爆肝整理5000字!HTAP的關鍵技術有哪些?| StoneDB學術分享會#3
在最新一屆國際資料庫頂級會議 ACM SIGMOD 2022 上,來自清華大學的李國良和張超兩位老師發表了一篇論文:《HTAP Database: What is New and What is Next》,並做了 《HTAP Database:A Tutorial》 的專項報告。這幾期學術分享會的文章,StoneDB將系統地梳理一下兩位老師的報告,帶讀者瞭解 HTAP 的發展現狀和未來趨勢。
在深度乾貨!一篇Paper帶您讀懂HTAP這期分享中我們已經把HTAP產生的背景和現有的HTAP資料庫及其技術棧做了一個簡單的介紹,這一期,我們將著重講一講報告中對HTAP關鍵技術的解讀。
在正式開始前,先給上期簡單收個尾,報告中提到 HTAP 資料庫除了以下四種:
- Primary Row Store + InMemory Column Store
- Distributed Row Store + Column Store Replica
- Disk Row Store + Distributed Column Store
- Primary Column Store + Delta Row Store
還補充了3種,感興趣的讀者可以自行了解:
- Row-based HTAP systems:如 Hyper(Row)、BatchDB等
- Column-based HTAP systems:如 Caldera、RateupDB等
- Spark-based HTAP systems:如 Splice Machine、Wildfire等
下面進入正文,本篇報告中主要介紹了HTAP的五大類關鍵技術,分別是:
- Transaction Processing(事務處理技術)
- Analytical Processing(查詢分析技術)
- Data Synchronization(資料同步技術)
- Query Optimization(查詢優化技術)
- Resource Scheduling(資源排程技術)
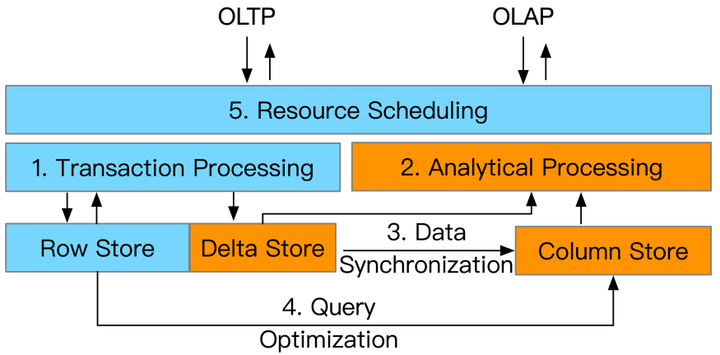
Overview of HTAP Techniques
這些關鍵技術被最先進的HTAP資料庫採用。然而,它們在各種指標上各有利弊,例如效率、可擴充套件性和資料新鮮度。
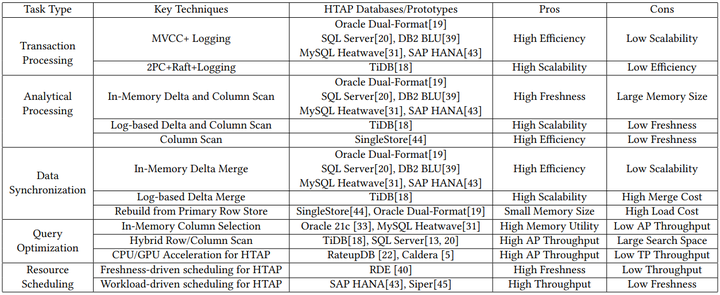
An Overview of HTAP Techniques

一、事務處理技術(OLTP)
HTAP資料庫中的OLTP工作負載是通過行儲存處理的,但不同的架構會導致不同的TP技術。它主要由兩種型別組成。
1使用記憶體增量更新的單機事務處理
Standalone Transaction Processing with In-Memory Delta Update
關鍵技術點:
- 通過MVCC協議進行單機事務處理
- 通過記憶體增量更新進行insert/delete/update操作
相關資料庫:Oracle、SQL Server、SAP HANA 和 StoneDB 等。
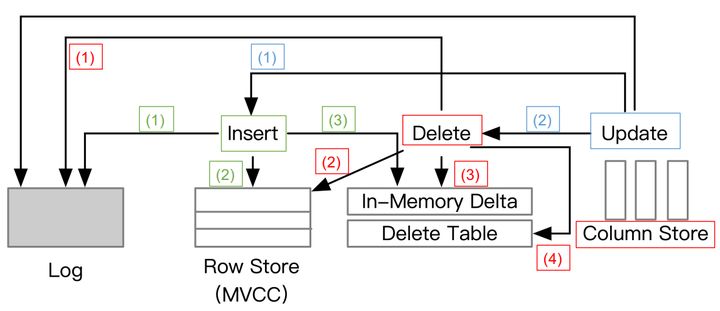
Standalone TP for insert/delete/update operations
上面這張圖介紹了單機事務處理執行insert/delete/operations操作的一個邏輯過程,總體上是藉助MVCC+logging,它依賴於MVCC協議和日誌記錄技術來處理事務。具體來說,每個插入首先寫入日誌和行儲存,然後附加到記憶體中的增量儲存。更新建立具有新生命週期的行的新版本,即開始時間戳和結束時間戳,即舊版本在刪除點陣圖中被標記為刪除行。因此,事務處理是高效的,因為 DML 操作是在記憶體中執行的。請注意,某些方法可能會將資料寫入行儲存 或增量行儲存 ,並且它們可能僅在事務提交時寫入日誌。
一般有三種方式來實現記憶體增量儲存,分別是:Heaptable(堆表)、Index organized table(索引組織表) 和 L1 cache(一級快取),具體區別如下表:
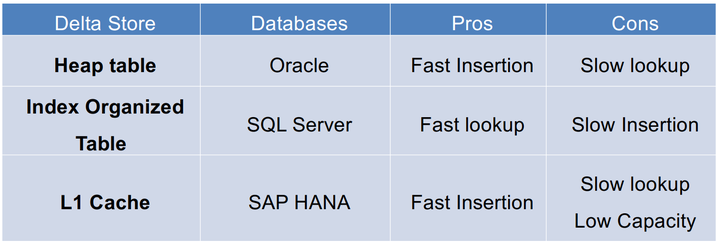
Three implementations for an in-memory delta store
三者主要的區別在於插入(insertion)速度、查詢(lookup)速度和容量(capacity)大小上。
2使用日誌回放的分散式事務處理
Distributed Transaction Processing with Log Replay
關鍵技術點:
- Two-Phase Commit(2PC)`+Paxos 用於分散式TP和資料複製
- 使用Log replay(日誌回放)更新行儲存和列儲存
相關資料庫:F1 Lightning
注:這裡有稍有不同的分散式TP方案,就是採用主從複製(Master-slave replication)的方式實現HTAP,比如 Singlestore。
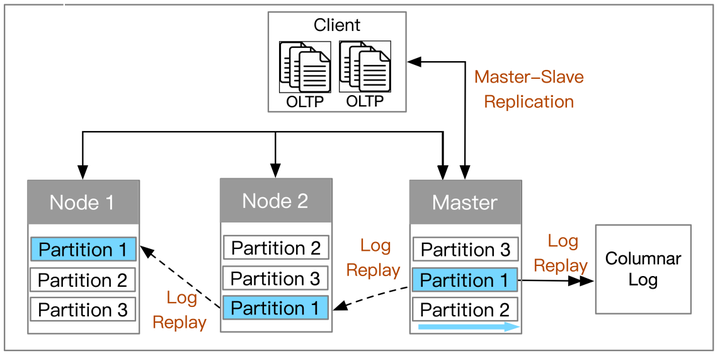
Master node handles the transactions, then replicate the logs to slave nodes
如上圖所示,這種主從複製的方式下,主節點處理事務,然後將日誌複製到從節點再做分析。
另外就是通過2PC+Raft+logging,它依賴於分散式架構。
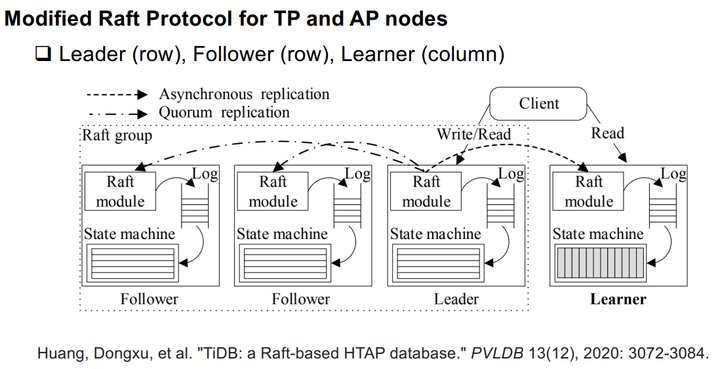
Modified Raft Protocol for TP and AP nodes
它通過分散式事務處理提供了高可擴充套件性。ACID事務在分散式節點上使用兩階段提交 (2PC) 協議、基於Raft的共識演算法和預寫日誌 (WAL) 技術進行處理。特別是leader節點接收到SQL引擎的請求,然後在本地追加日誌,非同步傳送日誌給follower節點。如果大多數節點(即法定人數)成功附加日誌,則領導者提交請求並在本地應用它。與第一種記憶體增量更新的方式相比,這種基於日誌的方式由於分散式事務處理效率較低。
3對比
最後我們將提到事務處理技術做一個對比:

Comparisons of TP techniques in HTAP Databases

二、查詢分析技術(OLAP)
對於HTAP資料庫,OLAP負載使用面向列的技術執行,例如壓縮資料上的聚合和單指令多資料 (SIMD) 指令。這裡介紹兩大型別和三種方式:
1記憶體增量遍歷 + 單機列掃描
Standalone Columnar Scan with In-Memory Delta Traversing
關鍵技術點:
- 單指令多資料(SIMD),向量化處理
- 記憶體增量遍歷(In-Memory Delta Traversing) 相關資料庫:Oracle、SQL Server
舉幾個例子:
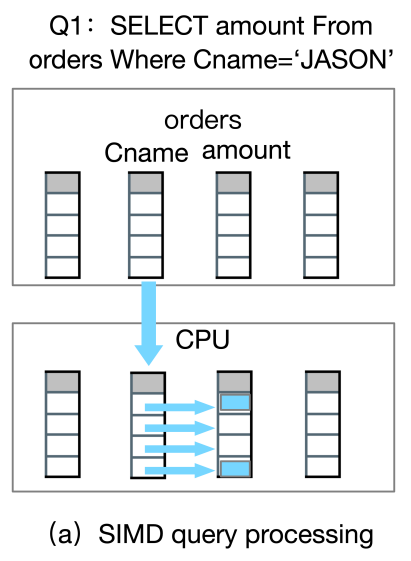
在(a)裡,我們查詢訂單表中名稱為JASON的花了多少錢,那麼基於SIMD的查詢方式,是可以通過CPU把資料Load到暫存器中,只需要一個CPU執行的週期,就可以同時去掃描查到滿足條件的兩個資料。

如果基於傳統的火山模型,用的是一種迭代模型,就需要訪問四行資料,而基於這種列存的方式,只要訪問一次就可以得到結果。
同樣的,還可以通過這種方式做基於Bloom Filter的向量化連線,也可以提高查詢分析的效率。
在增量表中獲取可見值,並跳過刪除表中的陳舊資料
除此之外,我們在做列存掃描的同時要去掃描一些可見的增量資料來實現實時資料的分析,也去掃描刪除表中是否有過期的資料,最終達到資料是新鮮的。
2日誌檔案掃描 + 分散式列掃描
Distributed Columnar Scan with Log File Scanning
關鍵技術點:
- 列段上的分散式查詢處理
- 基於磁碟的日誌檔案歸併與掃描 相關資料庫:F1 Lightning
Distributed Columnar Scan

Samwel, Bart, et al. "F1 query: Declarative querying at scale."PVLDB 11(12) , 2018: 1835-1848.
如上圖所示的分散式列掃描,傳統方法就是基於多個Worker來做併發的多節點下進行運算元下推,掃描之後,在上層做一些聚集、HASH、排序等一些操作。
Log File Scanning
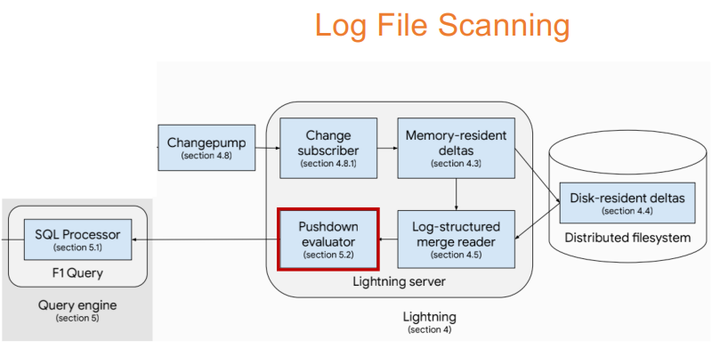
Yang, Jiacheng, et al. "F1 Lightning: HTAP as a Service." PVLDB 13(12), 2020: 3313-3325.
與分散式列掃描同時進行的還有日誌檔案掃描,我們還要基於列儲存來做運算元下推來查到當前增量儲存中最新的資料,再進行資料合併。上圖裡的F1 Lighting就可以支援把10個小時的資料合併到Delta中。
3技術總結
記憶體中增量和列掃描
將記憶體中的增量和列資料一起掃描,因為增量儲存可能包括尚未合併到列儲存的更新記錄。由於它已經掃描了最近可見的delta tuples in記憶體,因此OLAP的資料新鮮度很高。
基於日誌的增量和列掃描
將基於日誌的增量資料和列資料一起掃描以獲取傳入查詢。與第一種類似,第二種使用列儲存掃描最新的增量用於OLAP。但是,由於讀取可能尚未合併的delta檔案,這樣的過程更加昂貴。因此,資料新鮮度較低,因為傳送和合並delta檔案的高延遲。
列掃描
只掃描列資料以獲得高效率,因為沒有讀取任何增量資料的開銷。但是,當資料在行儲存中經常更新時,這種技術會導致新鮮度低。
4對比

Comparisons of AP techniques in HTAP Databases
對於第一種單機列掃描+記憶體增量遍歷來說,優點是資料新鮮度較高,缺點是需要比較多的記憶體空間。對第二種分散式列掃描+日誌檔案掃描來說,優點是擴充套件性高,缺點是效率比較低。

三、資料同步技術(DS)
由於在查詢時讀取增量資料的成本很高,因此需要定期將增量資料合併到主列儲存中。這個時候,資料同步(Data Synchronization)技術,就非常重要了,也是分為兩大型別。
1型別一:記憶體增量合併
關鍵技術:
- 基於閾值的合併(Threshold-based merging)
- 兩階段資料遷移(Two-phase data migration)
- 基於字典的遷移(Dictionary-based migration)
相關資料庫:Oracle、SQL Server、SAP HANA
Threshold-based merging
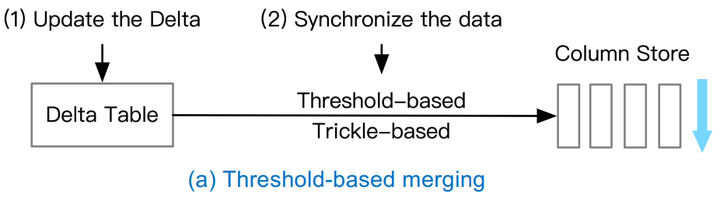
舉個例子,如果閾值達到列儲存90%的容量時,我們就把Delta Table中的資料合併到Column Store當中,當然這種方式有個缺點——如果閾值設定的太大可能會導致AP的效能發生抖動,所以看到圖裡我們加了一個Trick-based,最好是定小量按期地去合併,做一個權衡。
Two-phase data migration

兩階段資料的遷移,可以拿SQL Server舉例,如圖所示:
- 第一階段:遷移準備
- 第(1)步先插入RID去把需要隱藏的資料寫入到刪除表當中;
- 第(2)步把這些資料分配RID後生成Delta Colunm Store;
- 第二階段:遷移操作
- 第(3)步,把剛剛插入進去的RID刪除;
- 第(4)步,最後真正把Delta中相關的資料刪除,最後才把生成的增量列存合併到主列存中,達到了資料遷移的效果。
Dictionary-based migration
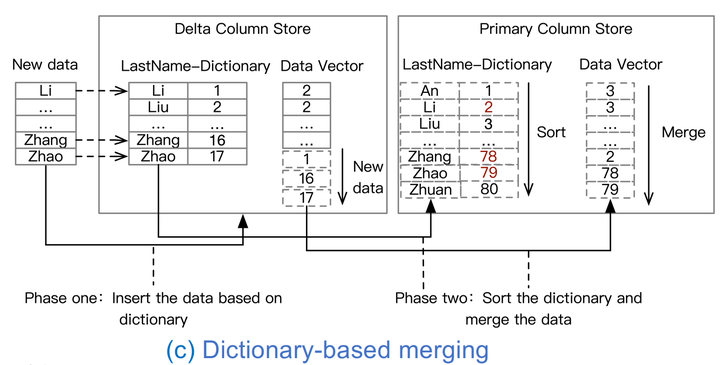
第三種基於字典的遷移,SAP HANA就是採用這種方式。如圖所示,它第一階段主要是針對每一列的資料做一個本地字典的方式對映過去增加對應的資料向量,第二階段,才會把這個字典加入到全域性的字典,做一個全域性的排序,最後合併到資料向量當中。
2型別二:基於日誌的增量合併
關鍵技術:LSM-tree 和 B-tree
相關資料庫:F1 Lighting
這種型別分兩層:
- Memory-resident deltas(駐留記憶體的增量),主要是row-wise
- Disk-resident deltas(駐留磁碟的增量),主要是column-wise

Log-based delta merge
如圖所示,第一階段會把小檔案、小delta按它到來的順序合併到增量的檔案當中,第二階段會通過查詢B+樹來做一個有序合併,最終讓合併的Chunk是有序的。這主要涉及解決基於多版本的一些Log怎麼去做合併和摺疊,其中B+樹主要的作用就是在有序合併時去加速資料查詢的過程。
3技術總結
可歸類為有3種資料合併技術。分別是:
- 記憶體中增量合併;
- 基於磁碟的增量合併;
- 從主行儲存重建。
第一個類別定期將新插入的記憶體中增量資料合併到主列儲存。引入了幾種技術來優化合並過程,包括兩階段基於事務的資料遷移、字典編碼排序合併和基於閾值的變化傳播。
第二類 將基於磁碟的增量檔案合併到主列儲存。為了加快合併過程,增量資料可以通過B+樹進行索引,因此可以通過鍵查詢有效地定位增量項。
第三類從主行儲存重建記憶體列儲存。這對於增量更新超過某個閾值的情況很典型,因此重建列儲存比合並這些具有大記憶體佔用的更新更有效。
4對比

Comparisons of DS techniques in HTAP Databases
總體來看,基於記憶體的增量合併效率比較高,擴充套件性差點兒;基於日誌的合併,擴充套件性好,但是多重合並的代價會比較高。

四、查詢優化技術
HTAP中查詢優化技術主要涉及三個維度,包括:

Query Optimization in HTAP databases
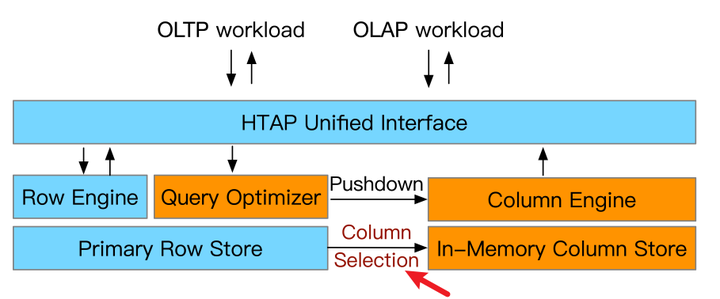
1In-Memory Column Selection
- 解決的問題:要從行儲存區中選擇哪些列進入記憶體呢?簡單的做法是全部選擇進去,但那樣儲存和更新的代價會很高,所以一般是基於歷史的統計資訊和現有記憶體的預算來做權衡選擇。
- 解決方式:有兩種,第一種是熱力圖(Heatmap),第二種是整數規劃(Integer programming)
基於Heatmap,比如Oracle
通過訪問頻度來管理列存並進行熱力圖的製作。

Oracle 21c. Automating Management of In-Memory Objects., 2021.
如圖所示,首先根據最下方持久化行存(Persistent Storage)來選定一些候選列集(Candidate Columns),通過記錄候選集的訪問頻度。有些列就會變為Hot Columns,那麼就可以把最新的資料Load進去(圖中左下方的Populating)來達到加速查詢的效果;慢慢地也有一些列會變為Cold Columns,那麼就把這些冷列進行壓縮(Compressed Columnar data),然後最後排除(圖中右下方的Evicating)到記憶體當中,再選取其他被高頻訪問的列重複進行。
基於Integer programming,比如Hyrise
Integer programming for 0/1 Knapsack problem,第一種基於熱力圖的方式完全沒有考慮選擇列的代價,那麼第二種就是把代價函式(cost-based optimization problem)考慮進去,再從二級儲存中選擇列。

Boissier, Martin, et al. "Hybrid data layouts for tiered HTAP databases with paretooptimal data placements." ICDE, 2018.
這個目標函式 就是要去優化所有的查詢代價函式 ,而每個查詢代價函式要去衡量所選擇列的代價。總目標是最小化這個代價,要小於這個最大的 預算。(這裡不展開講了,感興趣可以閱讀這篇論文,也比較經典)
2Hybrid Row and Column Scan
- 解決的問題:記憶體中選擇好列之後,如何利用混合行/列掃描加速查詢呢?這個比較前沿了,像Google的AlloyDB也支援這個特性。
- 解決方式:基於規則的計劃選擇(Rule-based)或者基於代價(Cost-based)的計劃選擇。主要決定查詢優化器要把哪些運算元下推到列存引擎當中。

Rule-based Optimization(RBO)
先定義一些掃描的規則,比如先看列掃描,再看行掃描。相關資料庫:Oracle、SQL server。
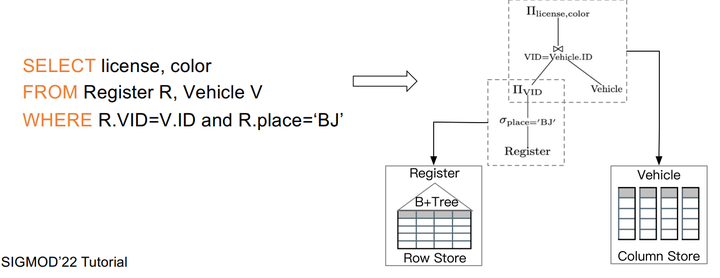
舉個例子,上圖中我們查詢一些北京車子註冊的證書和顏色,在這種規則下就可以生成一個邏輯計劃樹,在這個邏輯計劃樹裡,我們先去查詢底層表到底是行存還是列存,如果是列存,就做列存的方式處理,如果是行存就做一個B+樹的掃描。最後合併做一個連線再返回最終結果。
Cost-based Optimization(CBO)
基於代價的方式,解決的方式是先去對比列存掃描和行存/索引掃描的代價分別是多少,然後再決定查詢運算元在哪裡執行。

Compare the cost of row/index scan with the cost of columnar scan
3CPU/GPU Acceleration for HTAP
這個基於硬體去做HTAP的加速。比如,基於CPU/GPU異構處理器的方式進行HTAP的處理。相關資料庫:RateupDB、Caldera。
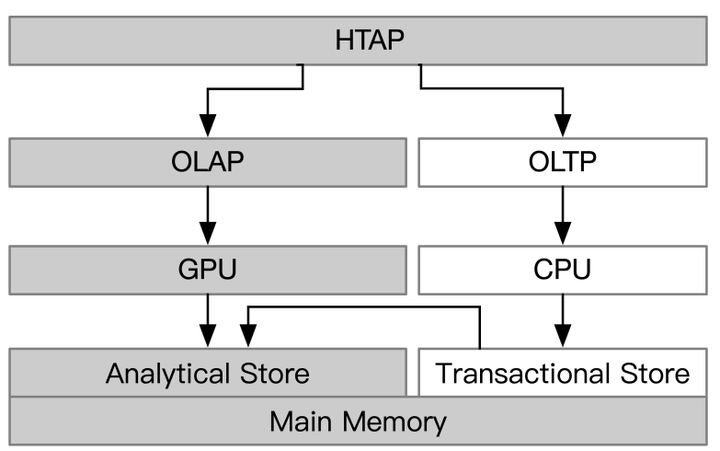
CPU/GPU processors for HTAP
- Task-parallel nature of CPUs for handling OLTP
- CPU任務並行的特性可以用來處理OLTP
- Data-parallel nature of GPUs for handling OLAP
- GPU資料並行的特性可以用來處理OLAP
涉及到一些平行計算的知識,感興趣可以瞭解瞭解~
4技術總結
主要涉及三大技術:
- HTAP的列選擇;
- 混合行/列掃描;
- HTAP 的 CPU/GPU加速。
第一種型別依靠歷史工作負載和統計資料來選擇從主儲存中提取的頻繁訪問的列到記憶體中。因此,可以將查詢下推到記憶體中的列儲存以進行加速。缺點是可能沒有選擇新查詢的列,導致基於行的查詢處理。現有方法依靠歷史工作負載的訪問模式來載入熱資料並驅逐冷資料。
第二種型別利用混合行/列掃描來加速查詢使用這些技術,可以分解複雜的查詢以在行儲存或列儲存上執行,然後組合結果。這對於可以使用基於行的索引掃描和完整的基於列的掃描執行的 SPJ 查詢來說是典型的。我們引入了基於成本的方法來選擇混合行/列訪問路徑。
第三種技術利用異構CPU/GPU架構來加速HTAP工作負載。這些技術分別利用CPU的任務並行性和GPU的資料並行性來處理OLTP和OLAP。然而,這些技術有利於高OLAP吞吐量,同時具有低OLTP吞吐量。
5對比

Query Optimization in HTAP databases

五、資源排程技術
對於 HTAP 資料庫,資源排程是指為 OLTP 和OLAP 工作負載分配資源。當前可以動態控制OLTP 和 OLAP 工作負載的執行模式,以更好地利用資源。

Resource Scheduling
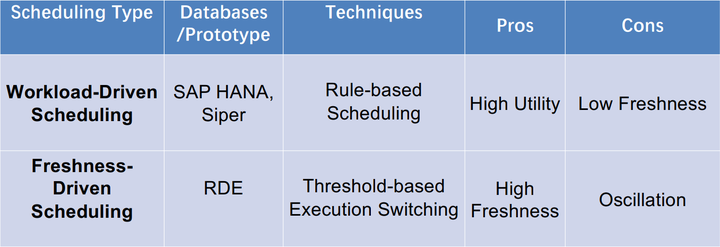
1基於工作負載驅動的排程
Workload-driven Scheduling for HTAP,就是根據HTAP工作負載的執行效能進行動態的排程,執行緒和記憶體這些根據OLTP和OLAP的效能需求動態分配資源。相關資料庫: SAP HANA。
- Assign more threads to OLTP or OLAP

Psaroudakis, Iraklis, et al. "Task scheduling for highly concurrent analytical and transactional main-memory workloads." In ADMS, 2013.
舉個栗子,第一種方式會分配更多的執行緒給OLTP或者OLAP,怎麼分配呢?會在Scheduler裡配置一個Watch-dog監測器,來監測當前的Worker,有一些被阻塞的Worker就分配多一些Thread,有一些比較活躍的的,就讓它繼續執行。
- Isolate the workload execution and assign more cache for OLAP
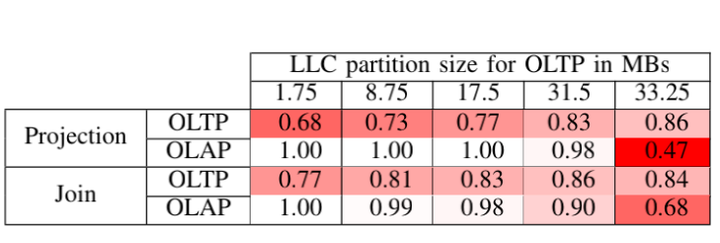
Sirin, Utku, Sandhya Dwarkadas, and Anastasia Ailamaki. "Performance Characterization of HTAP Workloads." In ICDE, 2021.
如表所示,在第三層Cache當中進行一些排程,通過實驗可以得知增加OLTP儲存資源時,OLAP的顏色是會變深的,這意味著影響越嚴重,所以還是建議在第三層儘量給OLAP多分配一些資源。
2基於新鮮度驅動的排程
Freshness-driven Scheduling for HTAP
- Switches the execution modes {S1, S2, S3}
- Default S2; When freshness < threshold, jump to S1 or S3

Raza, Aunn, et al. "Adaptive HTAP through elastic resource scheduling." In SIGMOD, 2020.
3技術總結
排程技術有兩種型別,工作負載驅動的方法和新鮮度驅動的方法。前者根據執行工作負載的效能調整OLTP和OLAP任務的並行度。例如,當CPU資源被OLAP執行緒飽和時,任務排程器可以在增大OLTP執行緒的同時降低OLAP的並行度。後一個切換了OLTP和OLAP的資源分配和資料交換的執行模式。例如,排程程式單獨控制OLTP和OLAP的執行以實現高吞吐量,然後定期同步資料。一旦資料新鮮度變低,它就會切換到共享 CPU、記憶體和資料的執行模式。其他與 HTAP 相關的技術,還有新的 HTAP 索引技術和橫向擴充套件技術。
4對比
Resource Scheduling in HTAP databases
第一種優點是比較容易實現,但是新鮮度較低;第二種方式優點是新鮮度高,但來回切換容易導致系統震盪。

六、其他相關的HTAP技術
這裡不展開介紹了,感興趣可以看看相關的Paper。
1Multi-Versioned Indexes for HTAP
- Parallel Binary Tree (P-Tree)
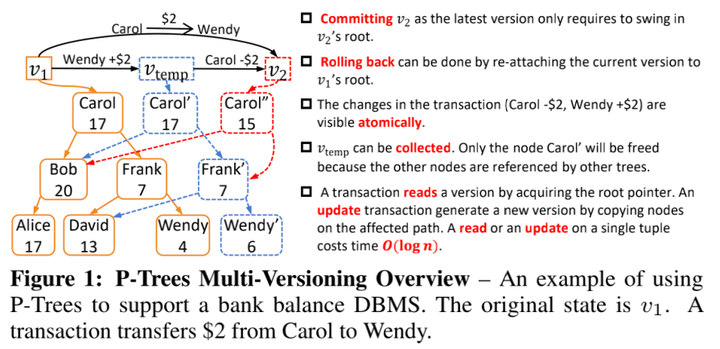
Sun, Yihan, et al. "On supporting efficient snapshot isolation for hybrid workloads with multiversioned indexes." PVLDB 13(2), 2019.
- Multi-Version Partitioned B-Tree (MV-PBT)

Riegger, Christian, et al. "MV-PBT: multi-version indexing for large datasets and HTAP workloads." In EDBT, 2020.
2Adaptive Data Organization for HTAP
- H2O [Alagiannis et al, SIGMOD 2014], Casper [Athanassoulis et al, VLDB 2019]
- Peloton [Arulraj et al, SIGMOD 2016], Proteus [Abebe et al, SIGMOD 2022]
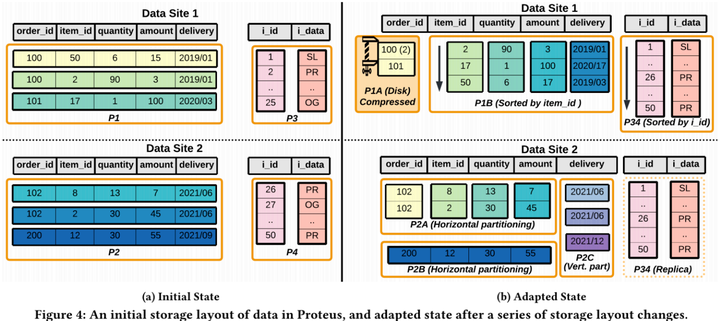
Abebe, Michael, Horatiu Lazu, and Khuzaima Daudjee. Proteus: Autonomous Adaptive Storage for Mixed Workloads. In SIGMOD, 2022.

HTAP的基準測試
下一期我們將介紹針對HTAP基準測試的相關進展,在我們的第二期學術分享會里,也介紹過來自慕尼黑工業大學(TMU)資料庫組的研究,感興趣可以前往檢視,這篇文章只是其中一種基準測試的方法,想了解還有哪些方法麼?歡迎關注StoneDB公眾號,我下期見~
StoneDB 已經正式開源,歡迎關注我們 http://github.com/stoneatom/stonedb

官網:http://stonedb.io/
Github: http://github.com/stoneatom/stonedb
Slack: http://stonedb.slack.com/ssb/redirect#/shared-invite/email
- 爆肝整理5000字!HTAP的關鍵技術有哪些?| StoneDB學術分享會#3
- 爆肝整理5000字!HTAP的關鍵技術有哪些?| StoneDB學術分享會#3
- 解讀《Benchmarking Hybrid OLTP&OLAP Database Systems》| StoneDB學術分享會
- 深度乾貨!一篇 Paper 帶您讀懂 HTAP | StoneDB 學術分享會第①期
- StoneDB 讀、寫操作的執行過程
- StoneDB 宣佈開源,一體化實時 HTAP 架構為何是當前最優解
- 什麼是真正的HTAP?(一)背景篇
- 什麼是真正的HTAP?(一)背景篇
- 一體化實時HTAP資料庫StoneDB,如何替換MySQL並實現近百倍分析效能的提升
- StoneDB 為國產資料庫添磚加瓦,基於 MySQL 的一體化實時 HTAP 資料庫正式開源!