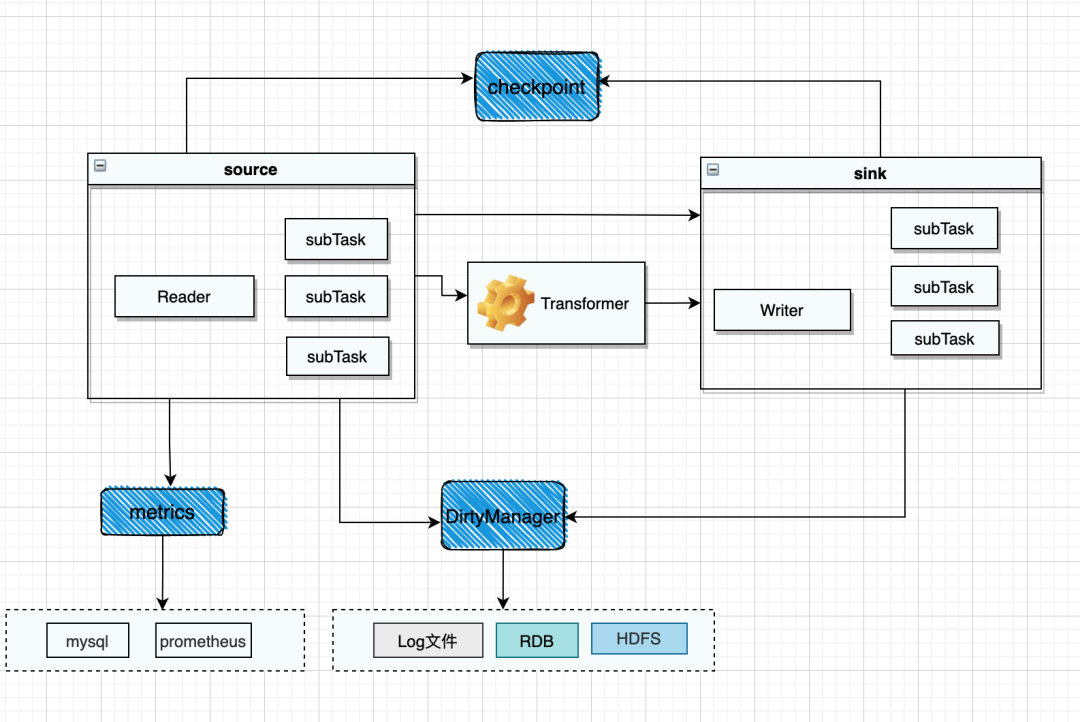
二、實時數據採集上的實現和原理
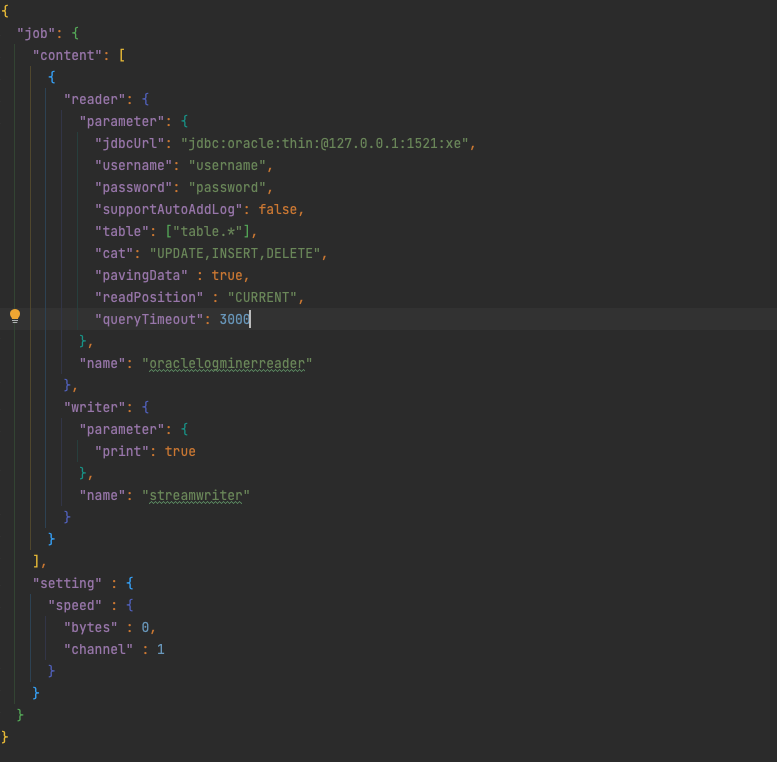
01 一個樣例
02 ChunJun插件裝載邏輯
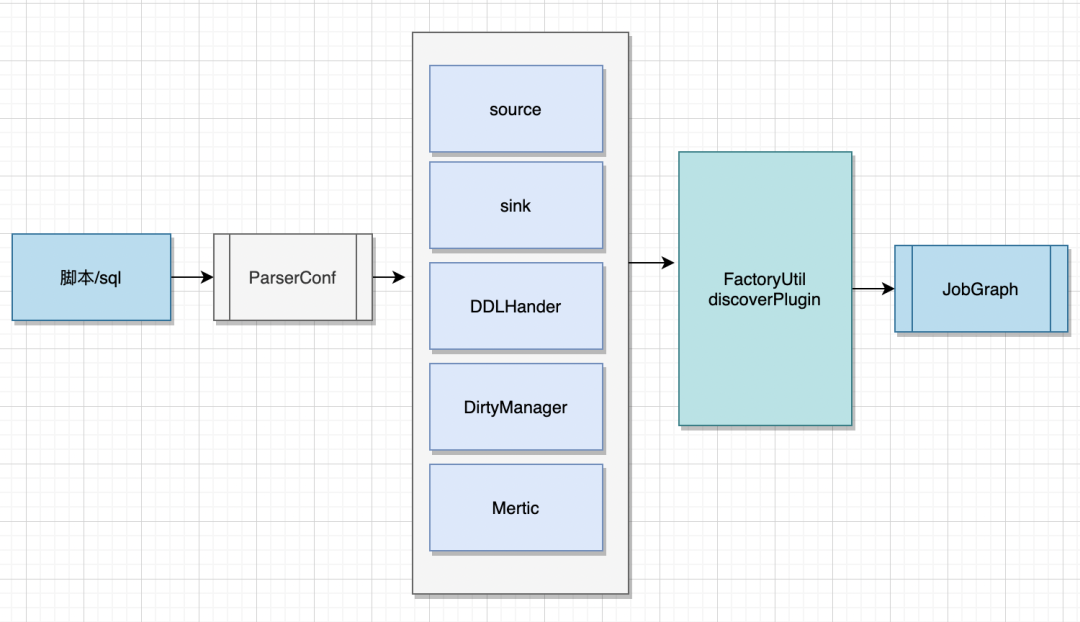
03 ChunJun插件定義
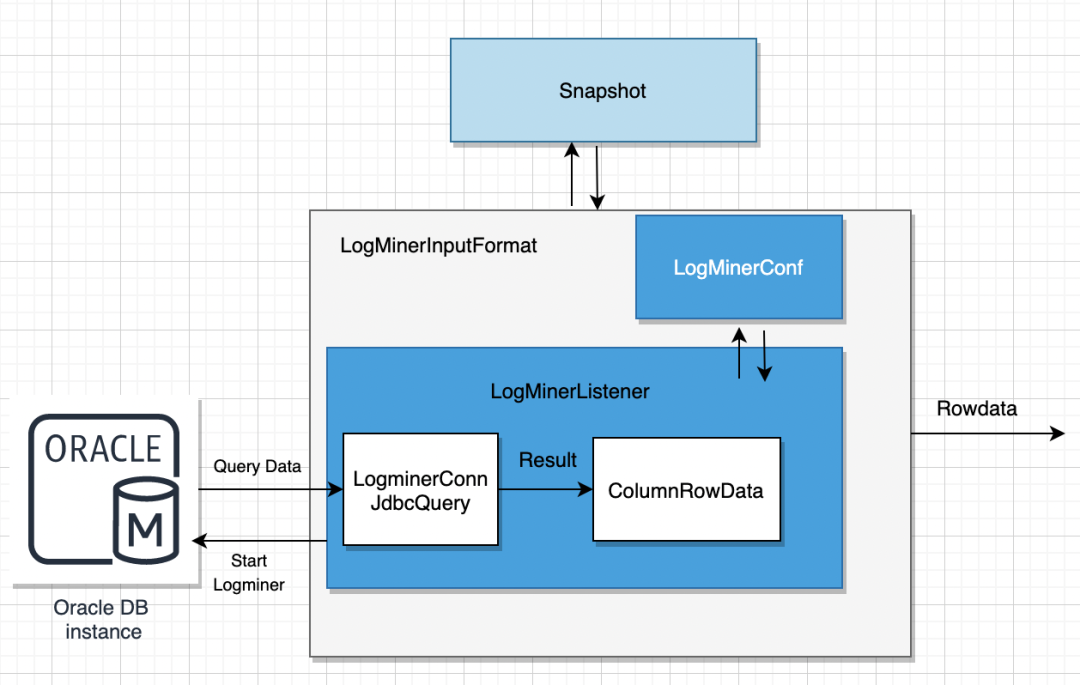
04 ChunJun數據流轉
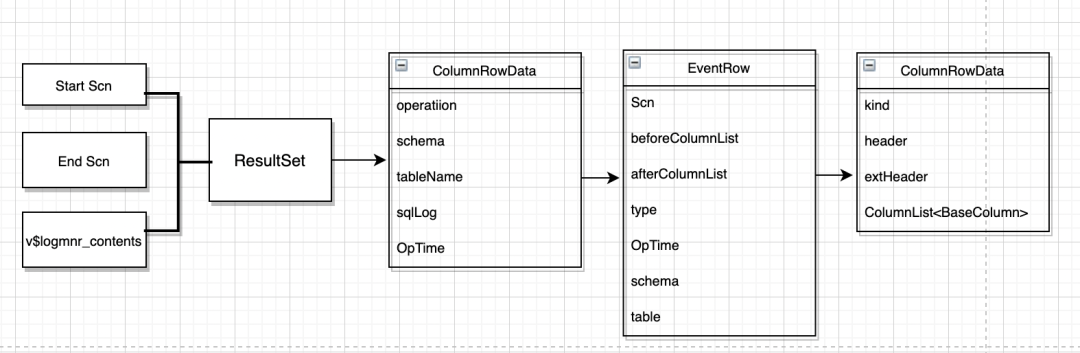
05 ChunJun動態執行
面對監聽多個表的情況,包括新添加表的數據,我們如何執行下游的寫入:
• 支持Update 轉換 before,after
• 添加擴展參數,DB,Schema,Table, ColumnInfo
• 支持動態構建PreparedStatement
06 ChunJun間隔輪詢
什麼是間隔輪詢?我們是如何做的?
• 校驗輪詢字段類型,如果不是數值類型且source並行度大於1,報錯不支持
• 創建三個數據分片,startlocation為null或者配置的值,mod分別為0,1,2
• 構造SQL:不同SQL的取餘函數不同,各自插件實現
select id,name,age from table where (id > ? and ) mod(id, 3) = 0 order by id;
select id,name,age from table where (id > ? and ) mod(id, 3) = 1 order by id;
select id,name,age from table where (id > ? and ) mod(id, 3) = 2 order by id;
• 執行SQL,查詢並更新lastRow
• 第一次result查詢完後,若腳本中沒有配置startlocation,則之前的查詢SQL為:
select id,name,age from table where mod(id, 3) = 1 order by id;
將其更新為:
select id,name,age from table where id > ? and mod(id, 3) = 1 order by id;
• CP時獲取lastRow中的id值,保存到state中
三、實時數據還原上的實現和原理
01 數據還原介紹
數據還原基於對應的數據庫的CDC採集功能,比如上面提到的Oracle Logminer,MySQL binglog,支持將捕獲到的數據完整的還原到下游,所以不僅僅包括DML,而且也需要對DDL進行監聽,將上游數據源的所有變更行為發送到下游數據庫的還原。
難點
· DDL,DML 如何有序的發送到下游
· DDL 語句如何根據下游數據源的特性進行對應的操作(異構數據源間DML 的轉換)
· DML 語句中的insert update, delete 如何進行處理
02 一個樣例

03 整體流程
數據從上游的數據源獲取之後經過一些列的算子的處理之後按數據在原始表中的順序準確的還原到目標數據源,完成數據的實時獲取鏈路。
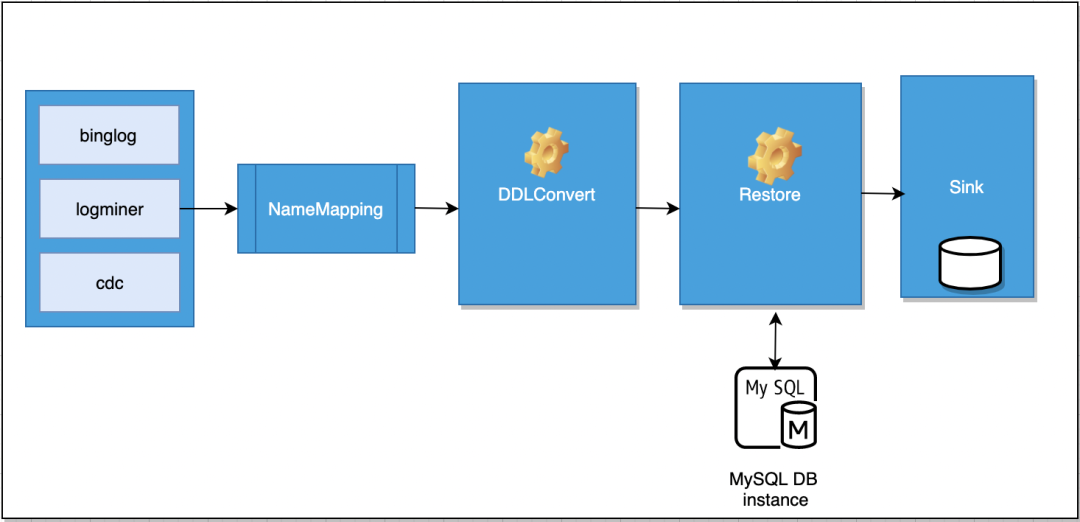
04 DDL解析

數據還原- DDL轉換
· 基於Calcite解析數據源DdlSql轉為SqlNode
· SqlNode轉為中間數據DdlData
· ddlData轉為sql:不同語法之間互相轉換;不同數據源字段類型互相轉換
05 名字映射
在實時還原中,當前上下游表字段對應關係必須是相同的,即上游的database schema table 對應的表只能寫入下游database schema table相同的表,同時字段名稱也必須是相同的。本次迭代將針對表路徑可以進行一個自定義映射以及字段類型進行自定義映射。
• db or schema 轉換
• 表名稱轉換
• 字段名(提供大小寫轉換),類型隱式轉換
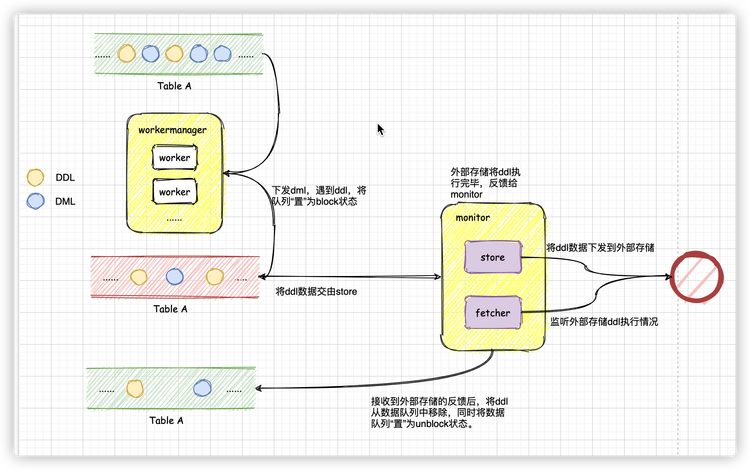
06 中間數據緩存
數據(不論ddl還是dml數據)下發到對應表名下的unblock隊列中,worker在輪詢過程中,處理unblock數據隊列中的數據,在遇到ddl數據之後,將數據隊列置為block狀態,並將隊列引用交給store處理。
store在拿到隊列引用之後,將隊列頭部的ddl數據下發到外部存儲中,並監聽外部存儲對ddl的反饋情況(監聽工作由store中額外的線程來執行),此時,隊列仍然處於block狀態。
在收到外部存儲的反饋之後,將數據隊列頭部的ddl數據移除,同時將隊列狀態迴歸為unblock狀態,隊列引用還給worker。
07 目標端接收數據
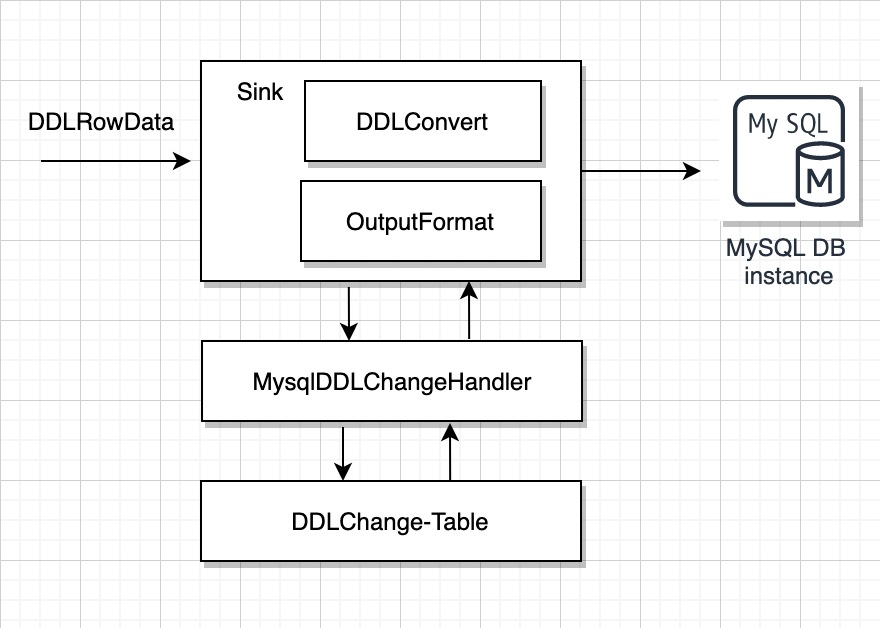
• 獲取到DdlOperator 對象
• 根據目標數據源對應的DDLConvertImpl解析器轉換為目標數據源sql
• 執行對應的sql,比如刪除表
• 觸發調整DDLChange 表,修改對應的DDL 狀態
• 中間存儲Restore算子,監聽狀態變更,執行後續數據下發操作
四、ChunJun未來規劃
• 提供對Session 進行管理
• 提供restful 服務,ChunJun 本身作為一個服務,便於外圍系統進行集成
• 對實時數據還原進行加強,包括擴展支持更多的數據源的DDL 解析
此外,本次分享的全文視頻內容也可以隨時觀看,如果您有興趣,歡迎前往袋鼠雲B站平台觀看。
Apache Hadoop Meetup 2022
ChunJun視頻回顧:
http://www.bilibili.com/video/BV1sN4y1P7qk/?spm_id_from=333.337.search-card.all.click
袋鼠雲開源框架釘釘技術交流羣(30537511),歡迎對大數據開源項目有興趣的同學加入交流最新技術信息,開源項目庫地址:http://github.com/DTStack/Taier
- 從5分鐘到60秒,袋鼠雲數棧在熱重啟技術上的提效探索之路
- 詳細剖析|袋鼠雲數棧前端框架Antd 3.x 升級 4.x 的踩坑之路
- Teradata在華落幕,國產化崛起,袋鼠雲數棧會是更好的選擇嗎?
- 大數據應用場景下,標籤策略如何實現價值最大化?
- 袋鼠雲數棧UI5.0煥新升級,全新設計語言DT Design,更懂視覺更懂你!
- 一看就懂!任務提交的資源判斷在Taier中的實踐
- 看這篇就夠了丨基於Calcite框架的SQL語法擴展探索
- 無監控,不運維!深入淺出介紹ChengYing監控設計和使用
- DAG任務調度系統 Taier 演進之道,探究DataSourceX 模塊
- 數字孿生賦能智慧港口解決方案,助力港口數字化轉型
- Iceberg在袋鼠雲的探索及實踐
- Kerberos身份驗證在ChunJun中的落地實踐
- 從數據治理到數據應用,製造業企業如何突破數字化轉型困境丨行業方案
- 行業方案 | 新規落地,企業集團財務公司如何構建數智財務體系?
- 數據安全新戰場,EasyMR為企業築起“安全防線”
- ChunJun框架在數據還原上的探索和實踐 | Hadoop Meetup精彩回顧
- 開源直播課丨大數據集成框架ChunJun類加載器隔離方案探索及實踐
- 激活數據價值,探究DataOps下的數據架構及其實踐丨DTVision開發治理篇
- 實用五步法教會你指標體系的設計與加工
- 他來了!袋鼠雲大數據基礎平台EasyMR正式上線