Node.js 實現輕量化進程池和線程池
I. 前言
本文論點主要面向 Node.js 開發語言
>> Show Me Code,目前代碼正在 dev 分支,已完成單元測試,尚待測試所有場景。
>> 建議通讀 Node.js 官方文檔 -【不要阻塞事件循環】
Node.js 即服務端 Javascript,得益於宿主環境的不同,它擁有比在瀏覽器上更多的能力。比如:完整的文件系統訪問權限、網絡協議、套接字編程、進程和線程操作、C++ 插件源碼級的支持、Buffer 二進制、Crypto 加密套件的天然支持。
Node.js 的是一門單線程的語言,它基於 V8 引擎開發,v8 在設計之初是在瀏覽器端對 JavaScript 語言的解析運行引擎,其最大的特點是單線程,這樣的設計避免了一些多線程狀態同步問題,使得其更輕量化易上手。
一、名詞定義
1. 進程
學術上説,進程是一個具有一定獨立功能的程序在一個數據集上的一次動態執行的過程,是操作系統進行資源分配和調度的一個獨立單位,是應用程序運行的載體。我們這裏將進程比喻為工廠的車間,它代表 CPU 所能處理的單個任務。任一時刻,CPU 總是運行一個進程,其他進程處於非運行狀態。
進程具有以下特性:
- 進程是擁有資源的基本單位,資源分配給進程,同一進程的所有線程共享該進程的所有資源;
- 進程之間可以併發執行;
- 在創建或撤消進程時,系統都要為之分配和回收資源,與線程相比系統開銷較大;
- 一個進程可以有多個線程,但至少有一個線程;
2. 線程
在早期的操作系統中並沒有線程的概念,進程是能擁有資源和獨立運行的最小單位,也是程序執行的最小單位。任務調度採用的是時間片輪轉的搶佔式調度方式,而進程是任務調度的最小單位,每個進程有各自獨立的一塊內存,使得各個進程之間內存地址相互隔離。
後來,隨着計算機的發展,對 CPU 的要求越來越高,進程之間的切換開銷較大,已經無法滿足越來越複雜的程序的要求了。於是就發明了線程,線程是程序執行中一個單一的順序控制流程,是程序執行流的最小單元。這裏把線程比喻一個車間的工人,即一個車間可以允許由多個工人協同完成一個任務,即一個進程中可能包含多個線程。
線程具有以下特性:
- 線程作為調度和分配的基本單位;
- 多個線程之間也可併發執行;
- 線程是真正用來執行程序的,執行計算的;
- 線程不擁有系統資源,但可以訪問隸屬於進程的資源,一個線程只能屬於一個進程;
Node.js 的多進程有助於充分利用 CPU 等資源,Node.js 的多線程提升了單進程上任務的並行處理能力。
在 Node.js 中,每個 worker 線程都有他自己的 V8 實例和事件循環機制 (Event Loop)。但是,和進程不同,workers 之間是可以共享內存的。
二、Node.js 異步機制
1. Node.js 內部線程池、異步機制以及宏任務優先級劃分
Node.js 的單線程是指程序的主要執行線程是單線程,這個主線程同時也負責事件循環。而其實語言內部也會創建線程池來處理主線程程序的 網絡 IO / 文件 IO / 定時器 等調用產生的異步任務。一個例子就是定時器 Timer 的實現:在 Node.js 中使用定時器時,Node.js 會開啟一個定時器線程進行計時,計時結束時,定時器回調函數會被放入位於主線程的宏任務隊列。當事件循環系統執行完主線程同步代碼和當前階段的所有微任務時,該回調任務最後再被取出執行。所以 Node.js 的定時器其實是不準確的,只能保證在預計時間時我們的回調任務被放入隊列等待執行,而不是直接被執行。

多線程機制配合 Node.js 的 evet loop 事件循環系統讓開發者在一個線程內就能夠使用異步機制,包括定時器、IO、網絡請求。但為了實現高響應度的高性能服務器,Node.js 的 Event Loop 在宏任務上進一步劃分了優先級。

Node.js 宏任務之間的優先級劃分:Timers > Pending > Poll > Check > Close。
- Timers Callback: 涉及到時間,肯定越早執行越準確,所以這個優先級最高很容易理解。
- Pending Callback:處理網絡、IO 等異常時的回調,有的 unix 系統會等待發生錯誤的上報,所以得處理下。
- Poll Callback:處理 IO 的 data,網絡的 connection,服務器主要處理的就是這個。
- Check Callback:執行 setImmediate 的回調,特點是剛執行完 IO 之後就能回調這個。
- Close Callback:關閉資源的回調,晚點執行影響也不到,優先級最低。
Node.js 微任務之間的優化及劃分:process.nextTick > Promise。
2. Node.js 宏任務和微任務的執行時機
node 11 之前,Node.js 的 Event Loop 並不是瀏覽器那種一次執行一個宏任務,然後執行所有的微任務,而是執行完一定數量的 Timers 宏任務,再去執行所有微任務,然後再執行一定數量的 Pending 的宏任務,然後再去執行所有微任務,剩餘的 Poll、Check、Close 的宏任務也是這樣。node 11 之後改為了每個宏任務都執行所有微任務了。
而 Node.js 的 宏任務之間也是有優先級的,如果 Node.js 的 Event Loop 每次都是把當前優先級的所有宏任務跑完再去跑下一個優先級的宏任務,那麼會導致 “飢餓” 狀態的發生。如果某個階段宏任務太多,下個階段就一直執行不到了,所以每個類型的宏任務有個執行數量上限的機制,剩餘的交給之後的 Event Loop 再繼續執行。
最終表現就是:也就是執行一定數量的 Timers 宏任務,每個宏任務之間執行所有微任務,再一定數量的 Pending Callback 宏任務,每個宏任務之間再執行所有微任務。
三、Node.js 的多進程
1. 使用 child_process 方式手動創建進程
Node.js 程序通過 child_process 模塊提供了衍生子進程的能力,child_process 提供多種子進程的創建方式:
- spawn 創建新進程,執行結果以流的形式返回,只能通過事件來獲取結果數據,操作麻煩。
```js const spawn = require('child_process').spawn; const ls = spawn('ls', ['-lh', '/usr']);
ls.stdout.on('data', (data) => {
console.log(stdout: ${data});
});
ls.stderr.on('data', (data) => {
console.log(stderr: ${data});
});
ls.on('close', (code) => {
console.log(child process exited with code ${code});
});
```
- execFile 創建新進程,按照其後面的 File 名字,執行一個可執行文件,可以帶選項,以回調形式返回調用結果,可以得到完整數據,方便了很多。
js
execFile('/path/to/node', ['--version'], function(error, stdout, stderr){
if(error){
throw error;
}
console.log(stdout);
});
- exec 創建新進程,可以直接執行 shell 命令,簡化了 shell 命令執行方式,執行結果以回調方式返回。
js
exec('ls -al', function(error, stdout, stderr){
if(error) {
console.error('error:' + error);
return;
}
console.log('stdout:' + stdout);
console.log('stderr:' + typeof stderr);
});
- fork 創建新進程,執行 node 程序,進程擁有完整的 V8 實例,創建後自動開啟主進程到子進程的 IPC 通信,資源佔用最多。
```js var child = child_process.fork('./anotherSilentChild.js', { silent: true });
child.stdout.setEncoding('utf8'); child.stdout.on('data', function(data){ console.log(data); }); ```
其中,spawn 是所有方法的基礎,exec 底層是調用了 execFile。
2. 使用 cluster 方式半自動創建進程
以下是使用 Cluster 模塊創建一個 http 服務集羣的簡單示例。示例中創建 Cluster 時使用同一個 Js 執行文件,在文件內使用 cluster.isPrimary 判斷當前執行環境是在主進程還是子進程,如果是主進程則使用當前執行文件創建子進程實例,如果時子進程則進入子進程的業務處理流程。
```js / 簡單示例:使用同一個 JS 執行文件創建子進程集羣 Cluster / const cluster = require('node:cluster'); const http = require('node:http'); const numCPUs = require('node:os').cpus().length; const process = require('node:process');
if (cluster.isPrimary) {
console.log(Primary ${process.pid} is running);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(worker ${worker.process.pid} died);
});
} else {
// Workers can share any TCP connection
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(Worker ${process.pid} started);
}
```
Cluster 模塊允許設立一個主進程和若干個子進程,使用 child_process.fork() 在內部隱式創建子進程,由主進程監控和協調子進程的運行。
子進程之間採用進程間通信交換消息,Cluster 模塊內置一個負載均衡器,採用 Round-robin 算法(輪流執行)協調各個子進程之間的負載。運行時,所有新建立的連接都由主進程完成,然後主進程再把 TCP 連接分配給指定的子進程。
使用集羣創建的子進程可以使用同一個端口,Node.js 內部對 http/net 內置模塊進行了特殊支持。Node.js 主進程負責監聽目標端口,收到請求後根據負載均衡策略將請求分發給某一個子進程。
3. 使用基於 Cluster 封裝的 PM2 工具全自動創建進程
PM2 是常用的 node 進程管理工具,它可以提供 node.js 應用管理能力,如自動重載、性能監控、負載均衡等。
其主要用於 獨立應用 的進程化管理,在 Node.js 單機服務部署方面比較適合。可以用於生產環境下啟動同個應用的多個實例提高 CPU 利用率、抗風險、熱加載等能力。
由於是外部庫,需要使用 npm 包管理器安裝:
bash
$: npm install -g pm2
pm2 支持直接運行 server.js 啟動項目,如下:
bash
$: pm2 start server.js
即可啟動 Node.js 應用,成功後會看到打印的信息:
bash
┌──────────┬────┬─────────┬──────┬───────┬────────┬─────────┬────────┬─────┬───────────┬───────┬──────────┐
│ App name │ id │ version │ mode │ pid │ status │ restart │ uptime │ cpu │ mem │ user │ watching │
├──────────┼────┼─────────┼──────┼───────┼────────┼─────────┼────────┼─────┼───────────┼───────┼──────────┤
│ server │ 0 │ 1.0.0 │ fork │ 24776 │ online │ 9 │ 19m │ 0% │ 35.4 MB │ 23101 │ disabled │
└──────────┴────┴─────────┴──────┴───────┴────────┴─────────┴────────┴─────┴───────────┴───────┴──────────┘
pm2 也支持配置文件啟動,通過配置文件 ecosystem.config.js 可以定製 pm2 的各項參數:
```js module.exports = { apps : [{ name: 'API', // 應用名 script: 'app.js', // 啟動腳本 args: 'one two', // 命令行參數 instances: 1, // 啟動實例數量 autorestart: true, // 自動重啟 watch: false, // 文件更改監聽器 max_memory_restart: '1G', // 最大內存使用亮 env: { // development 默認環境變量 // pm2 start ecosystem.config.js --watch --env development NODE_ENV: 'development' }, env_production: { // production 自定義環境變量 NODE_ENV: 'production' } }],
deploy : { production : { user : 'node', host : '212.83.163.1', ref : 'origin/master', repo : '[email protected]:repo.git', path : '/var/www/production', 'post-deploy' : 'npm install && pm2 reload ecosystem.config.js --env production' } } }; ```
pm2 logs 日誌功能也十分強大:
bash
$: pm2 logs
II. Node.js 中進程池和線程池的適用場景
一般我們使用計算機執行的任務包含以下幾種類型的任務:
- 計算密集型任務:任務包含大量計算,CPU 佔用率高。
js
const matrix = {};
for (let i = 0; i < 10000; i++) {
for (let j = 0; j < 10000; j++) {
matrix[`${i}${j}`] = i * j;
}
}
- IO 密集型任務:任務包含頻繁的、持續的網絡 IO 和磁盤 IO 的調用。
js
const {copyFileSync, constants} = require('fs');
copyFileSync('big-file.zip', 'destination.zip');
- 混合型任務:既有計算也有 IO。
一、進程池的適用場景
使用進程池的最大意義在於充分利用多核 CPU 資源,同時減少子進程創建和銷燬的資源消耗。
進程是操作系統分配資源的基本單位,使用多進程架構能夠更多的獲取 CPU 時間、內存等資源。為了應對 CPU-Sensitive 場景,以及充分發揮 CPU 多核性能,Node 提供了 child_process 模塊用於創建子進程。
子進程的創建和銷燬需要較大的資源成本,因此池化子進程的創建和銷燬過程,利用進程池來管理所有子進程。
除了這一點,Node.js 中子進程也是唯一的執行二進制文件的方式,Node.js 可通過流 (stdin/stdout/stderr) 或 IPC 和子進程通信。
通過 Stream 通信
```js const {spawn} = require('child_process'); const ls = spawn('ls', ['-lh', '/usr']);
ls.stdout.on('data', (data) => {
console.log(stdout: ${data});
});
ls.stderr.on('data', (data) => {
console.error(stderr: ${data});
});
ls.on('close', (code) => {
console.log(child process exited with code ${code});
});
```
通過 IPC 通信
``js
const cp = require('child_process');
const n = cp.fork(${__dirname}/sub.js`);
n.on('message', (m) => { console.log('PARENT got message:', m); });
n.send({hello: 'world'}); ```
二、線程池的適用場景
使用線程池的最大意義在於多任務並行,為主線程降壓,同時減少線程創建和銷燬的資源消耗。單個 CPU 密集性的計算任務使用線程執行並不會更快,甚至線程的創建、銷燬、上下文切換、線程通信、數據序列化等操作還會額外增加資源消耗。
但是如果一個計算機程序中有很多同一類型的阻塞任務需要執行,那麼將他們交給線程池可以成倍的減少任務總的執行時間,因為在同一時刻多個線程在並行進行計算。如果多個任務只使用主線程執行,那麼最終消耗的時間是線性疊加的,同時主線程阻塞之後也會影響其它任務的處理。
特別是對 Node.js 這種單主線程的語言來講,主線程如果消耗了過多的時間來執行這些耗時任務,那麼對整個 Node.js 單個進程實例的性能影響將是致命的。這些佔用着 CPU 時間的操作將導致其它任務獲取的 CPU 時間不足或 CPU 響應不夠及時,被影響的任務將進入 “飢餓” 狀態。
因此 Node.js 啟動後主線程應儘量承擔調度的角色,批量重型 CPU 佔用任務的執行應交由額外的工作線程處理,主線程最後拿到工作線程的執行結果再返回給任務調用方。另一方面由於 IO 操作 Node.js 內部作了優化和支持,因此 IO 操作應該直接交給主線程,主線程再使用內部線程池處理。
Node.js 的異步能不能解決過多佔用 CPU 任務的執行問題?
答案是:不能,過多的異步 CPU 佔用任務會阻塞事件循環。
Node.js 的異步在 網絡 IO / 磁盤 IO 處理上很有用,宏任務微任務系統 + 內部線程調用能分擔主進程的執行壓力。但是如果單獨將 CPU 佔用任務放入宏任務隊列或微任務隊列,對任務的執行速度提升沒有任何幫助,只是一種任務調度方式的優化而已。
我們只是延遲了任務的執行或是將巨大任務分散成多個再分批執行,但是任務最終還是要在主線程被執行。如果這類任務過多,那麼任務分片和延遲的效果將完全消失,一個任務可以,那十個一百個呢?量變將會引起質變。
以下是 Node.js 官方博客中的原文:
“如果你需要做更復雜的任務,拆分可能也不是一個好選項。這是因為拆分之後任務仍然在事件循環線程中執行,並且你無法利用機器的多核硬件能力。 請記住,事件循環線程只負責協調客户端的請求,而不是獨自執行完所有任務。 對一個複雜的任務,最好把它從事件循環線程轉移到工作線程池上。”
- 場景:間歇性讓主進程 癱瘓
每一秒鐘,主線程有一半時間被佔用 ```js // this task costs 100ms function doHeavyTask() { ...}
setInterval(() => { doHeavyTask(); // 100ms doHeavyTask(); // 200ms doHeavyTask(); // 300ms doHeavyTask(); // 400ms doHeavyTask(); // 500ms }, 1e3); ```
- 場景:高頻性讓主進程 半癱瘓
每 200ms,主線程有一半時間被佔用 ```js // this task costs 100ms function doHeavyTask() { ...}
setInterval(() => { doHeavyTask(); }, 1e3);
setInterval(() => { doHeavyTask(); }, 1.2e3);
setInterval(() => { doHeavyTask(); }, 1.4e3);
setInterval(() => { doHeavyTask(); }, 1.6e3);
setInterval(() => { doHeavyTask(); }, 1.8e3); ```
以下是官方博客的原文摘錄:
“因此,你應該保證永遠不要阻塞事件輪詢線程。換句話説,每個 JavaScript 回調應該快速完成。這些當然對於 await,Promise.then 也同樣適用。”
III. 進程池
進程池是對進程的創建、執行任務、銷燬等流程進行管控的一個應用或是一套程序邏輯。之所以稱之為池是因為其內部包含多個進程實例,進程實例隨時都在進程池內進行着狀態流轉,多個創建的實例可以被重複利用,而不是每次執行完一系列任務後就被銷燬。因此,進程池的部分存在目的是為了減少進程創建的資源消耗。
此外進程池最重要的一個作用就是負責將任務分發給各個進程執行,各個進程的任務執行優先級取決於進程池上的負載均衡運算,由算法決定應該將當前任務派發給哪個進程,以達到最高的 CPU 和內存利用率。常見的負載均衡算法有:
- POLLING - 輪詢:子進程輪流處理請求
- WEIGHTS - 權重:子進程根據設置的權重來處理請求
- RANDOM - 隨機:子進程隨機處理請求
- SPECIFY - 指定:子進程根據指定的進程 id 處理請求
- WEIGHTS_POLLING - 權重輪詢:權重輪詢策略與輪詢策略類似,但是權重輪詢策略會根據權重來計算子進程的輪詢次數,從而穩定每個子進程的平均處理請求數量。
- WEIGHTS_RANDOM - 權重隨機:權重隨機策略與隨機策略類似,但是權重隨機策略會根據權重來計算子進程的隨機次數,從而穩定每個子進程的平均處理請求數量。
- MINIMUM_CONNECTION - 最小連接數:選擇子進程上具有最小連接活動數量的子進程處理請求。
- WEIGHTS_MINIMUM_CONNECTION - 權重最小連接數:權重最小連接數策略與最小連接數策略類似,不過各個子進程被選中的概率由連接數和權重共同決定。
一、要點
「 對單一任務的控制不重要,對單個進程宏觀的資源佔用更需關注 」
二、流程設計
進程池架構圖參考之前的進程管理工具開發相關 文章,本文只需關注進程池部分。
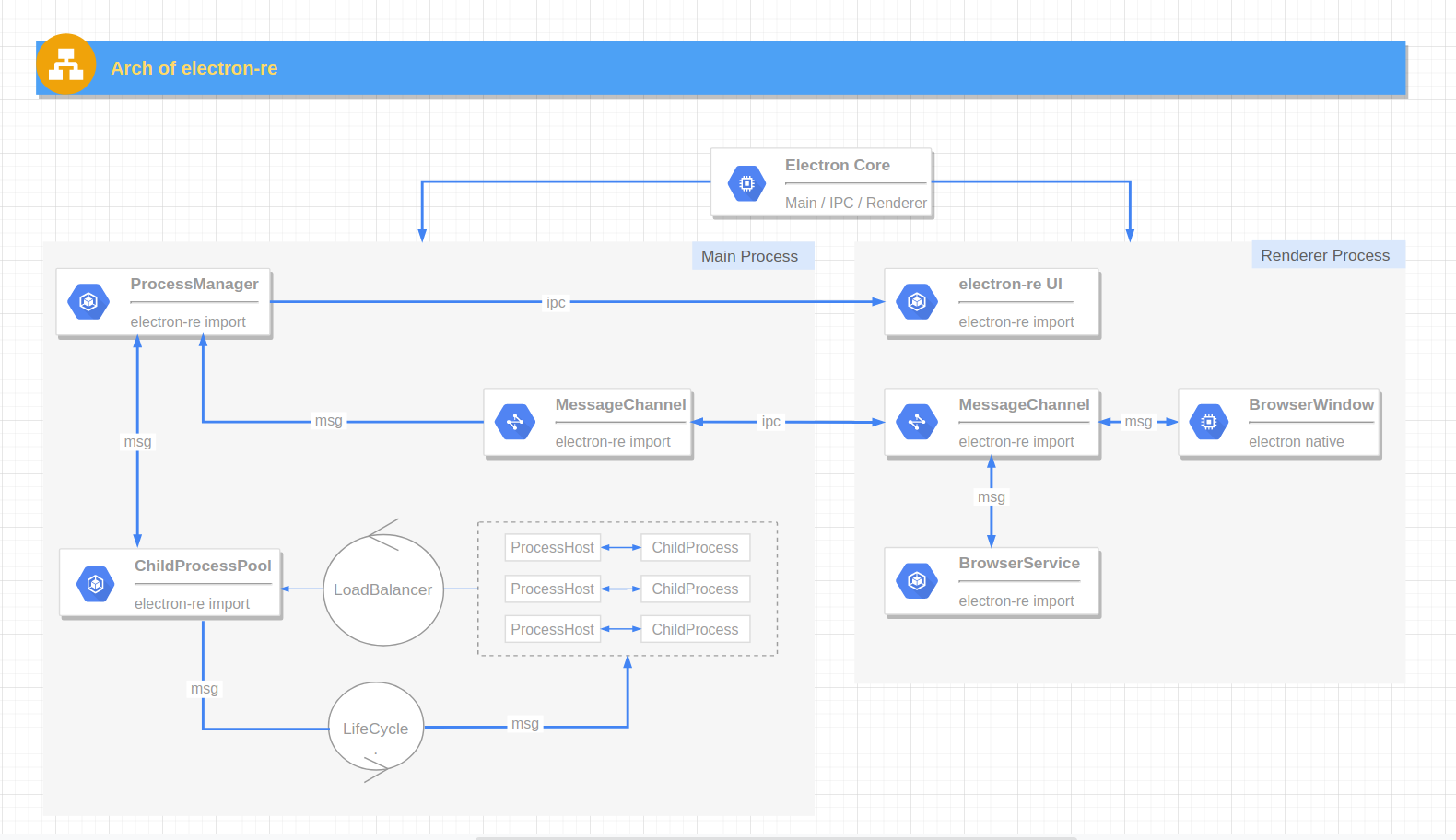
1. 關鍵流程
- 進程池創建進程時會初始化進程實例內的 ProcessHost 事務對象,進程實例向事務對象註冊多種任務監聽器。
- 用户向進程池發起單個任務調用請求,可傳入進程綁定的 ID 和指定的任務名。
- 判斷用户是否傳入 ID 參數指定使用某個進程執行任務,如果未指定 ID:
- 進程池判斷當前進程池進程數量是否已超過最大值,如果未超過則創建新進程,用此進程處理當前任務,並將進程放入進程池。
- 如果進程池進程數量已達最大值,則根據負載均衡算法選擇一個進程處理當前任務。
- 指定 ID 時:
- 通過用户傳入的 ID 參數找到對應進程,將任務分發給此進程執行。
- 如果未找到 ID 所對應的進程,則向用户拋出異常。
- 任務由進程池派發給目標進程後,ProcessHost 事務對象會根據該任務的任務名觸發子進程內的監聽器。
- 子進程內的監聽器函數可執行同步任務和異步任務,異步任務返回 Promise 對象,同步任務返回值。
- ProcessHost 事務對象的監聽器函數執行完畢後,會將任務結果返回給進程池,進程池再將結果通過異步回調函數返回給用户。
- 用户也可向進程池所有子進程發起個任務調用請求,最終將會通過 Promise 的返回所有子進程的任務執行結果。
2. 名詞解釋
- ProcessHost 事務中心:運行在子進程中,用於事件觸發以及和主進程通信。開發者在子進程執行文件中向其註冊多個具有特定任務名的任務事件,主進程會向某個子進程發送任務請求,並由事務中心調用指定的事件監聽器處理請求。
- LoadBalancer 負載均衡器:用於選擇一個進程處理任務,可根據不同的負載均衡算法實現不同的選擇策略。
- LifeCycle: 設計之初用於管控子進程的智能啟停,某個進程在長時間未被使用時進入休眠狀態,當有新任務到來時再喚醒進程。目前還有些難點需要解決,比如進程的喚醒和休眠不好實現,進程的使用情況不好統計,該功能暫時不可用。
三、進程池使用方式
1. 創建進程池
main.js
```js const { ChildProcessPool, LoadBalancer } = require('electron-re');
const processPool = new ChildProcessPool({ path: path.join(__dirname, 'child_process/child.js'), max: 4, strategy: LoadBalancer.ALGORITHM.POLLING, ); ```
child.js
```js const { ProcessHost } = require('electron-re');
ProcessHost .registry('test1', (params) => { console.log('test1'); return 1 + 1; }) .registry('test2', (params) => { console.log('test2'); return new Promise((resolve) => resolve(true)); }); ```
2. 向一個子進程發送任務請求
js
processPool.send('test1', { value: "test1"}).then((result) => {
console.log(result);
});
3. 向所有子進程發送任務請求
js
processPool.sendToAll('test1', { value: "test1"}).then((results) => {
console.log(results);
});
四、進程池實際使用場景
1. Electron 網頁代理工具中多進程的應用
1)基本代理原理:
2)單進程下客户端執行原理:
- 通過用户預先保存的服務器配置信息,使用 node.js 子進程來啟動 ss-local 可執行文件建立和 ss 服務器的連接來代理用户本地電腦的流量,每個子進程佔用一個 socket 端口。
- 其它支持 socks5 代理的 proxy 工具比如:瀏覽器上的 SwitchOmega 插件會和這個端口的 tcp 服務建立連接,將 tcp 流量加密後通過代理服務器轉發給我們需要訪問的目標服務器。
3)多進程下客户端執行原理:
以上描述的是客户端連接單個節點的工作模式,節點訂閲組中的負載均衡模式需要同時啟動多個子進程,每個子進程啟動 ss-local 執行文件佔用一個本地端口並連接到遠端一個服務器節點。
每個子進程啟動時選擇的端口是會變化的,因為某些端口可能已經被系統佔用,程序需要先選擇未被使用的端口。並且瀏覽器 proxy 工具也不可能同時連接到我們本地啟動的子進程上的多個 ss-local 服務上。因此需要一個佔用固定端口的中間節點接收 proxy 工具發出的連接請求,然後按照某種分發規則將 tcp 流量轉發到各個子進程的 ss-local 服務的端口上。
2. 多進程文件分片上傳 Electron 客户端
之前做過一個支持 SMB 協議多文件分片上傳的客户端,Node.js 端的上傳任務管理、IO 操作等都使用多進程實現過一版本,不過是在 gitlab 實驗分支自己搞得(逃)。
IV. 線程池
為了減小 CPU 密集型任務計算的系統開銷,Node.js 引入了新的特性:工作線程 worker_threads,其首次在 v10.5.0 作為實驗性功能出現。通過 worker_threads 可以在進程內創建多個線程,主線程與 worker 線程使用 parentPort 通信,worker 線程之間可通過 MessageChannel 直接通信。worker_threads 做為開發者使用線程的重要特性,在 v12.11.0 穩定版已經能正常在生產環境使用了。
但是線程的創建需要額外的 CPU 和內存資源,如果要多次使用一個線程的話,應該將其保存起來,當該線程完全不使用時需要及時關閉以減少內存佔用。想象我們在需要使用線程時直接創建,使用完後立刻銷燬,可能線程自身的創建和銷燬成本已經超過了使用線程本身節省下的資源成本。Node.js 內部雖然有使用線程池,但是對於開發者而言是完全透明不可見的,因此封裝一個能夠維護線程生命週期的線程池工具的重要性就體現了。
為了強化多異步任務的調度,線程池除了提供維護線程的能力,也提供維護任務隊列的能力。當發送請求給線程池讓其執行一個異步任務時,如果線程池內沒有空閒線程,那該任務就會被直接丟棄了,顯然這不是想要的效果。
因此可以考慮為線程池添加一個任務隊列的調度邏輯:當線程池沒有空閒線程時,將該任務放入待執行任務隊列 (FIFO),線程池在某個時機取出任務交由某個空閒線程執行,執行完成後觸發異步回調函數,將執行結果返回給請求調用方。但是線程池的任務隊列內的任務數量應該考慮限制到一個特殊值,防止線程池負載過大影響 Node.js 應用整體運行性能。
一、要點
「 對單一任務的控制重要,對單個線程的資源佔用無需關注 」
二、詳細設計

任務流轉過程
- 調用者可通過
StaticPool/StaticExcutor/DynamicPool/DynamicExcutor實例向線程池派發任務(以下有關鍵名詞説明),各種實例的之間最大的不同點就是參數動態化能力。 - 任務由線程池內部生成,生成後任務做為主要的流轉載體,一方面承載用户傳入的任務計算參數,另一方面記錄任務流轉過程中的狀態變化,比如:任務狀態、開始時間、結束時間、任務 ID、任務重試次數、任務是否支持重試、任務類型等。
- 任務生成後,首先判斷當前線程池的線程數是否已達上限,如果未達上限,則新建線程並將其放入線程存儲區,然後使用該線程直接執行當前任務。
- 如果線程池線程數超限,則判斷是否有未執行任務的空閒線程,拿到空閒線程後,使用該線程直接執行當前任務。
- 如果沒有空閒線程,則判斷當前等待任務隊列是否已滿,任務隊列已滿則拋出錯誤,第一時間讓調用者感知任務未執行成功。
- 如果任務隊列未滿的話,將該任務放入任務隊列,等待任務循環系統取出將其執行。
- 以上 4/5/6 步的三種情況下任務執行後,判斷該任務是否執行成功,成功時觸發成功的回調函數,Promise 狀態為 fullfilled。如果失敗,則判斷是否支持重試,支持重試的情況下,將該任務重試次數 + 1 後重新放入任務隊列尾部。任務不支持重試的情況下,直接失敗,並觸發失敗的異步回調函數,Promise 狀態為 rejected。
- 整個線程池生命週期中,存在一個任務循環系統,以一定的週期頻率從任務隊列首部獲取任務,並從線程存儲區域獲取空閒線程後使用該線程執行任務,該流程也符合第 7 步的描述。
- 任務循環系統除了取任務執行,如果線程池設置了任務超時時間的話,也會判斷正在執行中的任務是否超時,超時後會終止該線程的所有運行中的代碼。
模塊説明
- StaticPool
- 定義:靜態線程池,可使用固定的
execFunction/execString/execFile執行參數來啟動工作線程,執行參數在進程池創建後不能更改。 - 進程池創建之後除了執行參數不可變外,其它參數比如:任務超時時間、任務重試次數、線程池任務輪詢間隔時間、最大任務數、最大線程數、是否懶創建線程等都可以通過 API 隨時更改。
- StaticExcutor
- 定義:靜態線程池的執行器實例,繼承所屬線程池的固定執行參數
execFunction/execString/execFile且不可更改。 - 執行器實例創建之後除了執行參數不可變外,其它參數比如:任務超時時間、任務重試次數、線程池任務輪詢間隔時間、最大任務數、最大線程數、是否懶創建線程等都可以通過 API 隨時更改。
- 靜態線程池的各個執行器實例的參數設置互不影響,參數默認繼承於所屬線程池,參數在執行器上更改後具有比所屬線程池同名參數更高的優先級。
- DynamicPool
- 定義:動態線程池,無需使用
execFunction/execString/execFile執行參數即可創建線程池。執行參數在調用exec()方法時動態傳入,因此執行參數可能不固定。 - 線程池創建之後執行參數默認為
null,其它參數比如:任務超時時間、任務重試次數、線程池任務輪詢間隔時間、最大任務數、最大線程數、是否懶創建線程等都可以通過 API 隨時更改。 - DynamicExcutor
- 定義:動態線程池的執行器實例,繼承所屬線程池的其它參數,執行參數為
null。 - 執行器實例創建之後,其它參數比如:任務超時時間、任務重試次數、線程池任務輪詢間隔時間、最大任務數、最大線程數、是否懶創建線程等都可以通過 API 隨時更改。
- 動態線程池的各個執行器實例的參數設置互不影響,參數默認繼承於所屬線程池,參數在執行器上更改後具有比所屬線程池同名參數更高的優先級。
- 動態執行器實例在執行任務時需要傳入執行參數
execFunction/execString/execFile,因此執行參數可能不固定。 - ThreadGenerator
- 定義:線程創建的工廠方法,會進行參數校驗。
- Thread
- 定義:線程實例,內部簡單封裝了
worker_threadsAPI。 - TaskGenerator
- 定義:任務創建的工廠方法,會進行參數校驗。
- Task
- 定義:單個任務,記錄了任務執行狀態、任務開始結束時間、任務重試次數、任務攜帶參數等。
- TaskQueue
- 定義:任務隊列,在數組中存放任務,以先入先出方式 (FIFO) 向線程池提供任務,使用 Map 來存儲 taskId 和 task 之間的映射關係。
- Task Loop
- 任務循環,每個循環的默認時間間隔為 2S,每次循環中會處理超時任務、將新任務派發給空閒線程等。
三、線程池使用方式
1. 創建靜態線程池
main.js
js
const { StaticThreadPool } = require('electron-re');
const threadPool = new StaticThreadPool({
execPath: path.join(__dirname, './worker_threads/worker.js'),
lazyLoad: true, // 懶加載
maxThreads: 24, // 最大線程數
maxTasks: 48, // 最大任務數
taskRetry: 1, // 任務重試次數
taskLoopTime: 1e3, // 任務輪詢時間
});
const executor = threadPool.createExecutor();
worker.js
```js const fibonaccis = (n) => { if (n < 2) { return n; } return fibonaccis(n - 1) + fibonaccis(n - 2); };
module.exports = (value) => { return fibonaccis(value); } ```
2. 使用靜態線程池發送任務請求
```js threadPool.exec(15).then((res) => { console.log(+res.data === 610) });
executor .setTaskRetry(2) // 不影響 pool 的全局設置 .setTaskTimeout(2e3) // 不影響 pool 的全局設置 .exec(15).then((res) => { console.log(+res.data === 610) }); ```
3. 動態線程池和動態執行器
```js const { DynamicThreadPool } = require('electron-re'); const threadPool = new DynamicThreadPool({ maxThreads: 24, // 最大線程數 maxTasks: 48, // 最大任務數 taskRetry: 1, // 任務重試次數 });
const executor = threadPool.createExecutor({ execFunction: (value) => { return 'dynamic:' + value; }, });
threadPool.exec('test', {
execString: module.exports = (value) => { return 'dynamic:' + value; };,
});
executor.exec('test');
executor
.setExecPath('/path/to/exec-file.js')
.exec('test');
```
四、線程池實際使用場景
暫未在項目中實際使用,可考慮在前端圖片像素處理、音視頻轉碼處理等 CPU 密集性任務中進行實踐。
V. 結尾
最開始 項目 做為 Electron 應用開發的一個工具集提供了 BrowserService / ChildProcessPool / 簡易進程監控 UI / 進程間通信 等功能,線程池的加入其實是當初沒有計劃的,而且線程池本身是獨立的,不依賴 electron-re 中其它模塊功能,之後應該會被獨立出去。
進程池和線程池的實現方案上還需完善。
比如進程池未支持子進程空閒時自動退出以解除資源佔用,當時做了另一版監聽 ProcessHost 的任務執行情況來讓子進程空閒時休眠,想通過此方式節省資源佔用。不過由於沒有 node.js API 級別的支持以分辨子進程空閒的情況,並且子進程的休眠 / 喚醒功能比較雞肋 (有嘗試通過向子進程發送 SIGSTOP/SIGCONT 信號實現),最終這個特性被廢除了。
後面可以考慮支持 CPU/Memory 的負載均衡算法,目前已經通過項目中的 ProcessManager 模塊來實現資源佔用情況採集了。
線程池方面相對的可用度還是較高,提供了 pool/excutor 兩個層級的調用管理,支持鏈式調用,在一些需要提升數據傳輸性能的場景支持 transferList 方式避免數據克隆。相對於其它開源 Node 線程池方案,着重對任務隊列功能進行了加強,支持任務重試、任務超時等功能。