畢昇 JDK 8u292、11.0.11 釋出!
2021 年 6 月 30 日,畢昇 JDK update Q2 版本正式釋出,下載方式見文末參考連結。該版本在同步 OpenJDK 社群 8u292/11.0.11 的基礎上,還包含如下更新,為使用者提供高效能、可用於生產環境的 OpenJDK 發行版。
-
提供鯤鵬硬體加速的 KAEProvider 支援 DH,RSA 簽名等眾多演算法(畢昇 JDK8) -
Jmap 並行掃描優化支援 CMS(畢昇 JDK8, 畢昇 JDK11) -
G1 GC 實現 numa-aware 特性(畢昇 JDK8) -
G1 GC numa-aware 優化(畢昇 JDK11) -
Bug fixes
鯤鵬硬體加速的 KAEProvider(畢昇 JDK8)
KAE(Kunpeng Accelerate Engine)加解密是鯤鵬 920 處理器提供的硬體加速方案,可以顯著降低處理器消耗,提高處理器效率. 畢昇 JDK 8u282 為 Java 使用者提供 了 KAEProvider,使 Java 開發人員可以直接使用硬體帶來的加速效果,但支援演算法有限。此版本在 282 的基礎上,新增 DH、ECDH、RSA 簽名、AES-GCM 等演算法,有效提升應用在 HTTPS 中的處理效能。同時提供對國密演算法 SM3 和 SM4 的支援,其中 SM4 支援 ECB/CBC/CTR/OFB 模式。
到目前為止,畢昇 JDK 除了預設 Provider 不支援的加密模式外(例如 AES/XTS 模式),已支援 KAE 硬體加速引擎中的所有加解密演算法,KAEProvider 具體實現的演算法如下:
| 演算法 | 說明 |
| 摘要演算法 | 包括MD5、SHA256、SHA384、SM3 |
| 對稱加密演算法AES | 支援ECB、CBC、CTR、GCM模式 |
| 對稱加密演算法SM4 | 包括ECB、CBC、CTR、OFB模式 |
| HMac | 包括HmacMD5、HmacSHA1、HmacSHA224、HmacSHA256、HmacSHA384、HmacSHA51 |
| 非對稱加解密演算法RSA | 支援512、1024、2048、3072、4096位祕鑰大小 |
| DH | 包括DHKeyPairGenerator和DHKeyAgreement,支援512、1024、2048、3072、4096位祕鑰 |
| ECDH | 包括ECKeyPairGenerator和ECDHKeyAgreement,支援曲線secp224r1、prime256v1、secp384r1、secp521r1 |
| RSA簽名 | 包括RSASignature和RSAPSSSignature,私鑰只支援RSAPrivateCrtKey |
實現
KAEProvider 的實現原理在前期已有介紹,詳見openEuler 21.03 特性解讀 | 畢昇 JDK8 支援鯤鵬硬體加解密特性詳解和使用介紹. 簡而言之, KAEProvider 通過實現 JDK 中的特定的 SPI(Service Provider Interface)介面支援具體的演算法,此版本實現的 SPI 類如下:
| Spi類 | 實現類 | 說明 |
| MessageDigestSpi | KAEDigest | 支援SM3演算法 |
| KeyAgreementSpi | KAEDHKeyAgreement | 支援512、1024、2048、3072、4096位的祕鑰 |
| KAEECDHKeyAgreement | 支援曲線secp224r1、prime256v1、secp384r1、secp521r1 | |
| KeyPairGeneratorSpi | KAEDHKeyPairGenerator | 當前支援生成512、1024、2048、3072、4096位的祕鑰 |
| KAEECKeyPairGenerator | 支援生成224、256、384、521位的祕鑰 | |
| CipherSpi | KAEAESCipher | 支援GCM模式 |
| KAESM4Cipher | 支援ECB、CBC、CTR、OFB模式 | |
| SignatureSpi | KAERSASignature | 支援“SHA1withRSA”, “SHA224withRSA”, “SHA384withRSA”, “SHA256withRSA”, “SHA512withRSA“, 私鑰只支援RSAPrivateCrtKey |
| KAERSAPSSSignature | 支援SHA-1“, ”SHA-224“, ”SHA-256“, ”SHA-384“, ”SHA-512“, 私鑰只支援RSAPrivateCrtKey |
除此之外,畢昇 JDK 為使用者提供$JAVA_HOME/lib/ext/kaeprovider.conf 檔案,方便使用者啟動或關閉 KAEProvider 中的某些演算法,預設啟用所有演算法,檔案內容如下:
#
# This is the config file for KAEProvider
#
# Algorithms are enabled by default if KAEProvider is used.
# Delete # if you want to disable certain algorithm.
# kae.md5=false
# kae.sha256=false
# kae.sha384=false
# kae.sm3=false
# kae.aes=false
# kae.sm4=false
# kae.hmac=false
# kae.rsa=false
# kae.dh=false
# kae.ec=false
# enable KAEProvider log setting
# kae.log=true
使用者也可通過開啟此檔案的日誌選項,來檢視是否檢測到了機器上的 kae 引擎。如果打開了此選項,並在使用者的機器上檢測到了 kae 引擎,則會將日誌寫入程序啟動目錄下的 kae.log 檔案,如下所示:
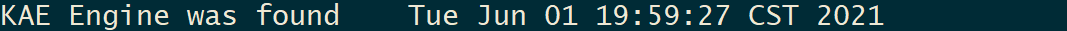
效能測試
測試環境:
-
CPU: Kunpeng 920 -
OS: openEuler 20.03 -
KAE: v1.3.10 -
JDK: 畢昇 JDK 1.8.0_292
JMH
測試用例請參加畢昇 JDK 程式碼倉[3].
如下為 DH 的測試結果,可以看到與 JDK 預設的 Provider 相比,當祕鑰長度為 2048 時,平均效能提升 360%;當祕鑰長度為 4096 時,平均效能提升 460%:

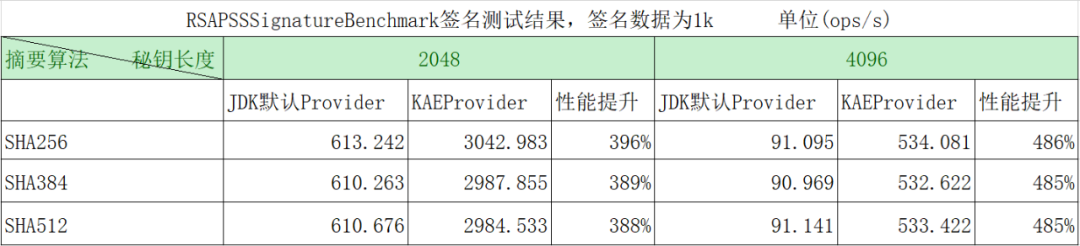
如下為 RSAPSS 簽名的測試結果,可以看到與 JDK 預設的 Provider 簽名 1k 的資料相比,當祕鑰長度為 2048 時,平均效能提升 390%,當祕鑰長度為 4096 時,平均效能提升 485%.
HTTPS
-
服務端 Tomcat: 9.0.46

-
客戶端 Jmeter: 5.4.1
-
步驟: -
Tomcat: 預設 Provider/KAEProvider -
Jmeter: 預設 Provider
預設 Provider 的結果如下:

KAEProvider 的結果如下:

結論:與 JDK 預設的 Provider 相比,在 HTTPS 短連線場景下,KAEProvider 可以提升 93%.
Jmap 並行掃描優化支援 CMS(畢昇 JDK8, 畢昇 JDK11)
背景
當前 jmap 採用單執行緒對 java 堆進行掃描,掃描速度較慢,並且對超大堆進行掃描時(大於 200G),容易引起系統卡死。因此可以通過多執行緒來進行掃描,減少卡頓時間。之前釋出的版本支援了 G1GC 與 ParallelGC 並行掃描,本次釋出增加對 CMS GC 的支援。
實現
畢昇 JDK 在社群高版本 jmap 優化回合的基礎上,在 cms heap 上部署 CMSHeapBlockClaimer 用來為每個執行緒分配 heap block,增加了 object_iterate_block 介面用來掃描 block 中的 object,每個執行緒的掃描結果會在已有的 heap_inspection 模組中的 ParHeapInspectTask 進行合併。具體包含內容如下:
-
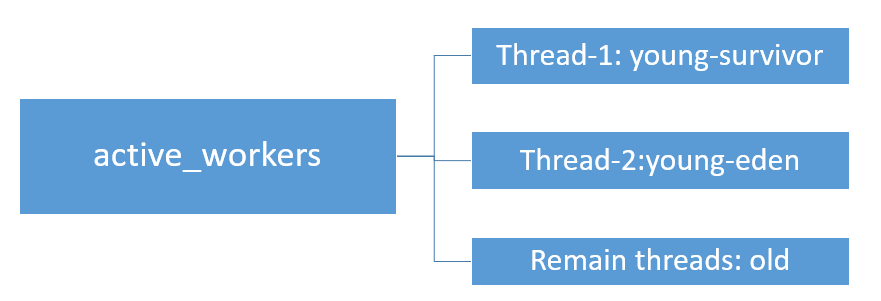
整體掃描策略: 可用的GC執行緒(active_workers)有兩個用來掃描年輕代,一個掃描suvivor區,另一個掃描eden區;剩下的執行緒全部用來掃描老年代。
-
GC執行緒任務劃分:在CMSHeap模組中新增CMSHeapBlockClaimer類,提供claim_and_get_block介面用來為每一個執行緒生成唯一的block_index, GC執行緒根據block_index來確定自己要掃描的區域。

-
年輕代掃描策略:年輕代的eden(block_index = 0)跟survivor(block_index = 1)區會被分別當做一個整體的block,GC執行緒掃描時沿用現有的掃描介面object_iterate。
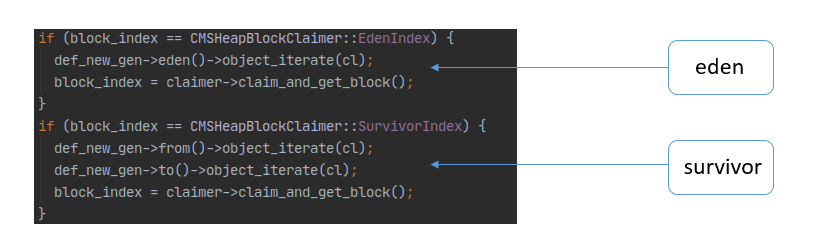
-
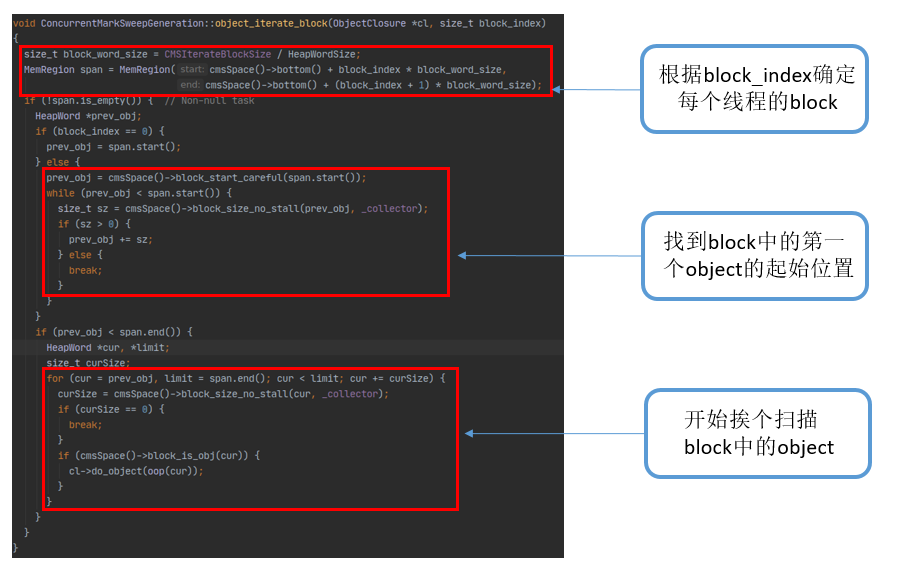
老年代掃描策略:+ 老年代被分成一個個 1M 大小的 block,block 大小由引數 IterateBlockSize 決定。+ 在 ConcurrentMarkSweepGeneration 中新增 object_iterate_block 方法來掃描 block。
使用者可通過在 jmap -histo 後增加 parallel 引數來使用此特性,如下所示:
-
jmap -histo:live,parallel=3 pid : 指定並行執行緒數為 3 -
jmap -histo:live,parallel=0 pid : 使用當前系統可支援的並行執行緒數(-XX:ParallelGCThreads) -
jmap -histo:live,parallel=1 pid : 使用原有的序列掃描
效能測試
測試環境:
-
CPU: Kunpeng 920 -
OS: openEuler 20.03 -
JDK: 畢昇 JDK1.8.0_292、畢昇 JDK11.0.11
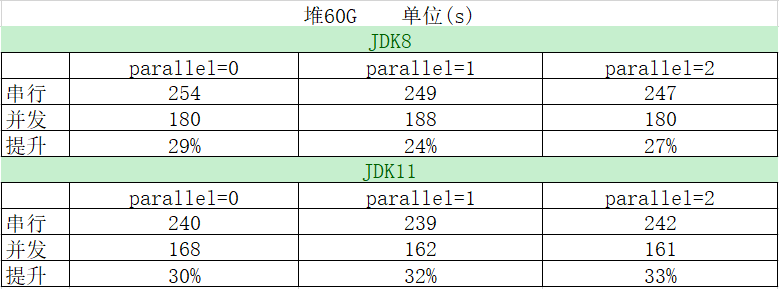
在對約 60G 大小的堆進行掃描時,可以看到 JDK8 並行掃描的平均收益在 26%左右,JDK11 並行掃描的平均收益在 31%左右。
G1 GC 實現 NUMA-Aware 特性(畢昇 JDK8)
背景
在 NUMA 架構下,跨 NUMA 節點操作記憶體相比本 NUMA 節點操作記憶體時延會成倍增加。OpenJDK 社群在 JDK14 中合入了 G1 GC NUMA-Aware 特性[4],可以讓 JAVA 使用者執行緒儘可能的操作本 NUMA 節點上的記憶體,可以提高 G1 GC 在 NUMA 架構下的處理效能,但低版本的 JDK8 和 JDK11 不支援該特性。
實現
畢昇 JDK 以前已將社群高版本中的 G1 NUMA-Aware 特性合入到了 11.0.8,此次將該特性回合到 8u292,有效提高 G1 GC 在 NUMA 架構下的處理效能。具體的實現方式為:在配置的 NUMA node 節點(numactl 可以配置,不配置就是所有節點)上,均勻分配 G1 Region,在 Young 區(Eden 和 Survivor)申請 Region 的時候優先選擇本節點的 Region。
使用者只需要通過開啟 UseNUMA 引數即可使用此特性,如下所示:
-
-XX:+UseG1GC –XX:+UseNUMA
效能測試
SPECjbb 2015 是業界通用的 Java 效能的基準測試[5],測試結果主要分為 Max 和 Critical,其中 Max 是指最大吞吐量,Critical 是指在在限制響應時間下的吞吐量。這裡採用 SPECjbb 對該特性進行測試。
測試環境:
-
CPU:Kunpeng-920,96核 -
OS:openEuler20.03 -
記憶體:384G -
JDK: 畢昇JDK1.8.0_292 -
SPECjbb配置:GROUP_COUNT=1,TI_JVM_COUNT=4
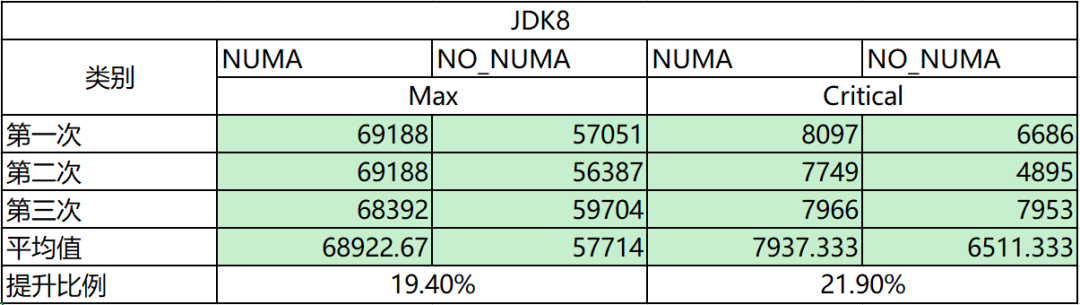
SPECjbb 的測試結果如下,可以看到與不開啟 NUMA 相比,開啟 NUMA 後 的效能平均提升 20%+.
G1 GC NUMA-Aware 優化(畢昇 JDK11)
背景
畢昇 JDK11 已在 11.0.8 版本支援 G1 GC Numa-Aware 特性,合入該特性後,G1 都儘量線上程所屬的 NUMA node 上去分配記憶體,當執行緒所屬 Node 上的記憶體不夠分配或者在指定的遍歷次數達到後,如果沒有獲取到所屬 node 上的記憶體時就會隨機從空閒的連結串列上取一個 region,而這種隨機選擇的不一定是最優的。
實現
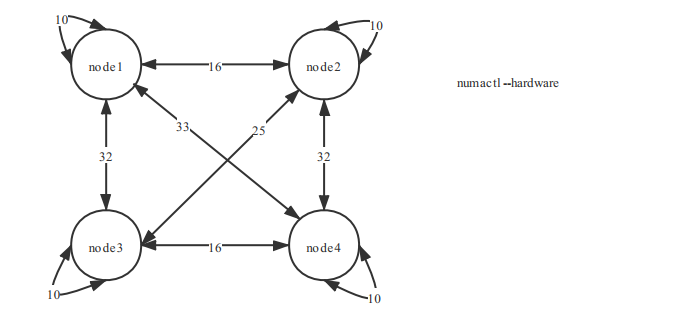
上圖以華為泰山 200 伺服器為例,通過numactl --hardware可以顯示 node 間距離值資訊,可以看到 node 自身的距離值是 10, node1 與 node2 的距離值是 16,node1 與 node3 的距離值是 32,數值越小,跨 node 的訪存速度會更快。基於上面背景描述,畢昇 JDK11.0.11 在畢昇 JDK11.0.10 的基礎上,對 G1GC NUMA-Aware 特性訪存做了持續優化,通過在遍歷 free region 連結串列時,記錄到本 Node 的最小距離的 region,最終將距離本執行緒所屬 Node 最小距離的 region 分配出去(包含本 Node 上的 region,距離為 10),實現記憶體訪問的儘量最優化,達到提升業務效能目的。
使用者只需要通過開啟 UseNUMA 引數來使用此特性,如下所示:
-
-XX:+UseG1GC –XX:+UseNUMA
效能測試
測試環境與上述畢昇 JDK8 的 NUMA-Aware 測試環境相同。
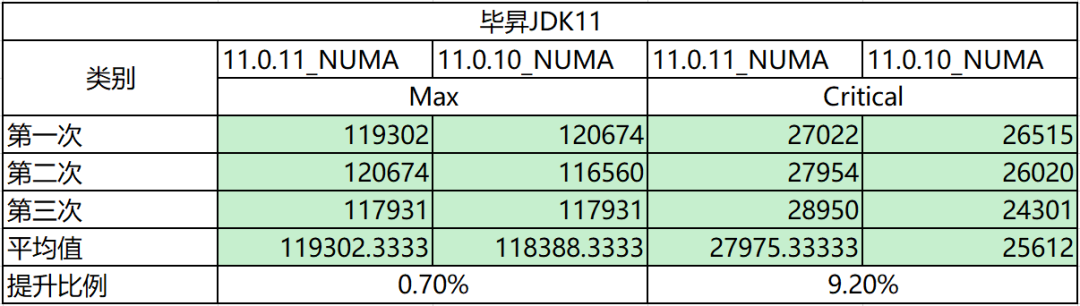
SPECjbb 的測試結果如下,可以看到與畢昇 JDK11.0.10 相比,開啟 NUMA 特性後,Critical 效能平均提升 9%,Max 效能無劣化。
Bug fixes
除了上面介紹的一些特性外,畢昇 JDK 還合入了社群高版本中的一些 bug fix 和優化的 patch,為使用者提供穩定、高效能的畢昇 JDK。具體回合 patch 如下:
-
JDK8 -
8264640: CMS ParScanClosure misses a barrier -
8266191: Missing aarch64 parts of JDK-8181872(C1: possible overflow when strength reducing integer multiply by constant) -
8266929: Unable to use algorithms from 3p providers -
8268427: Improve AlgorithmConstraints:checkAlgorithm performance -
JDK11 -
8264640: CMS ParScanClosure misses a barrier
參考
[1] 畢昇 JDK8 下載:http://mirrors.huaweicloud.com/kunpeng/archive/compiler/bisheng_jdk/bisheng-jdk-8u292-linux-aarch64.tar.gz
[2] 畢昇 JDK11 下載:http://mirrors.huaweicloud.com/kunpeng/archive/compiler/bisheng_jdk/bisheng-jdk-11.0.11-linux-aarch64.tar.gz
[3] KAEProvider jmh 用例:http://gitee.com/openeuler/bishengjdk-8/tree/master/jdk/test/micro/org/openeuler/bench/security/openssl
[4]JEP 345: NUMA-Aware Memory Allocation for G1:http://openjdk.java.net/jeps/345
[5]SPECjbb 2015:http://www.spec.org/jbb2015/
交流群:
歡迎加入 Compiler SIG 交流群,一起交流編譯器、虛擬機器技術。或新增微信,回覆"加群",進入 Compiler SIG 交流群。

本文分享自微信公眾號 - openEuler(openEulercommunity)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- 玩轉機密計算從 secGear 開始
- openEuler資源利用率提升之道06:虛擬機器混部OpenStack排程
- openGauss Cluster Manager RTO Test
- JVM 鎖 bug 導致 G1 GC 掛起問題分析和解決【畢昇JDK技術剖析 · 第 2 期】
- 手把手帶你玩轉 openEuler | openEuler 的使用
- 681名學生中選!暑期2021開啟火熱“開源之夏”!
- 手把手帶你玩轉 openEuler | 初識 openEuler
- StratoVirt 中的 PCI 裝置熱插拔實現
- 使用 NMT 和 pmap 解決 JVM 資源洩漏問題
- JNI 中錯誤的訊號處理導致 JVM 崩潰問題分析
- Java Flight Recorder - 事件機制詳解
- 畢昇 JDK 8u292、11.0.11 釋出!
- StratoVirt 中的虛擬網絡卡是如何實現的?
- openEuler結合ebpf提升ServiceMesh服務體驗的探索
- 我的openEuler社群參與之旅
- StratoVirt 的中斷處理是如何實現的?
- 看看畢昇 JDK 團隊是如何解決 JVM 中 CMS 的 Crash
- 使用 perf 解決 JDK8 小版本升級後效能下降的問題【畢昇JDK技術剖析 · 第 1 期】
- 2021年畢昇 JDK 的第一個重要更新來了
- 漏洞盒子 × openEuler | 廣邀白帽共築安全的Linux開放應用生態