得物供應鏈複雜業務實時數倉建設之路
1 背景
得物供應鏈業務是紛繁複雜的,我們既有 JIT 的現貨模式中間夾著這大量的倉庫作業環節,又有到倉的寄售,品牌業務,有非常複雜的逆向鏈路。在這麼複雜的業務背後,我們需要精細化關注人貨場車的效率和成本,每一單的及時履約情況,要做到這一點我們需要各粒度和維度的資料來支撐我們的精細化管理。
1.1 業務早期
業務早期,業務反饋我們後臺管理系統某些報表查詢慢。查詢程式碼可知,如下圖:

這種現象一般表現為:
-
大表 JOIN,rdbms 不擅長做資料聚合,查詢響應慢,調優困難;
-
多表關聯,索引優化,子查詢優化,加劇了複雜度,大量索引,讀庫磁碟空間膨脹過快;
-
資料量大,多維分析困難,跨域取數,自助拉到實時資料困難等。
一方面原因是系統設計之初,我們主要關注業務流程功能設計,事務型業務流程資料建模,對於未來核心指標的落地,特別是關鍵實時指標落地在業務快速增長的情況下如何做到非常好的支撐。mysql 在此方面越來越捉襟見肘。
另外一方面原因是 mysql 這種 oltp 資料庫是無法滿足實時資料分析需求的,我們需要探索一套實時資料架構,拉通我們的履約,倉儲,運配等各域的資料,做有效串聯,因此我們開始了我們的實時資料架構探索,下圖是我們一些思考。
附:資料視角的架構設計也是系統架構設計的重要組成部分。
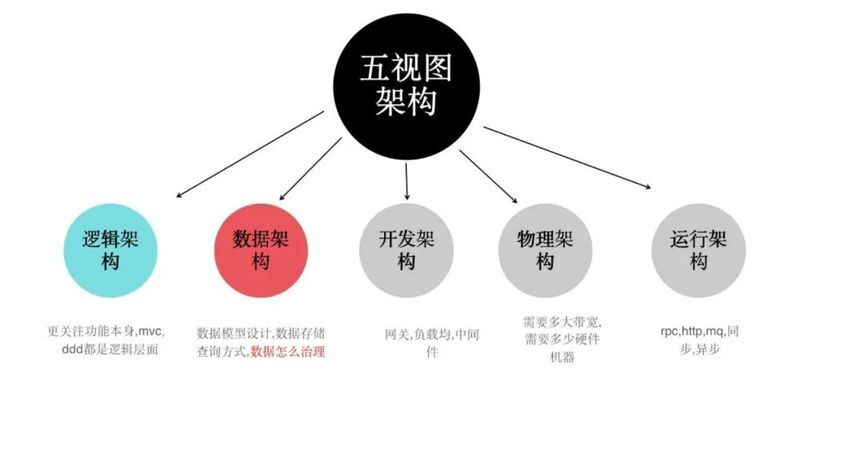
2 架構演變
2.1 原始階段
2.1.1 通過 Adb(AnalyticDB for MySQL)完成實時 join
通過阿里雲 DTS 同步直接將業務庫單表實時同步到 Adb,通過 Adb 強大的 join 能力和完全相容 mysql 語法,可以執行任意 sql,對於單表大資料量場景或者單表和一些簡單維表的 join 場景表現還是不錯的,但是在業務複雜,複雜的 sql rt 很難滿足要求,即使 rt 滿足要求,單個 sql 所消耗的記憶體,cpu 也不盡人意,能支撐的併發量很有限。
2.1.2 通過 Otter 完成大寬表的建設

基於 Canal 開源產品,獲取資料庫增量日誌資料並下發,下游消費增量資料直接生成大寬表,但是寬表還是寫入 mysql 資料庫,實現單表查詢,單表查詢速度顯著提升,無 olap 資料庫的常見做法,通過寬表減少 join 帶來的效能消耗。
但是存在以下幾個問題:
-
雖然 otter 有不錯的封裝,通過資料路由能做一些簡單的資料拼接,但在除錯上線複雜度上依然有不小的複雜度;
-
otter 偽裝 mysql 從庫同時要去做 etl 邏輯,把 cdc 乾的活和實時 ETL 的活同時幹了,耦合度較高。
2.2 實時架構 1.0
2.2.1 flink+kafka+ClickHouse
在上述調研嘗試後都沒有解決根本的問題,我們開始把目標建立標準的實時數倉的思路上來,在 20 年 olap 沒有太多的可選項,我們把目標放在 clickhouse 上。

-
為了保證順序 append 每次寫入都會生成一個 part 檔案,滿足一定條件後臺定時合併。
-
非常弱的 update delete,不能保證原子性和實時性。* clickhouse 只適合資料量大,業務模型簡單,更新場景少的場景。
-
存算不分離,複雜查詢影響 clickhouse 寫入。
因為 clickhouse 的這些特性,尤其是不支援 upsert 的情況下,我們通常需要提前把大寬表的資料提前在 flink 聚合好,並且供應鏈資料生命週期長,作業流程也長如:
-
貨物的生命週期較短時長為一週,長週期時長超過 1 個月;
-
庫內環節異常的多,從賣家發貨到收貨、分揀、質檢、拍照、鑑別、防偽、複查、打包、出庫、買家簽收等十幾個甚至更多的環節,一張以商品實物 id 為主鍵的大寬表,需要 join 幾十張業務表 ;
-
供應鏈系統早期設計沒有每張表都會冗餘唯一單號(入庫單,作業單,履約單)這樣的關鍵欄位,導致沒辦法直接簡單的 join 資料。
-
在這樣一個架構下,們的 flink 在成本上,在穩定性維護上,調優上做的非常吃力。
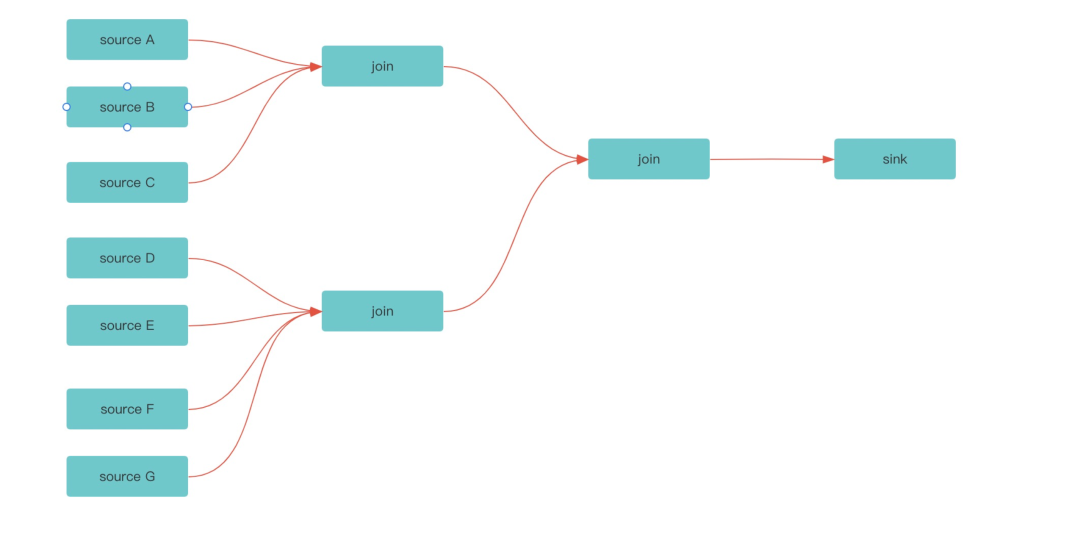
附:clickhouse 不支援標準的 upsert 模式,可以通過使用 AggregatingMergeTree 引擎欄位型別使用 SimpleAggregateFunction(anyLast, Nullable(UInt64)) 合併規則取最後一條非 null 資料可以實現 upsert 相似的功能,但讀時合併效能有影響。
2.3 實時架構 2.0
2.3.1 flink+kafka+hologres
因此我們迫切的希望有支援 upsert 能力的 olap 資料庫,同時能搞定供應鏈寫多少的場景,也能搞定我們複雜查詢的場景,我們希望的 olap 資料至少能做到如下幾點:
-
有 upsert 能力,能對 flink 大任務做有效拆分;
-
存算分離,複雜業務計算,不影響業務寫入,同時能平滑擴縮容;
-
有一定的 join 能力帶來一些靈活度;
-
有完善的分割槽機制,熱資料查詢效能不受整體資料增長影響;
-
完善的資料備份機制。

這樣一個行列混合的 olap 資料庫,支援 upsert,支援存算分離,還是比較符合我們的預期。
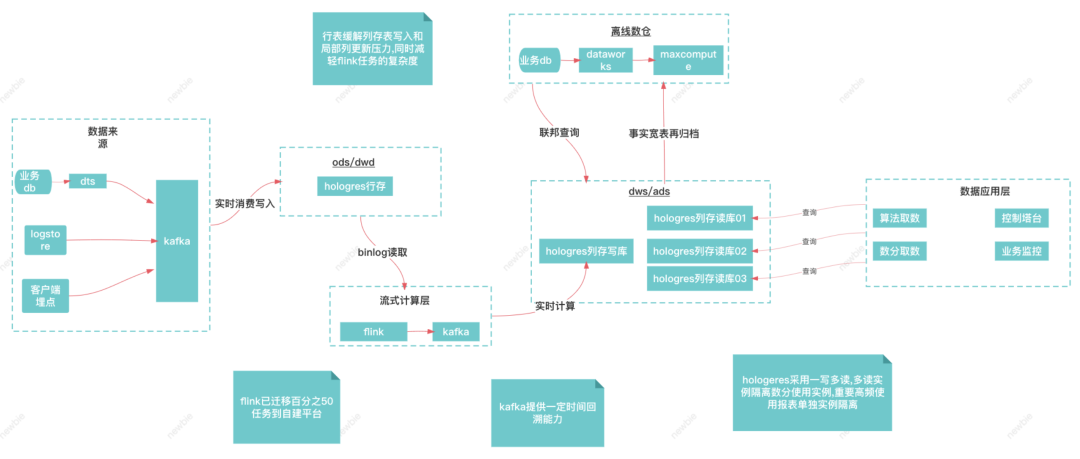
目前這樣一套架構支援了供應鏈每天數千人的報表取數需求,以及每天 10 億資料量的匯出,訪問量在得物所有 to B 系統中排名靠前。
2.3.2 我們遇到的一些問題
多時間問題如何設定 segment_key,選擇哪個業務欄位作為 segment_key 供應鏈幾十個環節都有操作時間,在不帶 segment_key 的情況下效能如何保障,困擾了我們一段時間。

設定合理的 segment_key 如有序的時間欄位,可以做到完全順序寫。每個 segment 檔案都有個 min,max 值,所有的時間欄位過來只需要去比較下在不在這個最小值最大值之間(這個動作開銷很低),不在範圍內直接跳過,在不帶 segment_key 查詢的條件下,也能極大的降低所需要過濾的檔案數量。

批流融合背景:業務快速發展過程中,持續迭代實時任務成為常態。供應鏈業務複雜,環節多,流程往往長達一個月週期之久,這就導致 state ttl 設定週期長。job 的 operator 變化(sql 修改),checkpoint 無法自動恢復,savepoint 恢復機制無法滿足,比如增加 group by 和 join。重新消費歷史資料依賴上游 kafka 儲存時效,kafka 在公司平臺一般預設都是儲存 7 天,不能滿足一個月資料回刷需求場景。
方案:通過批流融合在 source 端實現離線 + 實時資料進行資料讀取、補齊。

(1)離線按 key 去重,每個 key 只保留一條,減少訊息量下發。(2)離線和實時資料合併,使用 last_value 取相同主鍵最新事件時間戳的一條資料。(3)使用 union all + group by 方式是可作為代替 join 的一個選擇。(4)實時資料取當日資料,離線資料取歷史資料,防止資料漂移,實時資料需前置一小時。
Join 運算元亂序

-
問題分析
由於 join 運算元是對 join 鍵做 hash 後走不同的分片處理資料 ,開啟了 2 個併發後,再因為 header_id 欄位的值變化,detail 表 2 次資料流走到了 2 個不同的 taskmanage,而不同的執行緒是無法保證輸出有序性的 ,所以資料有一定的概率會亂序輸出,導致期望的結果不正確,現象是資料丟失。
-
解決辦法
通過 header inner join detail 表後,拿到 detail_id,這樣再次通過 detail_id join 就不會出現(join 鍵)的值會從 null 變成非 null 的情況發生了,也就不會亂序了。
insert into sinkSelect detail.id,detail.header_id,header.idfrom detailleft join (Select detail.id AS detail_id,detail.header_id,header.idfrom headerinner join detailon detail.header_id = header.id) headerNewon detail.id = headerNew.detail_id
2.3.3 Hologres or starrocks
這裡也聊聊大家比較關注的 hologres 和 starrocks,starrocks 從開源開始也和我們保持了密切聯絡,也做了多次的深入交流,我們也大致列了兩者之間的一些各自優勢和對於我們看來一些不足的地方。

3 其他做的一些事情
3.1 開發提效工具——flink 程式碼生成器
參考 MyBatis gennerator 一些思想,利用模板引擎技術,定製化模板來生成 flink sql。可以解決程式碼規範,和提升開發效率。基本可以通過程式碼配置來生成 flink sql。

3.2 開發提效工具——視覺化平臺
直接通過配置的方式,線上寫 sql,直接生成頁面和介面,一鍵釋出,同時引入快取,鎖排隊機制解決高峰訪問效能問題。
動態配置介面,一鍵生成 rpc 服務:

動態配置報表:

4 未來規劃
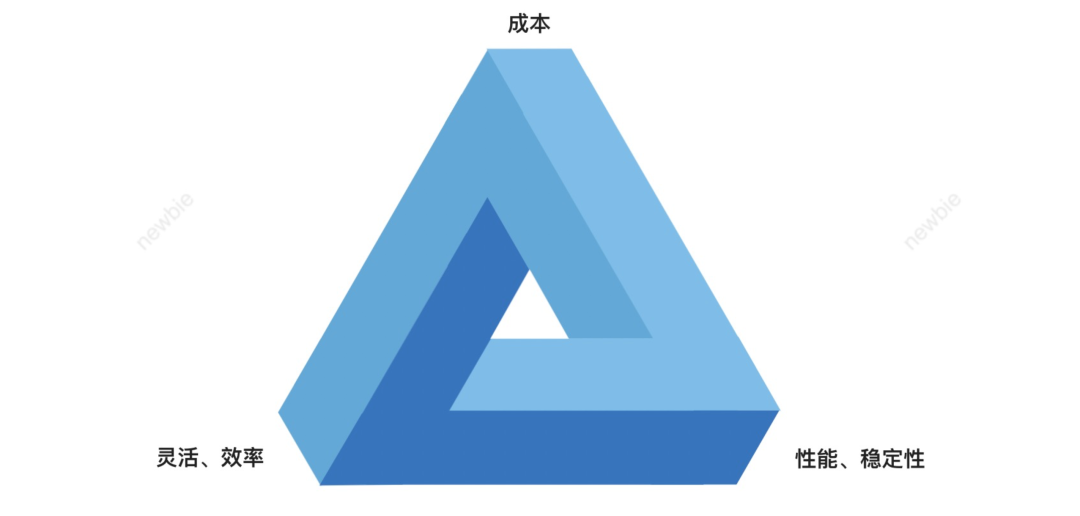
當前架構依然存在某種程度的不可能三角,我們需要探索更多的架構可能性:
(1)利用寫在 holo,計算在 mc 避免 holo 這種記憶體資料庫,在極端查詢記憶體被打爆的問題,利用 mc 的計算能力可以搞定一些事實表 join 的問題提升一些靈活度。

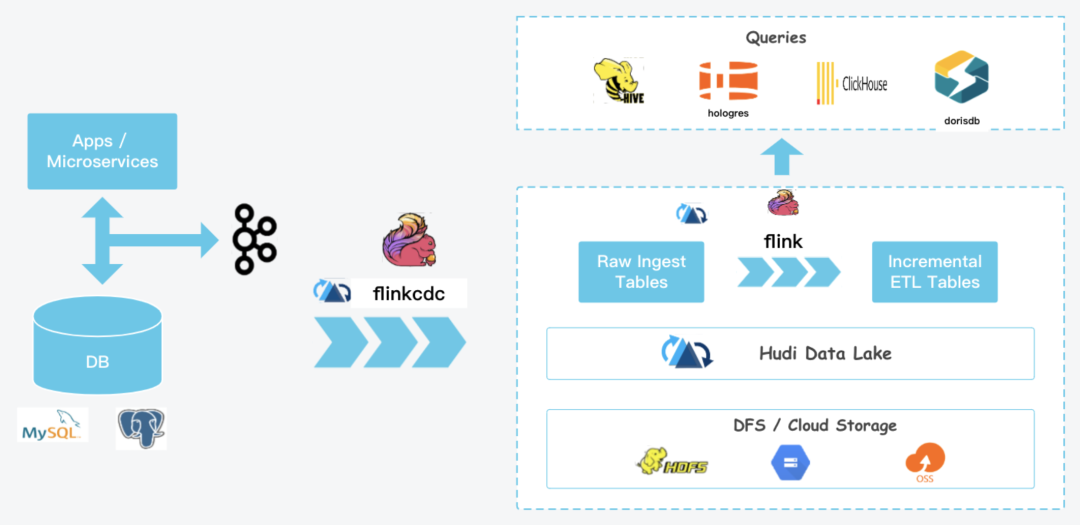
(2) 藉助 apache hudi 推進湖倉一體,hudi 做批流儲存統一,flink 做批流計算統一,一套程式碼,提供 5-10 分鐘級的準實時架構,緩解部分場景只需要準時降低實時計算成本。
- MySQL MVCC實現原理
- 為什麼專案老夭折?這份專案管理指南請收好
- “伯樂”流量調控平臺工程視角 | 得物技術
- 如何評估某活動帶來的大盤增量 | 得物技術
- 得物榜單|全鏈路生產遷移及B/C端資料儲存隔離
- 透過現象看Java AIO的本質 | 得物技術
- 時效準確率提升之承運商路由網路挖掘 | 得物技術
- 存貨庫存模型升級始末 | 得物技術
- 關於加解密、加簽驗籤的那些事 | 得物技術
- GPU推理服務效能優化之路 | 得物技術
- 得物供應鏈複雜業務實時數倉建設之路
- 從 0 到 1,億級訊息推送的穩定性保障 | 得物技術
- 前端監控穩定性資料分析實踐 | 得物技術
- 得物容器SRE探索與實踐
- 得物熱點探測技術架構設計與實踐
- 今年很火的 AI 繪畫怎麼玩
- 得物社群計數系統設計與實現
- 得物商家客服桌面端Electron技術實踐
- 得物商家客服桌面端Electron技術實踐
- 得物染色環境落地實踐