如何輕鬆做資料治理?開源技術棧告訴你答案
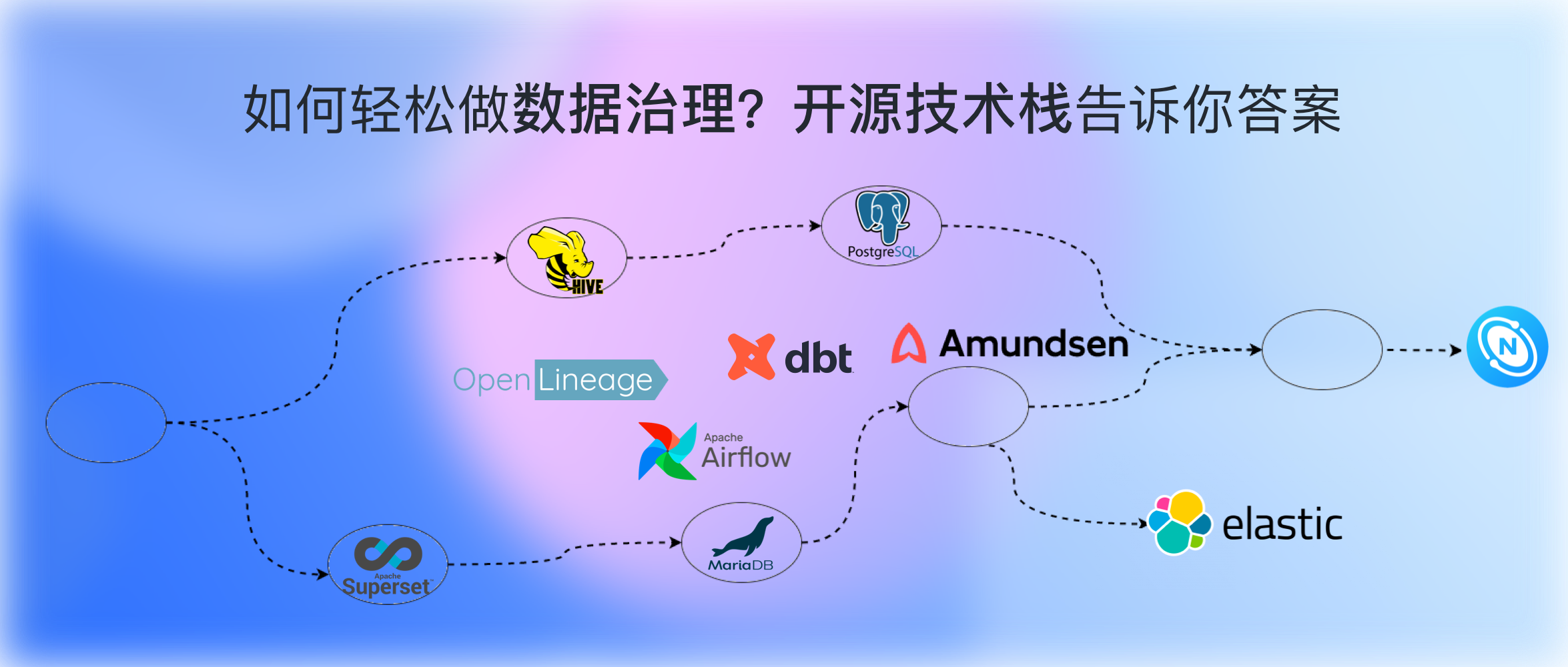
搭建一套資料治理體系耗時耗力,但或許我們沒有必要從頭開始搞自己的資料血緣專案。本文分享如何用開源、現代的 DataOps、ETL、Dashboard、元資料、資料血緣管理系統構建大資料治理基礎設施。
元資料治理系統
元資料治理系統是一個提供了所有資料在哪、格式化方式、生成、轉換、依賴、呈現和所屬的一站式檢視。
元資料治理系統是所有資料倉庫、資料庫、表、儀表板、ETL 作業等的目錄介面(catalog),有了它,我們就不用在群裡喊“大家好,我可以更改這個表的 schema 嗎?”、 “請問誰知道我如何找到 table-view-foo-bar 的原始資料?”…一個成熟的資料治理方案中的元資料治理系統,對資料團隊來說非常必要。
而資料血緣則是元資料治理系統眾多需要管理的元資料之一,例如,某些 Dashboard 是某一個 Table View 的下游,而這個 Table View 又是從另外兩個上游表 JOIN 而來。顯然,應該清晰地掌握、管理這些資訊,去構建一個可信、可控的系統和資料質量控制體系。
資料治理的可行方案
資料治理方案設計
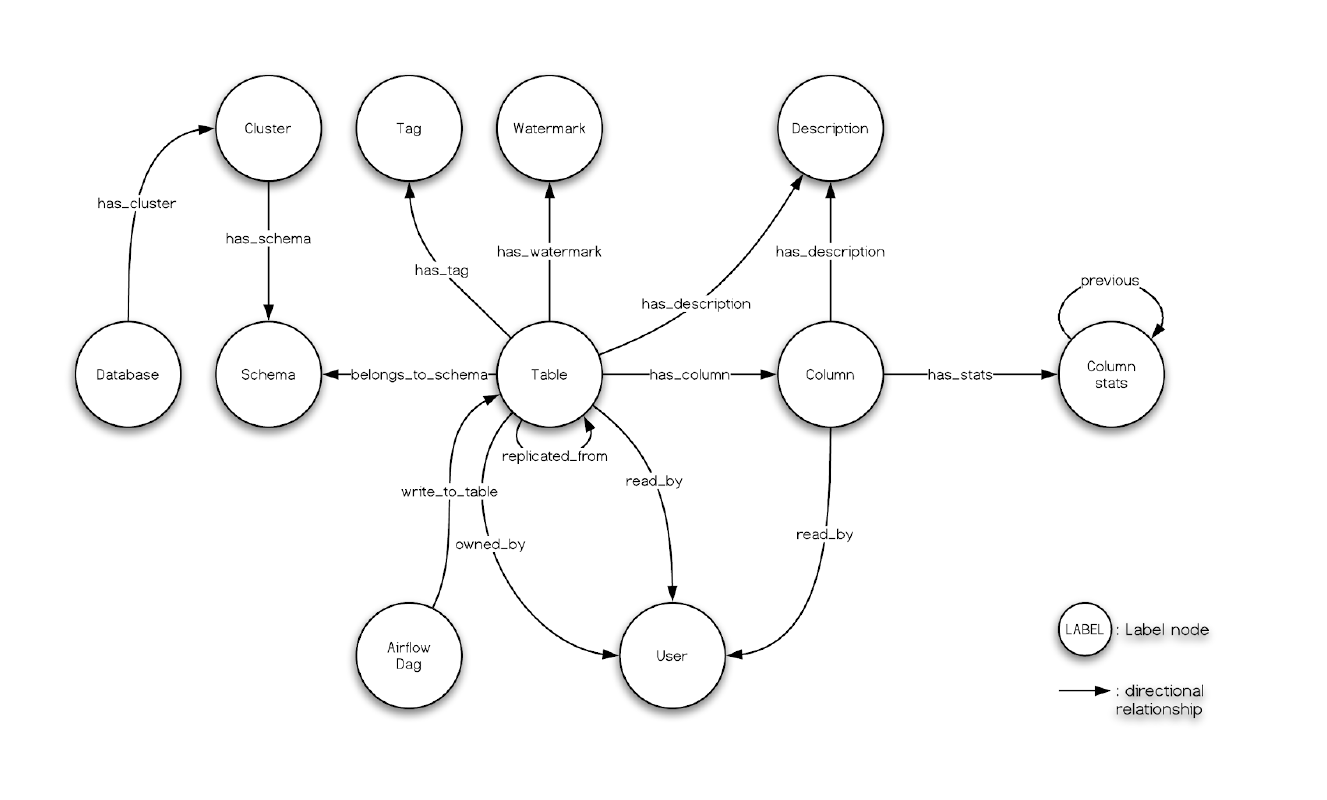
元資料和資料血緣本質上非常適合採用圖資料建模、圖資料庫。因為資料治理涉及的典型查詢便是面向圖關係的查詢,像“查詢指定元件(即表)的所有 n 度(深度)的資料血緣”就是圖查詢語句 FIND ALL PATH 跑起來的事。從日常大家在論壇、微信群裡討論的查詢和圖建模來看,NebulaGraph 社群很多人在從零開始搭建資料血緣系統,而這些工作看起來大多是在重複造輪子,而且還是不容易造的輪子。
既然如此,前人種樹後人乘涼,這裡我決定搭建一個完備、端到端(不只有元資料管理)的資料系統,供大家參考解決資料血緣、資料治理問題。這個套資料系統會採用市面上優秀的開源專案,而圖資料庫這塊還是採用大家的老朋友——NebulaGraph。希望對大家能有所啟發,在此基礎之上擁有一個相對完善的圖模型,以及設計精巧、開箱即用的元資料治理系統。
下面,來看看元資料治理系統的輪子都需要哪些功能元件:
- 元資料抽取
- 這部分需要從不同的資料棧拉/推資料,像是從資料庫、數倉、Dashboard,甚至是 ETL Pipeline 和應用、服務中搞資料。
- 元資料儲存
- 可以存在資料庫、圖資料庫裡,甚至存成超大的 JSON manifest 檔案都行
- 元資料目錄介面系統 Catalog
- 提供 API / GUI 來讀寫元資料和資料血緣系統
下圖是整個方案的簡單示意圖:
其中,上面的虛線框是元資料的來源與匯入、下面的虛線框是元資料的儲存與展示、發現。

開源技術棧
下面,介紹下資料治理系統的每個部分。
資料庫和數倉
為了處理和使用原始和中間資料,這裡一定涉及至少一個數據庫或者數倉。它可以是 Hive、Apache Delta、TiDB、Cassandra、MySQL 或 Postgres。
在這個參考專案中,我們選一個簡單、流行的 Postgres。
✓ 資料倉庫:Postgres
資料運維 DataOps
我們應該有某種 DataOps 的方案,讓 Pipeline 和環境具有可重複性、可測試性和版本控制性。
在這裡,我們使用了 GitLab 建立的 Meltano。
Meltano 是一個 just-work 的 DataOps 平臺,它可以用巧妙且優雅的方式將 Singer 作為 EL 和 dbt 作為 T 連線起來。此外,它還連線到其他一些 dataInfra 實用程式,例如 Apache Superset 和 Apache Airflow 等。
至此,我們又納入了一個成員:
✓ GitOps:Meltano http://gitlab.com/meltano/meltano
ETL 工具
上面我們提到過組合 Singer 與 Meltano 將來自許多不同資料來源的資料 E(提取)和 L(載入)資料目標,並使用 dbt 作為 Transform 的平臺。於是我們得到:
✓ EL:Singer ✓ T: dbt
資料視覺化
在資料之上建立 Dashboard、圖表和表格得到資料的洞察是很符合直覺的,類似大資料之上的 Excel 圖示功能。

Apache Superset 是我很喜歡的開源資料視覺化專案,我準備用它來作為被治理管理的目標之一。同時,還會利用它實現視覺化功能來完成元資料洞察。於是,
✓ Dashboard:Apache Superset
任務編排(DAG Job Orchestration)
在大多數情況下,我們的 DataOps 作業、任務會演變成需要編排系統的規模,我們可以用 Apache Airflow 來負責這一塊。
✓ DAG:Apache Airflow http://airflow.apache.org/
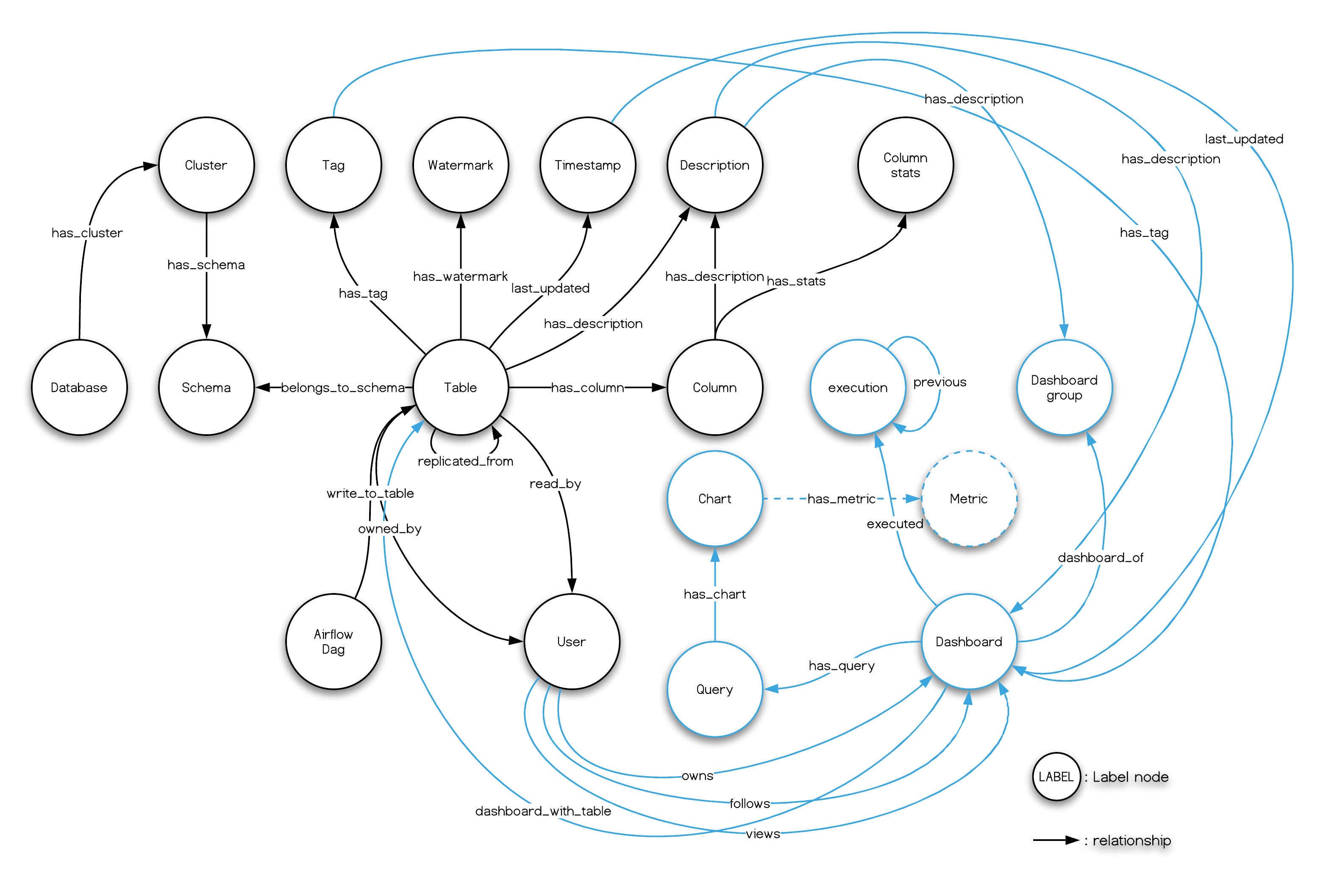
元資料治理
隨著越來越多的元件和資料被引入資料基礎設施,在資料庫、表、資料建模(schema)、Dashboard、DAG(編排系統中的有向無環圖)、應用與服務的各個生命週期階段中都將存著海量的元資料,需要對它們的管理員和團隊進行協同管理、連線和發現。
Linux Foundation Amundsen 是解決該問題的最佳專案之一。 Amundsen 用圖資料庫為事實源(single source of truth)以加速多跳查詢,Elasticsearch 為全文搜尋引擎。它在順滑地處理所有元資料及其血緣之餘,還提供了優雅的 UI 和 API。 Amundsen 支援多種圖資料庫為後端,這裡咱們用 NebulaGraph。
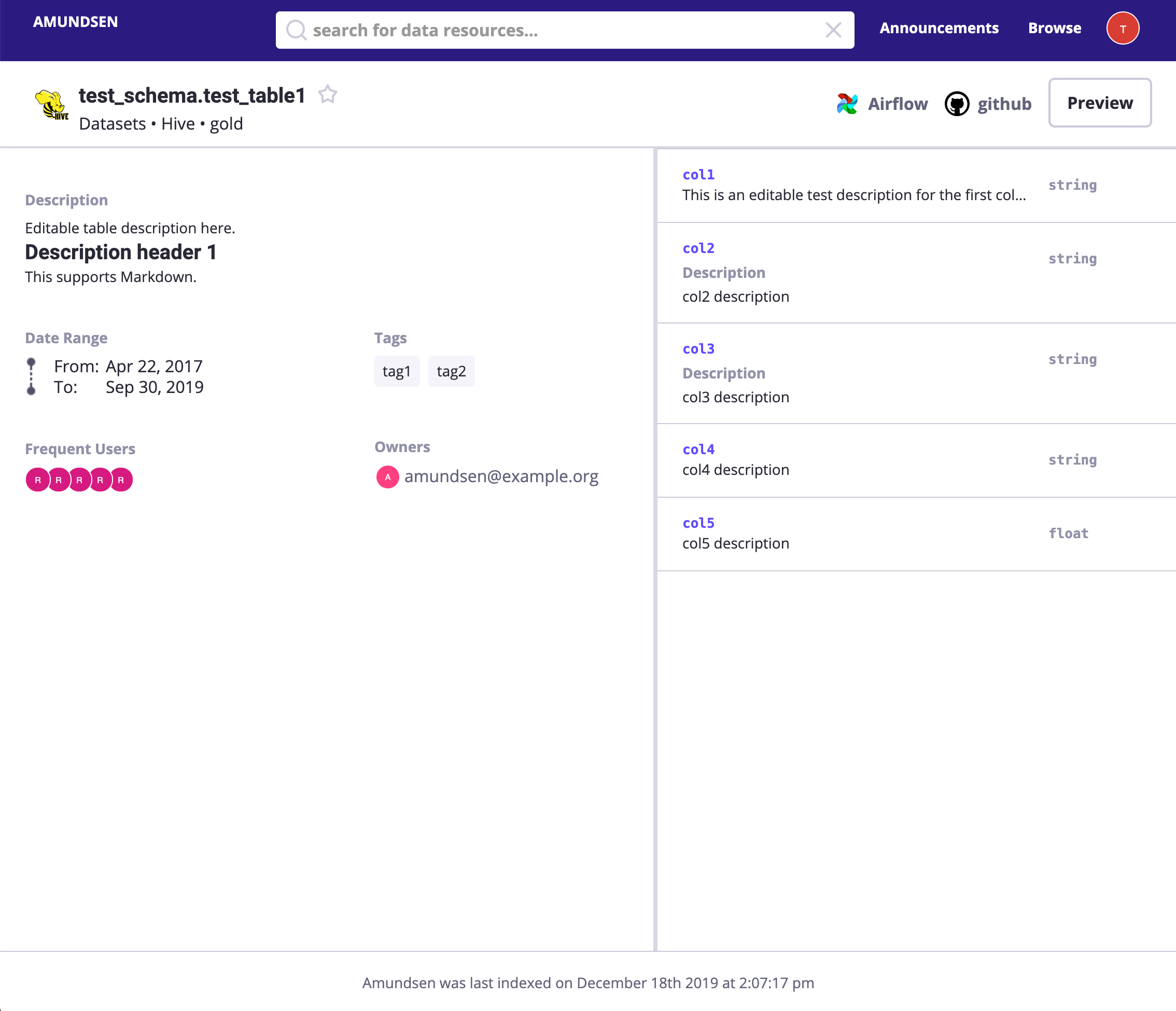
現在的技術棧:
✓ 資料發現:Linux Foundation Amundsen ✓ 全文搜尋:Elasticsearch ✓ 圖資料庫:NebulaGraph
好的,所有元件都齊正了,開始組裝它們吧。
環境搭建與各元件初識
本次實踐的專案方案已開源,你可以訪問 http://github.com/wey-gu/data-lineage-ref-solution 來獲得對應的程式碼。
整個實踐過程,我遵循了儘量乾淨、鼓勵共建的原則。專案預設在一個 unix-like 系統上執行,且聯網和裝有 Docker-Compose。
這裡,我將在 Ubuntu 20.04 LTS X86_64 上執行它,當然在其他發行版或 Linux 版本上應該也沒有問題。
執行一個數倉、資料庫
首先,安裝 Postgres 作為我們的數倉。
這個單行命令會建立一個使用 Docker 在後臺執行的 Postgres,程序關閉之後容器不會殘留而是被清理掉(因為引數--rm)。
docker run --rm --name postgres \
-e POSTGRES_PASSWORD=lineage_ref \
-e POSTGRES_USER=lineage_ref \
-e POSTGRES_DB=warehouse -d \
-p 5432:5432 postgres
我們可以用 Postgres CLI 或 GUI 客戶端來驗證命令是否執行成功。
DataOps 工具鏈部署
接下來,安裝有機結合了 Singer 和 dbt 的 Meltano。
Meltano 幫助我們管理 ETL 工具(作為外掛)及其所有配置和 pipeline。這些元資訊位於 Meltano 配置及其系統資料庫中,其中配置是基於檔案的(可以使用 GitOps 管理),它的預設系統資料庫是 SQLite。
安裝 Meltano
使用 Meltano 的工作流是啟動一個“meltano 專案”並開始將 E、L 和 T 新增到配置檔案中。Meltano 專案的啟動只需要一個 CLI 命令 meltano init yourprojectname。不過,在那之前,先用 Python 的包管理器 pip 或者 Docker 映象安裝 Meltano,像我示範的這樣:
在 Python 虛擬環境中使用 pip 安裝 Meltano:
mkdir .venv
# example in a debian flavor Linux distro
sudo apt-get install python3-dev python3-pip python3-venv python3-wheel -y
python3 -m venv .venv/meltano
source .venv/meltano/bin/activate
python3 -m pip install wheel
python3 -m pip install meltano
# init a project
mkdir meltano_projects && cd meltano_projects
# replace <yourprojectname> with your own one
touch .env
meltano init <yourprojectname>
或者,用 Docker 容器安裝 Meltano:
docker pull meltano/meltano:latest
docker run --rm meltano/meltano --version
# init a project
mkdir meltano_projects && cd meltano_projects
# replace <yourprojectname> with your own one
touch .env
docker run --rm -v "$(pwd)":/projects \
-w /projects --env-file .env \
meltano/meltano init <yourprojectname>
除了知曉 meltano init 之外,最好掌握 Meltano 部分命令,例如 meltano etl 表示 ETL 的執行,meltano invoke <plugin> 來呼叫外掛命令。詳細可以參考它的速查表 http://docs.meltano.com/reference/command-line-interface。
Meltano GUI 介面
Meltano 自帶一個基於 Web 的 UI,執行 ui 子命令就能啟動它:
meltano ui
它預設會跑在 http://localhost:5000 上。
針對 Docker 的執行環境,在暴露 5000 埠的情況下執行容器即可。由於容器的預設命令已經是 meltano ui,所以 run 的命令只需:
docker run -v "$(pwd)":/project \
-w /project \
-p 5000:5000 \
meltano/meltano
Meltano 專案示例
GitHub 使用者 Pat Nadolny 在開源專案 singer_dbt_jaffle 中做了很好的示例。他採用 dbt 的 Meltano 示例資料集,利用 Airflow 編排 ETL 任務。
不只這樣,他還有利用 Superset 的例子,見 jaffle_superset。
前人種樹我們來吃果,按照 Pat Nadolny 的實踐,我們可以這樣地執行資料管道(pipeline):
- tap-CSV(Singer)從 CSV 檔案中提取資料
- target-postgres(Singer) 將資料載入到 Postgres
- dbt 將資料轉換為聚合表或檢視
注意,上面我們已經啟動了 Postgres,可以跳過容器啟動 Postgres 這步。
操作過程是:
git clone http://github.com/pnadolny13/meltano_example_implementations.git
cd meltano_example_implementations/meltano_projects/singer_dbt_jaffle/
meltano install
touch .env
echo PG_PASSWORD="lineage_ref" >> .env
echo PG_USERNAME="lineage_ref" >> .env
# Extract and Load(with Singer)
meltano run tap-csv target-postgres
# Trasnform(with dbt)
meltano run dbt:run
# Generate dbt docs
meltano invoke dbt docs generate
# Serve generated dbt docs
meltano invoke dbt docs to serve
# Then visit http://localhost:8080
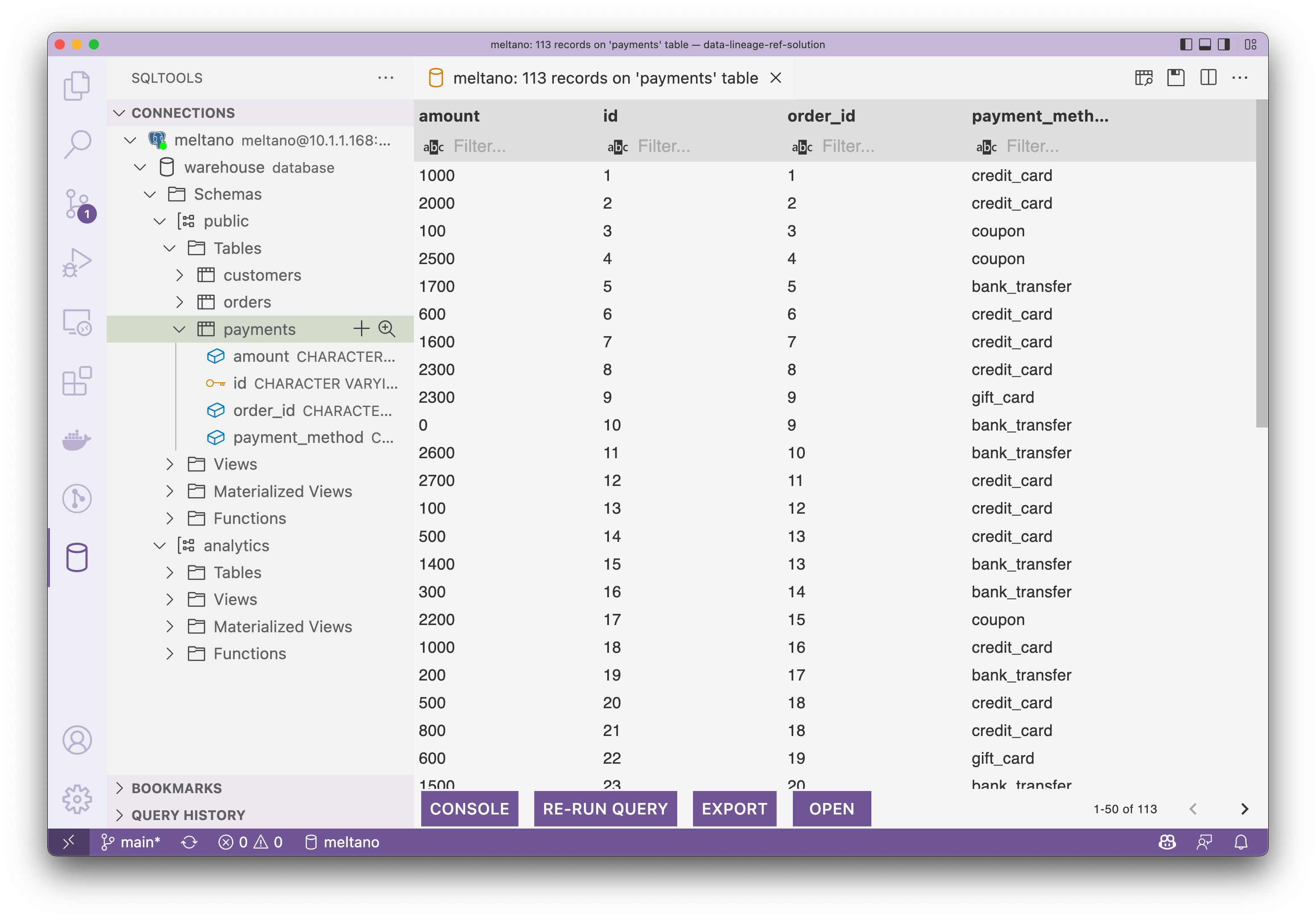
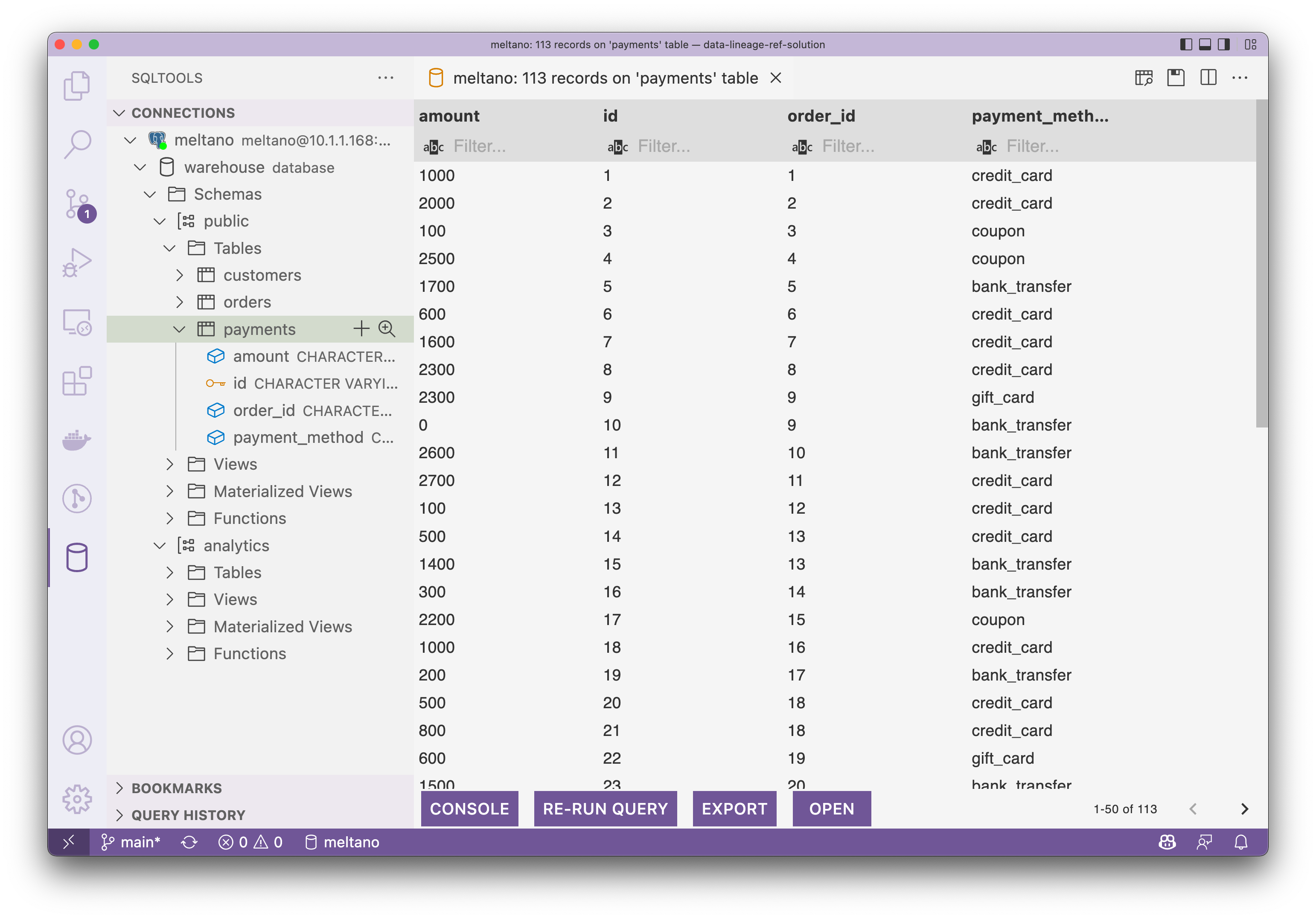
現在,我們可以連線到 Postgres 來檢視載入和轉換後的資料預覽。如下所示,截圖來自 VS Code 的 SQLTool。
payments 表裡長這樣子:
搭一個 BI Dashboard 系統
現在,我們的資料倉庫有資料了。接下來,可以試著用下這些資料。
像儀表盤 Dashbaord 這樣的 BI 工具能幫我們從資料中獲得有用的洞察。使用視覺化工具 Apache Superset 可以很容易地建立和管理這些基於資料來源的 Dashboard 和各式各樣的圖表。
本章的重點不在於 Apache Superset 本身,所以,咱們還是複用 Pat Nadolny 的 jaffle_superset 例子。
Bootstrap Meltano 和 Superset
建立一個安裝了 Meltano 的 Python VENV:
mkdir .venv
python3 -m venv .venv/meltano
source .venv/meltano/bin/activate
python3 -m pip install wheel
python3 -m pip install meltano
參考 Pat 的小抄,做一些細微的調整:
克隆 repo,進入 jaffle_superset 專案:
git clone http://github.com/pnadolny13/meltano_example_implementations.git
cd meltano_example_implementations/meltano_projects/jaffle_superset/
修改 meltano 配置檔案,讓 Superset 連線到我們建立的 Postgres:
vim meltano_projects/jaffle_superset/meltano.yml
這裡,我將主機名更改為“10.1.1.111”,這是我當前主機的 IP。如果你是 Windows 或者 macOS 上的 Docker Desktop,這裡不要修改主機名,否則就要和我一樣手動改成實際地址:
--- a/meltano_projects/jaffle_superset/meltano.yml
+++ b/meltano_projects/jaffle_superset/meltano.yml
@@ -71,7 +71,7 @@ plugins:
A list of database driver dependencies can be found here http://superset.apache.org/docs/databases/installing-database-drivers
config:
database_name: my_postgres
- sqlalchemy_uri: postgresql+psycopg2://${PG_USERNAME}:${PG_PASSWORD}@host.docker.internal:${PG_PORT}/${PG_DATABASE}
+ sqlalchemy_uri: postgresql+psycopg2://${PG_USERNAME}:${PG_PASSWORD}@10.1.1.168:${PG_PORT}/${PG_DATABASE}
tables:
- model.my_meltano_project.customers
- model.my_meltano_project.orders
新增 Postgres 登入的資訊到 .env 檔案:
echo PG_USERNAME=lineage_ref >> .env
echo PG_PASSWORD=lineage_ref >> .env
安裝 Meltano 專案,執行 ETL 任務:
meltano install
meltano run tap-csv target-postgres dbt:run
呼叫、啟動 Superset,這裡注意 ui 不是 meltano 的內部命令,而是一個配置進去的自定義行為(user-defined action):
meltano invoke superset:ui
在另一個命令列終端執行自定義的命令 load_datasources:
meltano invoke superset:load_datasources
通過瀏覽器訪問 http://localhost:8088/ 就是 Superset 的圖形介面了:
建立一個 Dashboard
現在,我們站在 Meltano、Postgres 的肩膀上,用 ETL 資料建一個 Dashboard 吧:
點選 + DASHBOARD,填寫儀表盤名稱,再先後點選 SAVE 和 + CREATE A NEW CHART:
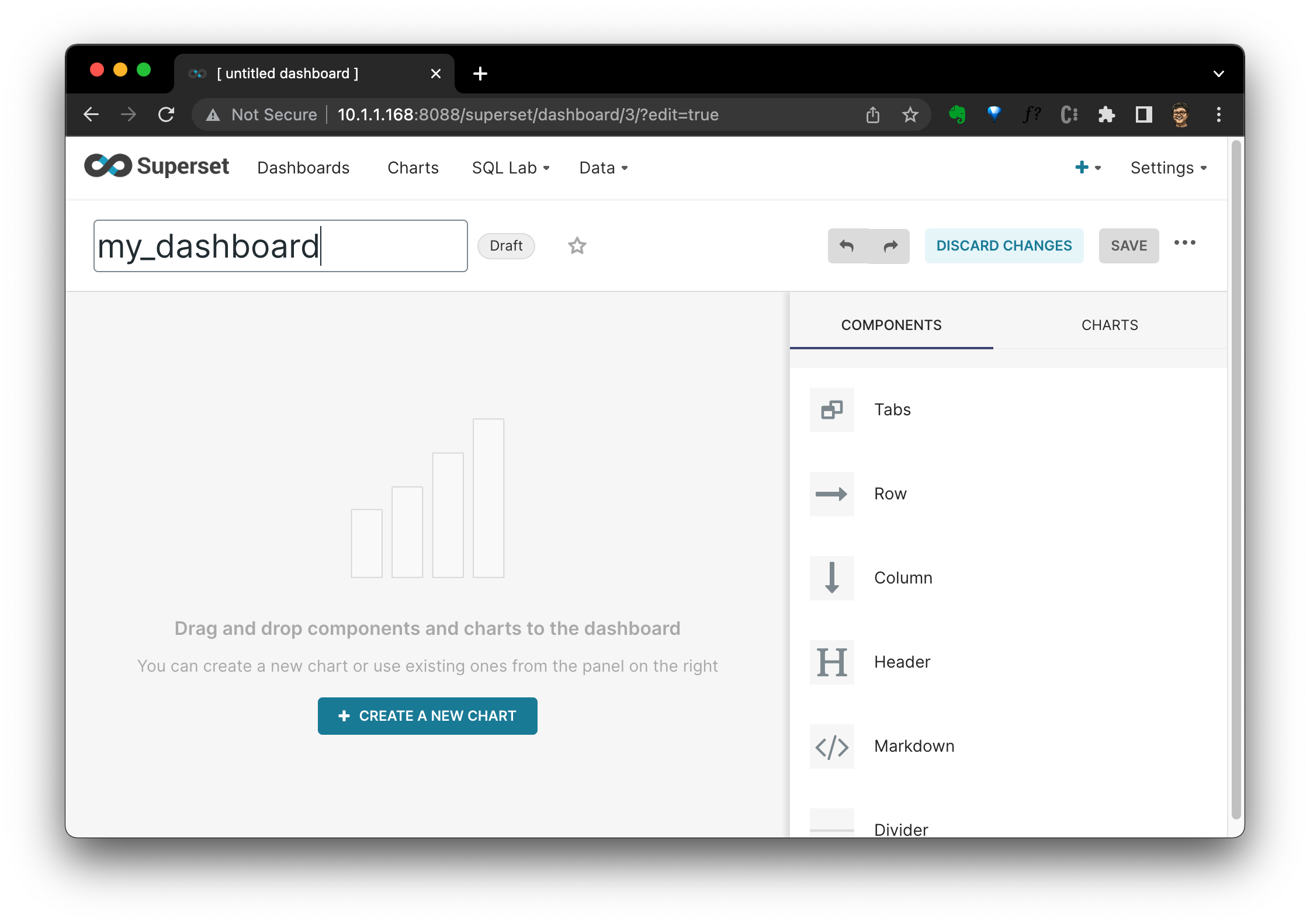
在新圖表(Create a new chart)檢視中,選擇圖表型別和資料集。在這裡,我選擇了 orders 表作為資料來源和 Pie Chart 圖表型別:
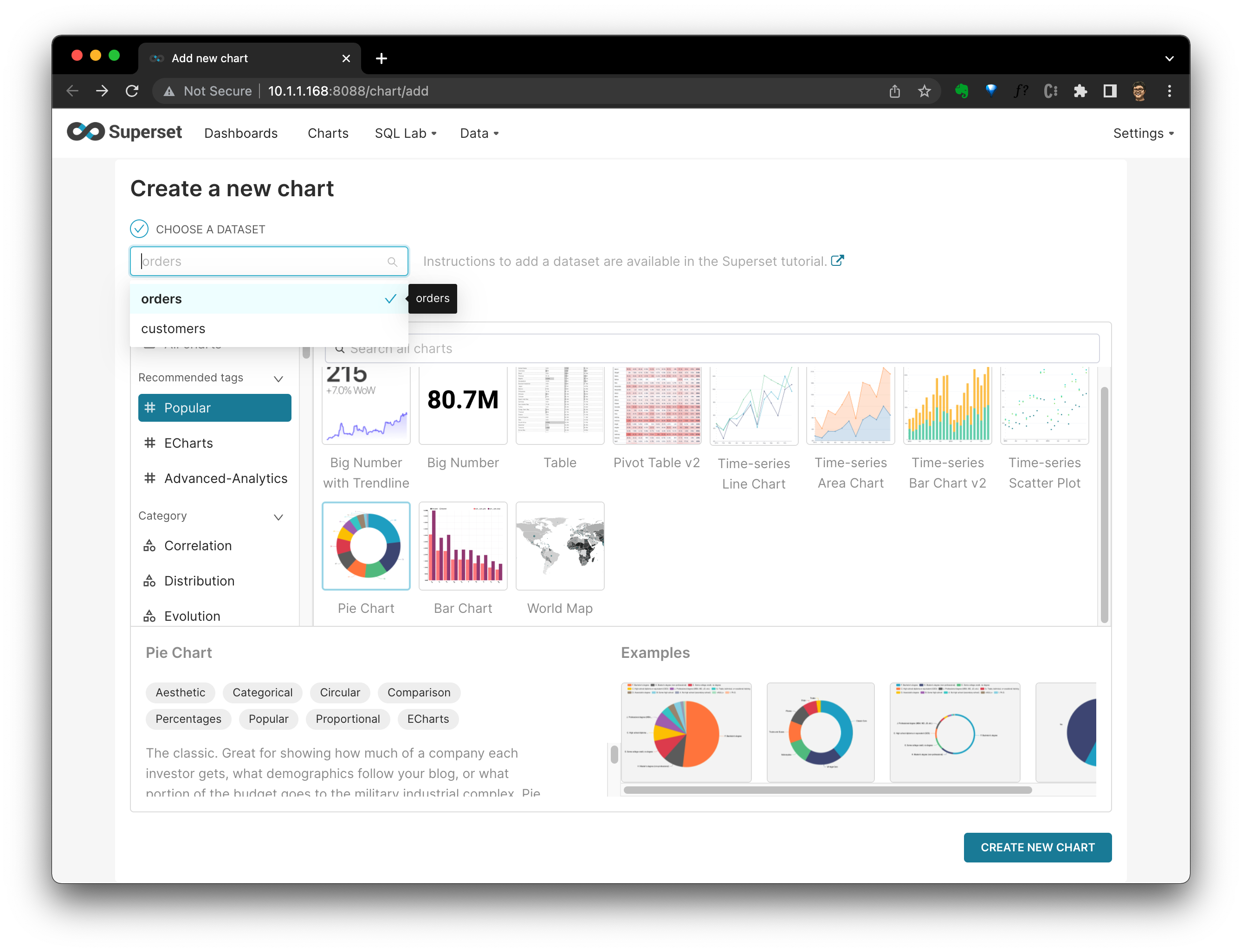
點選 CREATE NEW CHART 後,在圖表定義檢視中選擇 “status” 的 “Query” 為 “DIMENSIONS”,“COUNT(amount)” 為 “METRIC”。至此,咱們就可以看到每個訂單狀態分佈的餅圖了。

點選 SAVE,系統會詢問應該將此圖表新增到哪個 Dashboard。選擇後,單擊 SAVE & GO TO DASHBOARD。
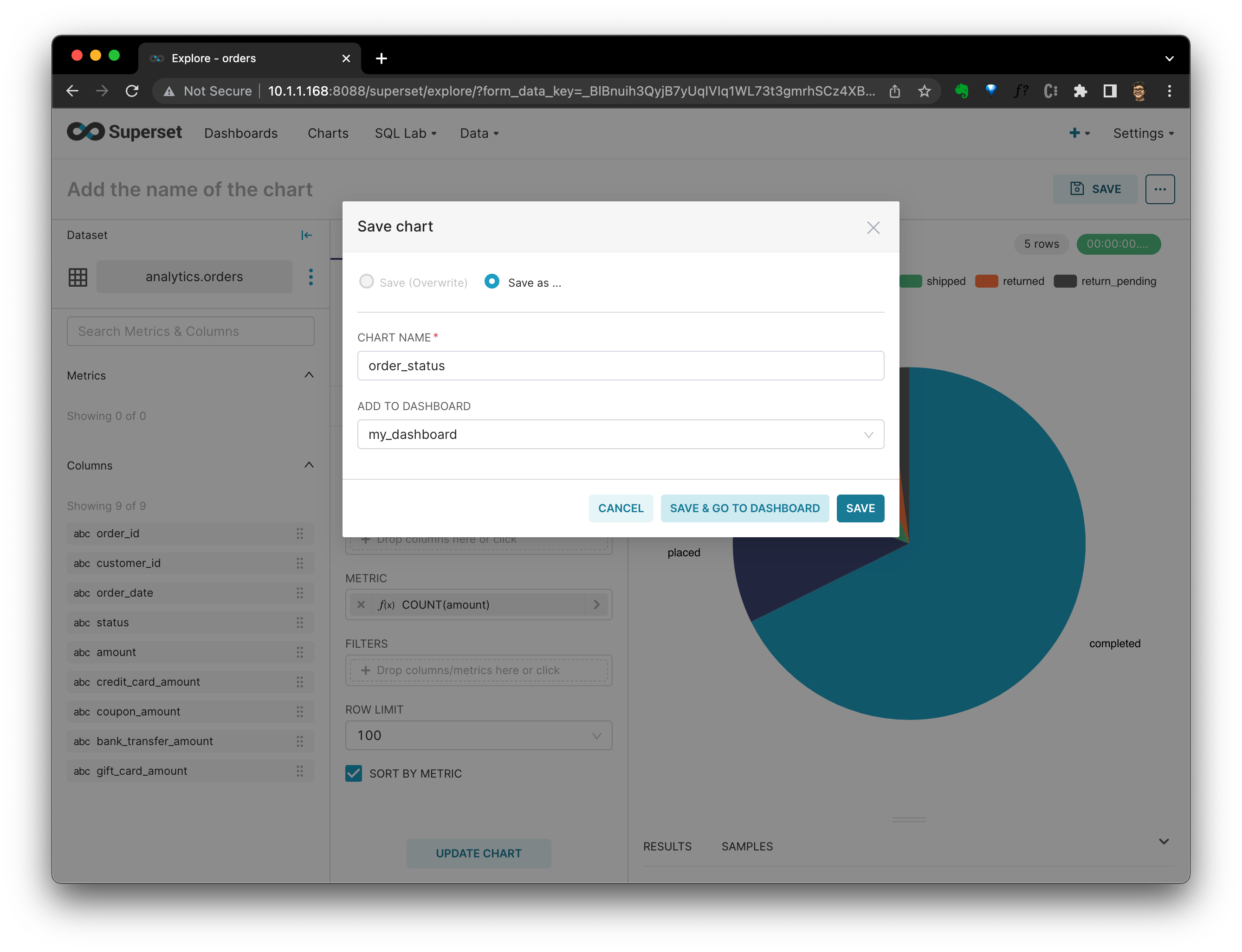
在 Dashboard 中,我們可以看到所有的圖表。這不,你可以看到我額外新增的、用來顯示客戶訂單數量分佈的圖表:
點 ··· 能看到重新整理率設定、下載渲染圖等其他的功能。
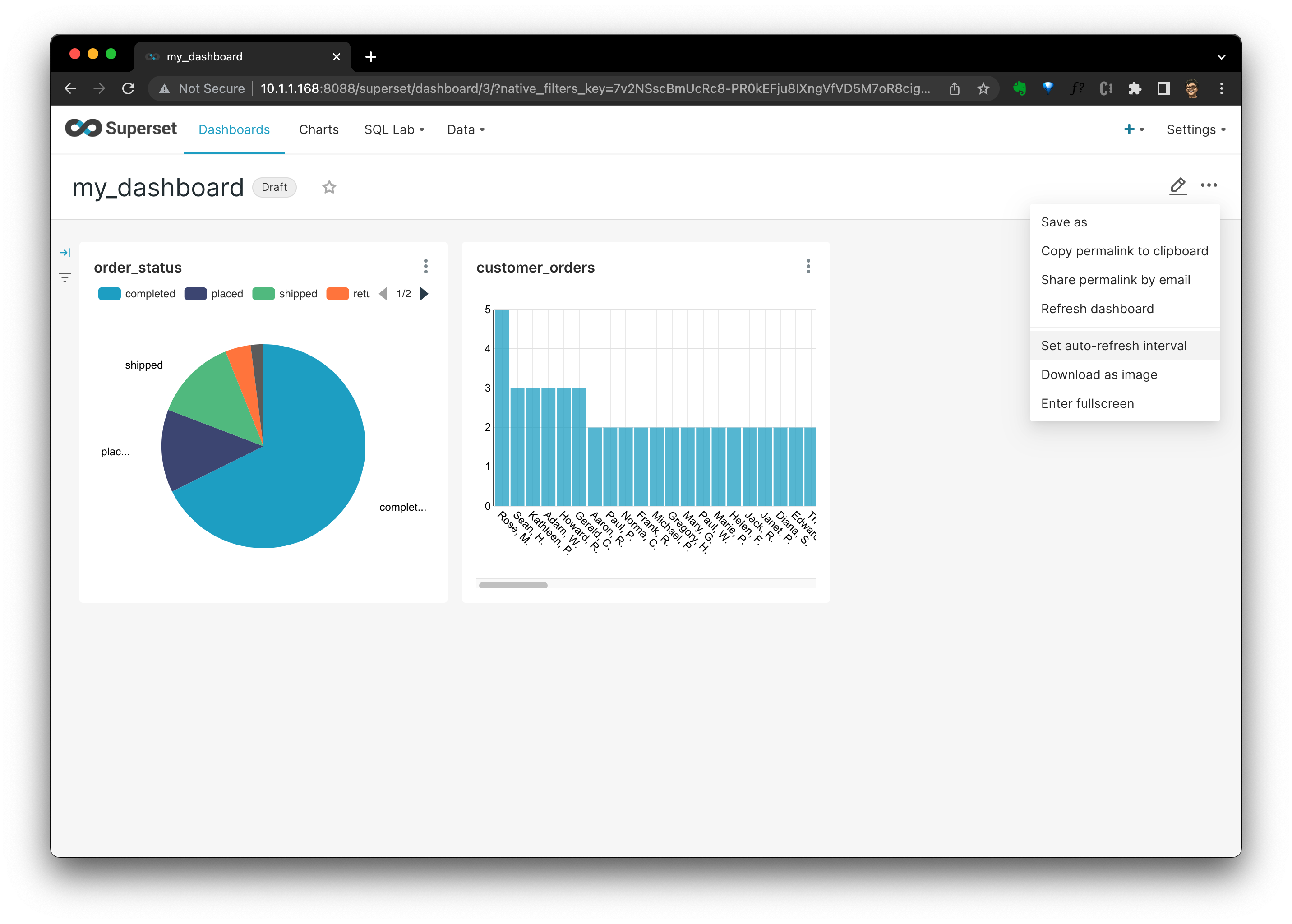
現在,我們有一個簡單但典型的 HomeLAB 資料技術棧了,並且所有東西都是開源的!
想象一下,我們在 CSV 中有 100 個數據集,在資料倉庫中有 200 個表,並且有幾個資料工程師在執行不同的專案,這些專案使用、生成不同的應用與服務、Dashbaord 和資料庫。當有人想要查詢、發現或者修改其中的一些表、資料集、Dashbaord 和管道,在溝通和工程方面可能都是非常不好管理的。
上面我們提到,這個示例專案的主要功能是元資料發現系統。
元資料發現系統
現在,需要我們部署一個帶有 NebulaGraph 和 Elasticsearch 的 Amundsen。有了 Amundsen,我們可以在一個地方發現和管理整個資料棧中的所有元資料。
Amundsen 主要有兩個部分組成:
- 元資料匯入 Metadata Ingestion
- 元資料目錄服務 Metadata Catalog
它的工作原理是:利用 Databuilder 提取不同資料來源的元資料,並將元資料持久化到 Metadata Service 和 Search Service 中,使用者從 Frontend Service 或 Metadata Service 的 API 獲取資料。
部署 Amundsen
元資料服務 Metadata Service
我們用 docker-compose 部署一個 Amundsen 叢集。由於 Amundsen 對 NebulaGraph 後端的支援 pr#1817 尚未合併,還不能用官方的程式碼。這裡,先用我的 fork 版本。
先克隆包含所有子模組的 repo:
git clone -b amundsen_nebula_graph --recursive [email protected]:wey-gu/amundsen.git
cd amundsen
啟動所有目錄服務 catalog services 及其後端儲存:
docker-compose -f docker-amundsen-nebula.yml up
由於這個 docker-compose 檔案是供開發人員試玩、除錯 Amundsen 用的,而不是給生產部署準備的,它在啟動的時候會從程式碼庫構建映象,第一次跑的時候啟動會慢一些。
部署好了之後,我們使用 Databuilder 將一些示例、虛構的資料載入儲存裡。
抓取元資料 Databuilder
Amundsen Databuilder 就像 Meltano 系統一樣,只不過是用在元資料的上的 ETL ,它把元資料載入到 Metadata Service 和 Search Service 的後端儲存:NebulaGraph 和 Elasticsearch 裡。這裡的 Databuilder 只是一個 Python 模組,所有的元資料 ETL 作業可以作為指令碼執行,也可以用 Apache Airflow 等 DAG 平臺進行編排。
cd databuilder
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install wheel
python3 -m pip install -r requirements.txt
python3 setup.py install
呼叫這個示例資料構建器 ETL 指令碼來把示例的虛擬資料導進去。
python3 example/scripts/sample_data_loader_nebula.py
驗證一下 Amundsen
在訪問 Amundsen 之前,我們需要建立一個測試使用者:
# run a container with curl attached to amundsenfrontend
docker run -it --rm --net container:amundsenfrontend nicolaka/netshoot
# Create a user with id test_user_id
curl -X PUT -v http://amundsenmetadata:5002/user \
-H "Content-Type: application/json" \
--data \
'{"user_id":"test_user_id","first_name":"test","last_name":"user", "email":"[email protected]"}'
exit
然後我們可以在 http://localhost:5000 檢視 UI 並嘗試搜尋 test,它應該會返回一些結果。
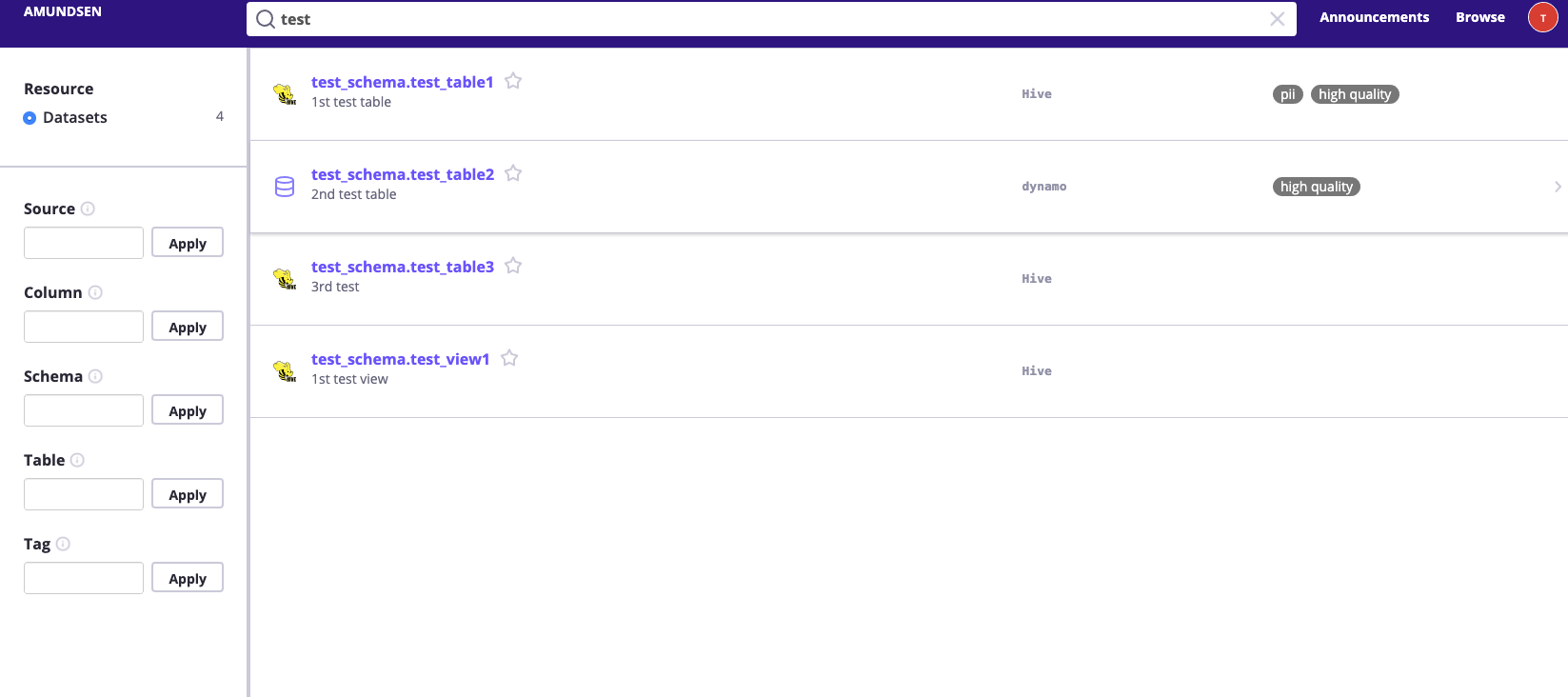
然後,可以單擊並瀏覽在 sample_data_loader_nebula.py 期間載入到 Amundsen 的那些示例元資料。
此外,我們還可以通過 NebulaGraph Studio 的地址 http://localhost:7001 訪問 NebulaGraph 裡的這些資料。
下圖顯示了有關 Amundsen 元件的更多詳細資訊:
┌────────────────────────┐ ┌────────────────────────────────────────┐
│ Frontend:5000 │ │ Metadata Sources │
├────────────────────────┤ │ ┌────────┐ ┌─────────┐ ┌─────────────┐ │
│ Metaservice:5001 │ │ │ │ │ │ │ │ │
│ ┌──────────────┐ │ │ │ Foo DB │ │ Bar App │ │ X Dashboard │ │
┌────┼─┤ Nebula Proxy │ │ │ │ │ │ │ │ │ │
│ │ └──────────────┘ │ │ │ │ │ │ │ │ │
│ ├────────────────────────┤ │ └────────┘ └─────┬───┘ └─────────────┘ │
┌─┼────┤ Search searvice:5002 │ │ │ │
│ │ └────────────────────────┘ └──────────────────┼─────────────────────┘
│ │ ┌─────────────────────────────────────────────┼───────────────────────┐
│ │ │ │ │
│ │ │ Databuilder ┌───────────────────────────┘ │
│ │ │ │ │
│ │ │ ┌───────────────▼────────────────┐ ┌──────────────────────────────┐ │
│ │ ┌──┼─► Extractor of Sources ├─► nebula_search_data_extractor │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ │ ┌───────────────▼────────────────┐ ┌──────────────▼───────────────┐ │
│ │ │ │ │ Loader filesystem_csv_nebula │ │ Loader Elastic FS loader │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ │ ┌───────────────▼────────────────┐ ┌──────────────▼───────────────┐ │
│ │ │ │ │ Publisher nebula_csv_publisher │ │ Publisher Elasticsearch │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ └─────────────────┼─────────────────────────────────┼─────────────────┘
│ │ └────────────────┐ │ │
│ │ ┌─────────────┼───►─────────────────────────┐ ┌─────▼─────┐
│ │ │ NebulaGraph │ │ │ │ │
│ └────┼─────┬───────┴───┼───────────┐ ┌─────┐ │ │ │
│ │ │ │ │ │MetaD│ │ │ │
│ │ ┌───▼──┐ ┌───▼──┐ ┌───▼──┐ └─────┘ │ │ │
│ ┌────┼─►GraphD│ │GraphD│ │GraphD│ │ │ │
│ │ │ └──────┘ └──────┘ └──────┘ ┌─────┐ │ │ │
│ │ │ :9669 │MetaD│ │ │ Elastic │
│ │ │ ┌────────┐ ┌────────┐ ┌────────┐ └─────┘ │ │ Search │
│ │ │ │ │ │ │ │ │ │ │ Cluster │
│ │ │ │StorageD│ │StorageD│ │StorageD│ ┌─────┐ │ │ :9200 │
│ │ │ │ │ │ │ │ │ │MetaD│ │ │ │
│ │ │ └────────┘ └────────┘ └────────┘ └─────┘ │ │ │
│ │ ├───────────────────────────────────────────┤ │ │
│ └────┤ Nebula Studio:7001 │ │ │
│ └───────────────────────────────────────────┘ └─────▲─────┘
└──────────────────────────────────────────────────────────┘
穿針引線:元資料發現
設定好基本環境後,讓我們把所有東西穿起來。還記得我們有 ELT 一些資料到 PostgreSQL 嗎?
那麼,我們如何讓 Amundsen 發現這些資料和 ETL 的元資料呢?
提取 Postgres 元資料
我們從資料來源開始:首先是 Postgres。
我們為 Python3 安裝 Postgres 客戶端:
sudo apt-get install libpq-dev
pip3 install Psycopg2
執行 Postgres 元資料 ETL
執行一個指令碼來解析 Postgres 元資料:
export CREDENTIALS_POSTGRES_USER=lineage_ref
export CREDENTIALS_POSTGRES_PASSWORD=lineage_ref
export CREDENTIALS_POSTGRES_DATABASE=warehouse
python3 example/scripts/sample_postgres_loader_nebula.py
我們看看把 Postgres 元資料載入到 NebulaGraph 的示例指令碼的程式碼,非常簡單直接:
# part 1: PostgresMetadata --> CSV --> NebulaGraph
job = DefaultJob(
conf=job_config,
task=DefaultTask(
extractor=PostgresMetadataExtractor(),
loader=FsNebulaCSVLoader()),
publisher=NebulaCsvPublisher())
...
# part 2: Metadata stored in NebulaGraph --> Elasticsearch
extractor = NebulaSearchDataExtractor()
task = SearchMetadatatoElasticasearchTask(extractor=extractor)
job = DefaultJob(conf=job_config, task=task)
第一個工作路徑是:PostgresMetadata --> CSV --> NebulaGraph
PostgresMetadataExtractor用於從 Postgres 中提取元資料,可以參考文件 http://www.amundsen.io/amundsen/databuilder/#postgresmetadataextractor。FsNebulaCSVLoader用於將提取的資料轉為 CSV 檔案NebulaCsvPublisher用於將元資料以 CSV 格式釋出到 NebulaGraph
第二個工作路徑是:Metadata stored in NebulaGraph --> Elasticsearch
NebulaSearchDataExtractor用於獲取儲存在 NebulaGraph 中的元資料SearchMetadatatoElasticasearchTask用於使 Elasticsearch 對元資料進行索引。
請注意,在生產環境中,我們可以在指令碼中或使用 Apache Airflow 等編排平臺觸發這些作業。
驗證 Postgres 中元資料的獲取
搜尋 payments 或者直接訪問 http://localhost:5000/table_detail/warehouse/postgres/public/payments,你可以看到我們 Postgres 的元資料,比如:
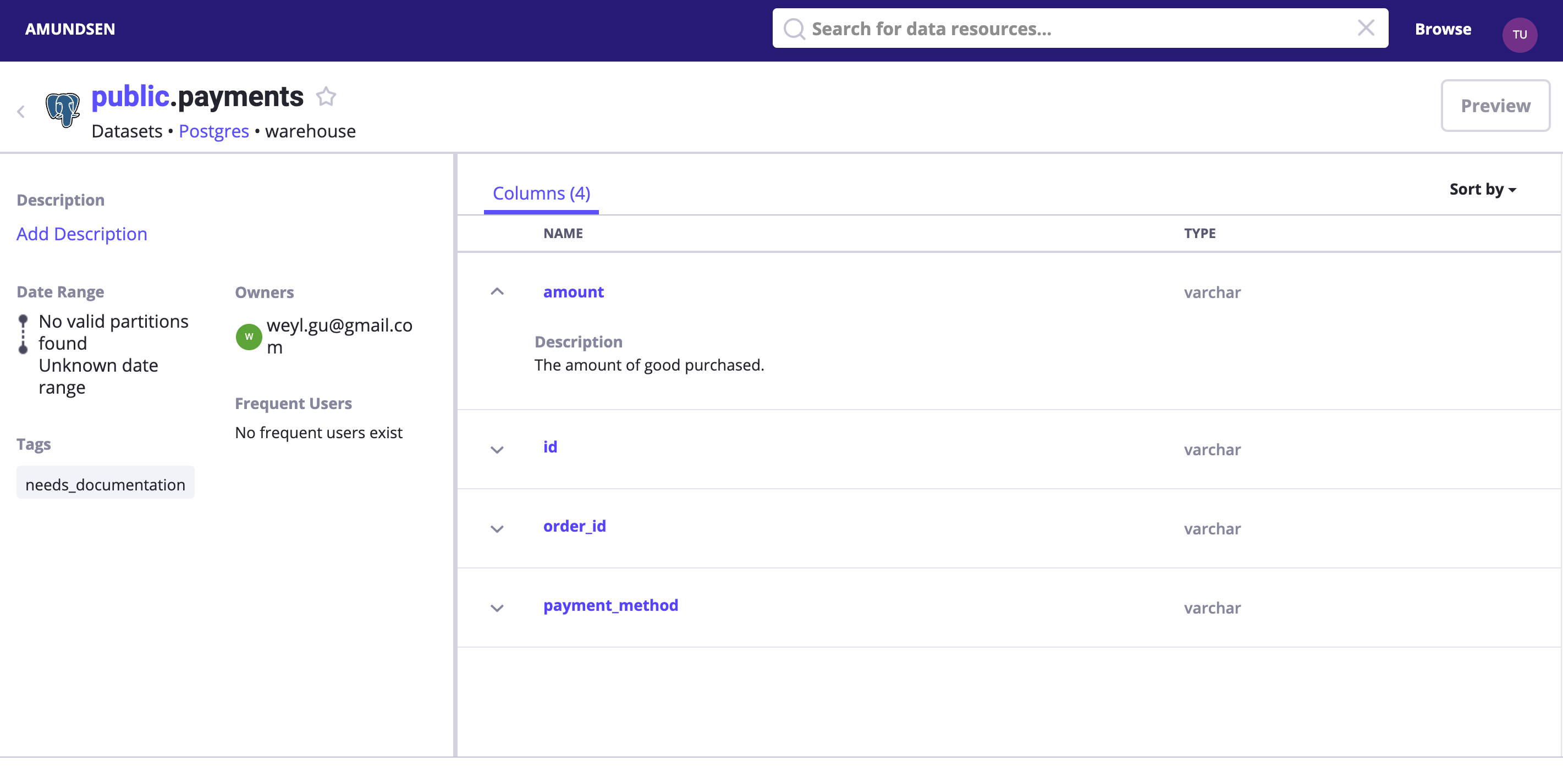
像上面的螢幕截圖一樣,我們可以輕鬆完成元資料管理操作,如:新增標籤、所有者和描述。
提取 dbt 元資料
其實,我們也可以從 dbt 本身提取元資料。
Amundsen DbtExtractor 會解析 catalog.json 或 manifest.json 檔案並將元資料載入到 Amundsen 儲存,這裡當然指的是 NebulaGraph 和 Elasticsearch。
在上面的 Meltano 章節中,我們已經使用 meltano invoke dbt docs generate 生成了這個檔案:
14:23:15 Done.
14:23:15 Building catalog
14:23:15 Catalog written to /home/ubuntu/ref-data-lineage/meltano_example_implementations/meltano_projects/singer_dbt_jaffle/.meltano/transformers/dbt/target/catalog.json
dbt 元資料 ETL 的執行
我們試著解析示例 dbt 檔案中的元資料吧:
$ ls -l example/sample_data/dbt/
total 184
-rw-rw-r-- 1 w w 5320 May 15 07:17 catalog.json
-rw-rw-r-- 1 w w 177163 May 15 07:17 manifest.json
我寫的這個示例的載入例子如下:
python3 example/scripts/sample_dbt_loader_nebula.py
其中主要的程式碼如下:
# part 1: dbt manifest --> CSV --> NebulaGraph
job = DefaultJob(
conf=job_config,
task=DefaultTask(
extractor=DbtExtractor(),
loader=FsNebulaCSVLoader()),
publisher=NebulaCsvPublisher())
...
# part 2: Metadata stored in NebulaGraph --> Elasticsearch
extractor = NebulaSearchDataExtractor()
task = SearchMetadatatoElasticasearchTask(extractor=extractor)
job = DefaultJob(conf=job_config, task=task)
它和 Postgres 元資料 ETL 的唯一區別是 extractor=DbtExtractor(),它帶有以下配置以獲取有關 dbt 專案的以下資訊:
- 資料庫名稱
- 目錄_json
- manifest_json
job_config = ConfigFactory.from_dict({
'extractor.dbt.database_name': database_name,
'extractor.dbt.catalog_json': catalog_file_loc, # File
'extractor.dbt.manifest_json': json.dumps(manifest_data), # JSON Dumped objecy
'extractor.dbt.source_url': source_url})
驗證 dbt 抓取結果
搜尋 dbt_demo 或者直接訪問 http://localhost:5000/table_detail/dbt_demo/snowflake/public/raw_inventory_value,可以看到
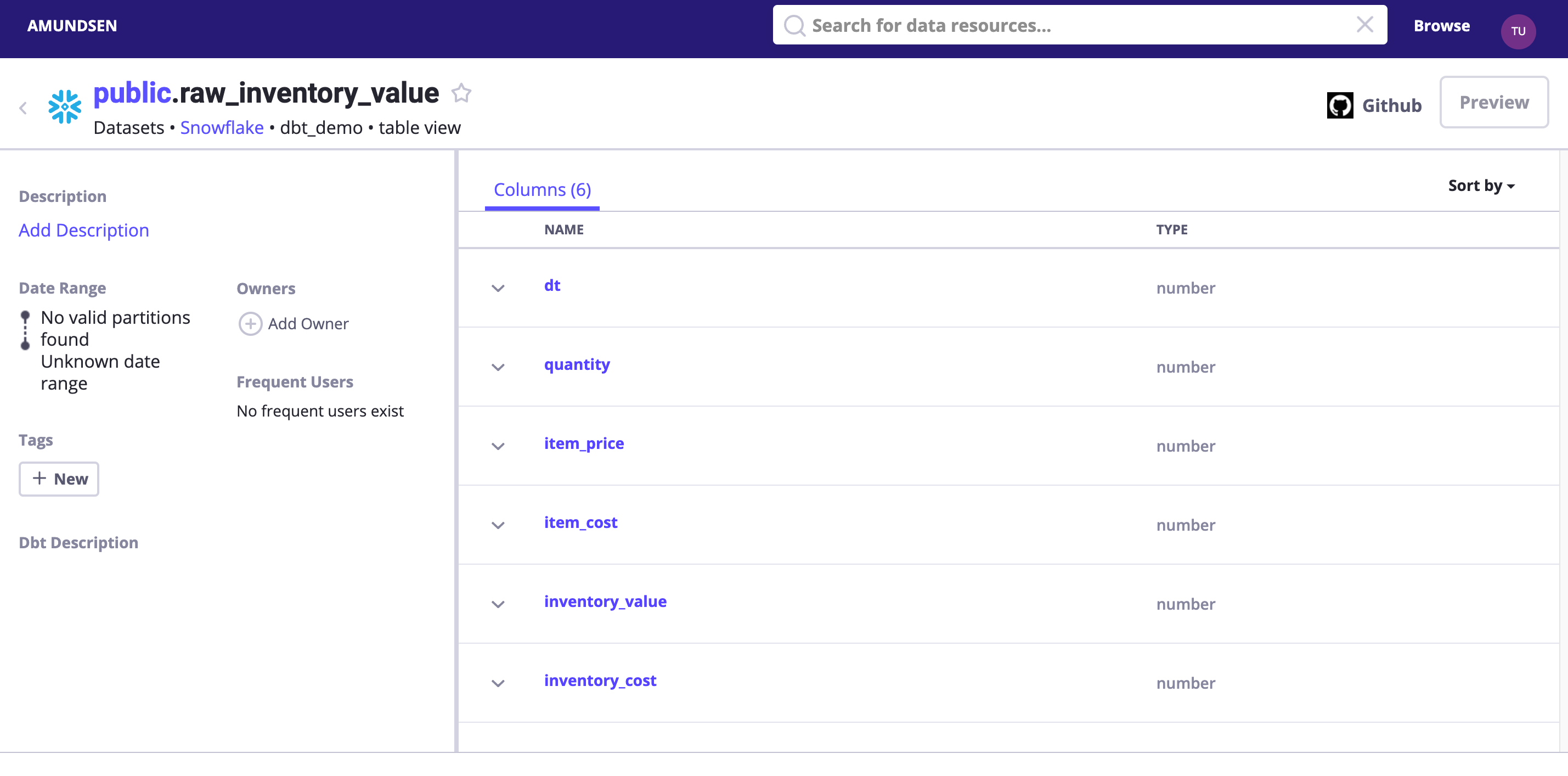
這裡給一個小提示,其實,我們可以選擇啟用 DEBUG log 級別去看已傳送到 Elasticsearch 和 NebulaGraph 的內容。
- logging.basicConfig(level=logging.INFO)
+ logging.basicConfig(level=logging.DEBUG)
或者,在 NebulaGraph Studio 中探索匯入的資料:
先點選 Start with Vertices,並填寫頂點 vid:snowflake://dbt_demo.public/fact_warehouse_inventory
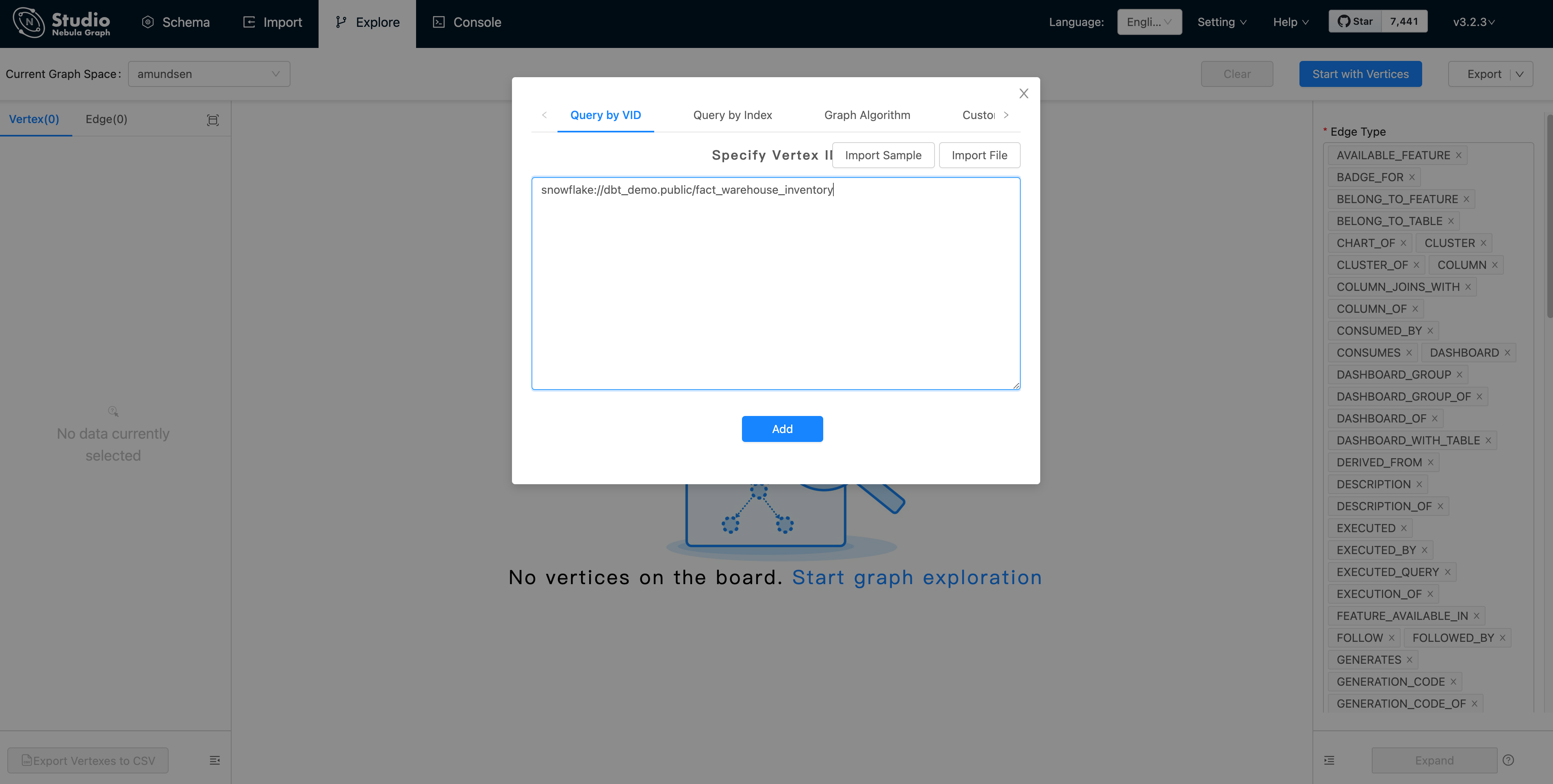
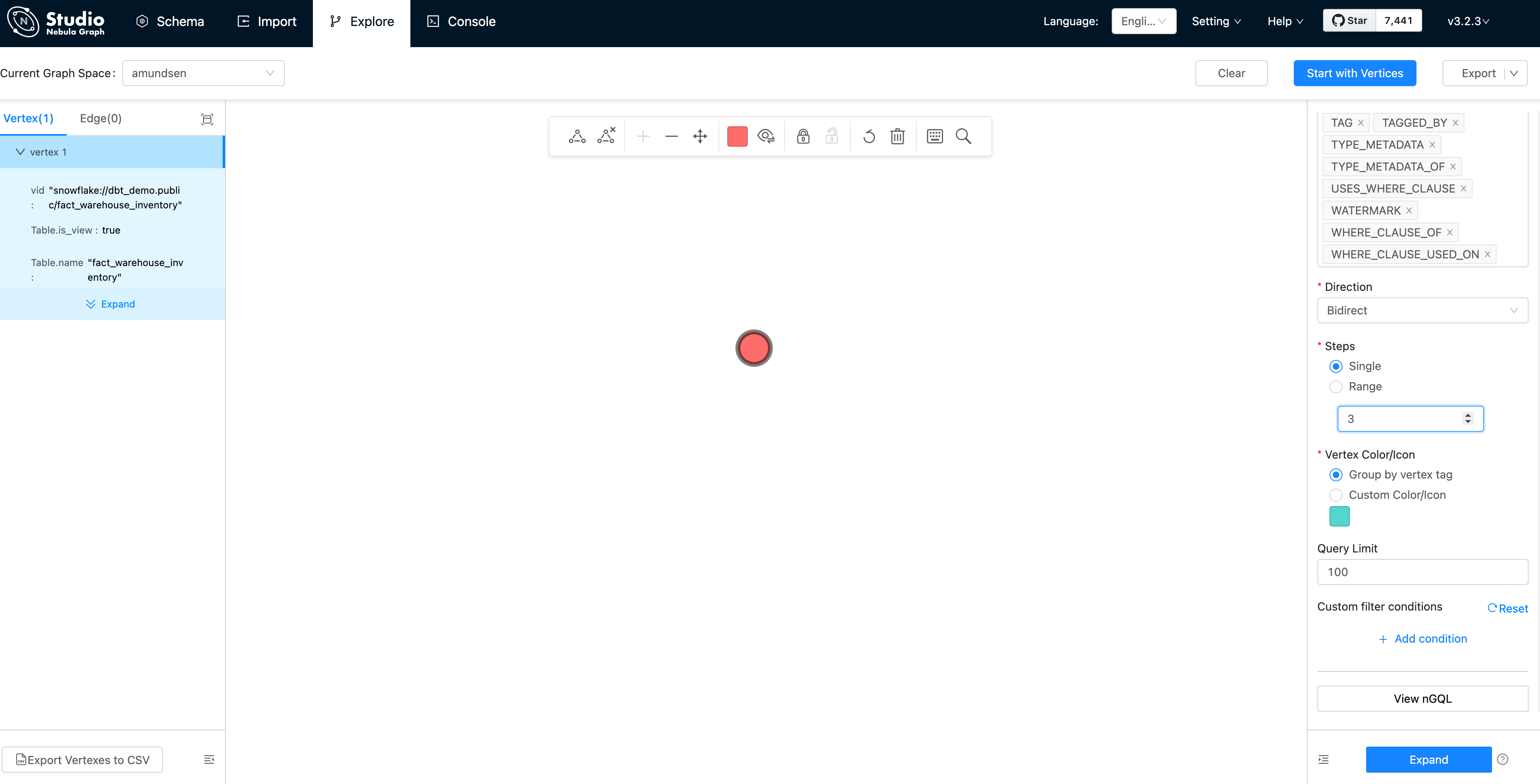
我們可以看到頂點顯示為粉紅色的點。再讓我們修改下 Expand / ”拓展“選項:
- 方向:雙向
- 步數:單向、三步
並雙擊頂點(點),它將雙向拓展 3 步:
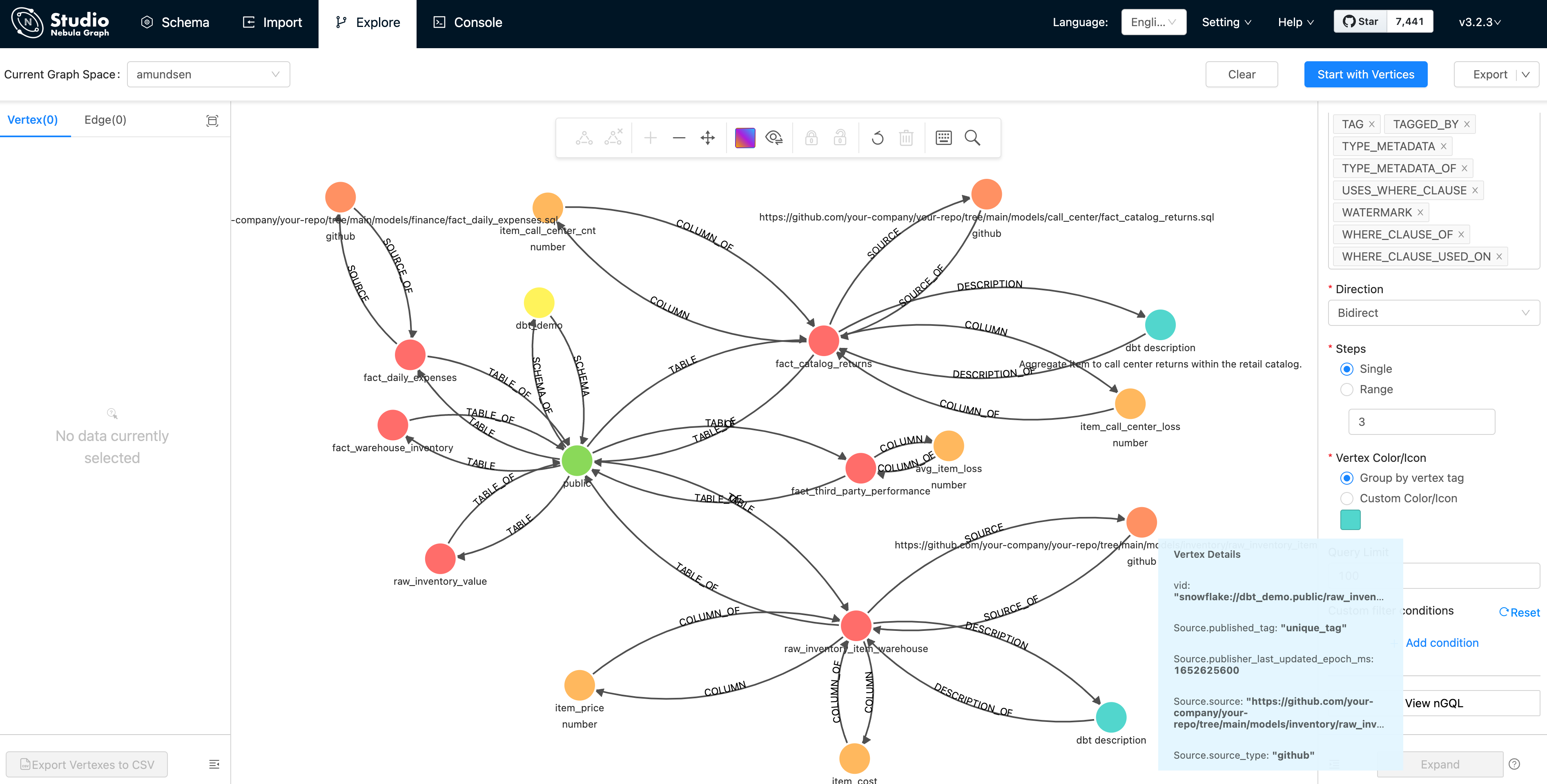
像截圖展示的那般,在視覺化之後的圖資料庫中,這些元資料可以很容易被檢視、分析,並從中獲得洞察。
而且,我們在 NebulaGraph Studio 中看到的同 Amundsen 元資料服務的資料模型相呼應:
最後,請記住我們曾利用 dbt 來轉換 Meltano 中的一些資料,並且清單檔案路徑是 .meltano/transformers/dbt/target/catalog.json,你可以嘗試建立一個數據構建器作業來匯入它。
提取 Superset 中的元資料
Amundsen 的 Superset Extractor 可以獲取
- Dashboard 元資料抽取,見 apache_superset_metadata_extractor.py
- 圖表元資料抽取,見 apache_superset_chart_extractor.py
- Superset 元素與資料來源(表)的關係抽取,見 apache_superset_table_extractor.py
來,現在試試提取之前建立的 Superset Dashboard 的元資料。
Superset 元資料 ETL 的執行
下邊執行的示例 Superset 提取指令碼可以獲取資料並將元資料載入到 NebulaGraph 和 Elasticsearch 中。
python3 sample_superset_data_loader_nebula.py
如果我們將日誌記錄級別設定為 DEBUG,我們實際上可以看到這些中間的過程日誌:
# fetching metadata from superset
DEBUG:urllib3.connectionpool:http://localhost:8088 "POST /api/v1/security/login HTTP/1.1" 200 280
INFO:databuilder.task.task:Running a task
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): localhost:8088
DEBUG:urllib3.connectionpool:http://localhost:8088 "GET /api/v1/dashboard?q=(page_size:20,page:0,order_direction:desc) HTTP/1.1" 308 374
DEBUG:urllib3.connectionpool:http://localhost:8088 "GET /api/v1/dashboard/?q=(page_size:20,page:0,order_direction:desc) HTTP/1.1" 200 1058
...
# insert Dashboard
DEBUG:databuilder.publisher.nebula_csv_publisher:Query: INSERT VERTEX `Dashboard` (`dashboard_url`, `name`, published_tag, publisher_last_updated_epoch_ms) VALUES "superset_dashboard://my_cluster.1/3":("http://localhost:8088/superset/dashboard/3/","my_dashboard","unique_tag",timestamp());
...
# insert a DASHBOARD_WITH_TABLE relationship/edge
INFO:databuilder.publisher.nebula_csv_publisher:Importing data in edge files: ['/tmp/amundsen/dashboard/relationships/Dashboard_Table_DASHBOARD_WITH_TABLE.csv']
DEBUG:databuilder.publisher.nebula_csv_publisher:Query:
INSERT edge `DASHBOARD_WITH_TABLE` (`END_LABEL`, `START_LABEL`, published_tag, publisher_last_updated_epoch_ms) VALUES "superset_dashboard://my_cluster.1/3"->"postgresql+psycopg2://my_cluster.warehouse/orders":("Table","Dashboard","unique_tag", timestamp()), "superset_dashboard://my_cluster.1/3"->"postgresql+psycopg2://my_cluster.warehouse/customers":("Table","Dashboard","unique_tag", timestamp());
驗證 Superset Dashboard 元資料
通過在 Amundsen 中搜索它,我們現在可以獲得 Dashboard 資訊。
我們也可以從 NebulaGraph Studio 進行驗證。
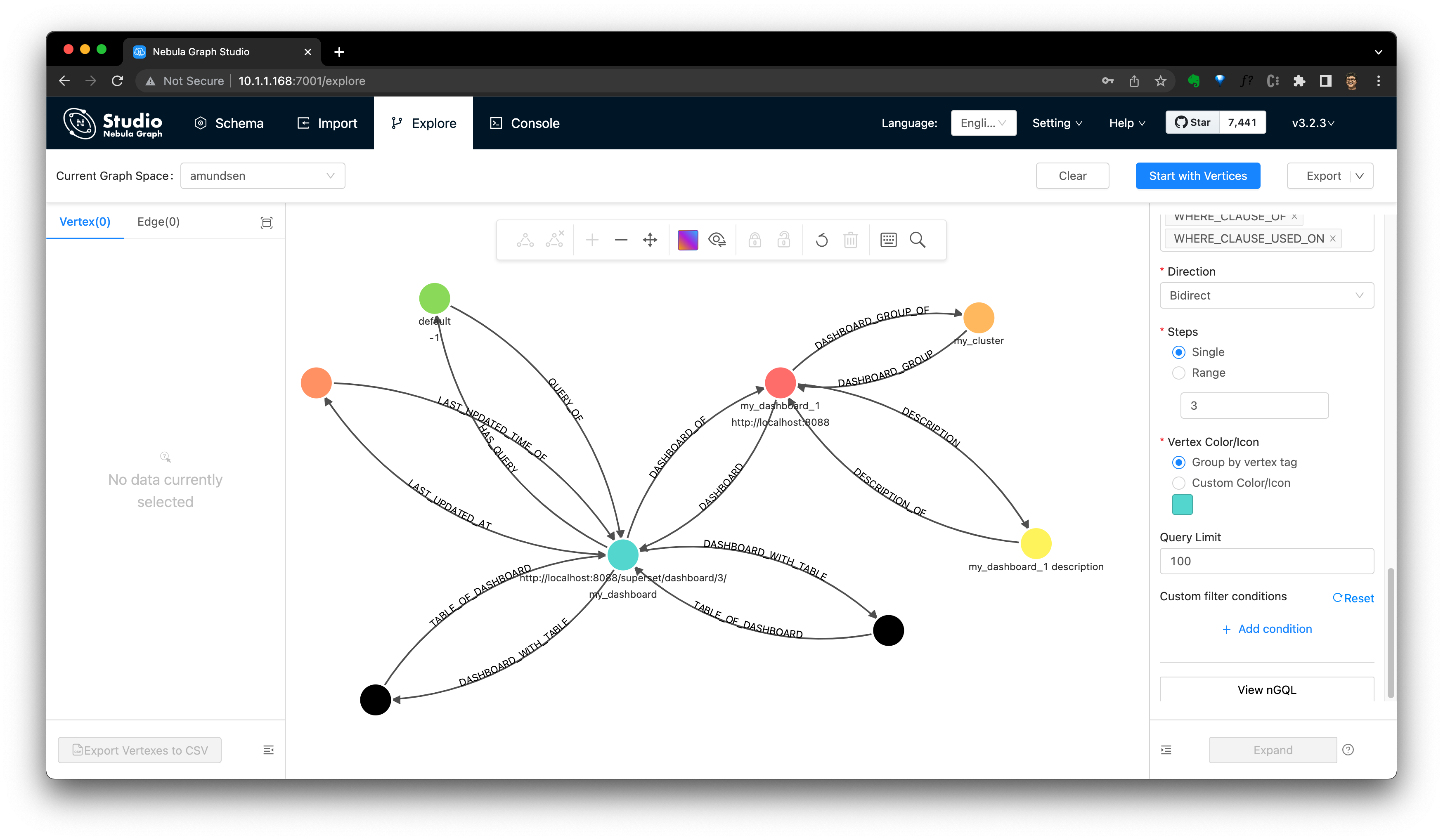
注:可以參閱 Dashboard 抓取指南中的 Amundsen Dashboard 圖建模:
用 Superset 預覽資料
Superset 可以用來預覽表格資料,文件可以參考 http://www.amundsen.io/amundsen/frontend/docs/configuration/#preview-client,其中 /superset/sql_json/ 的 API 被 Amundsen Frontend Service 呼叫,取得預覽資訊。
開啟資料血緣資訊
預設情況下,資料血緣是關閉的,我們可以通過以下方式啟用它:
第一步,cd 到 Amundsen 程式碼倉庫下,這也是我們執行 docker-compose -f docker-amundsen-nebula.yml up 命令的地方:
cd amundsen
第二步,修改 frontend 下的 TypeScript 配置
--- a/frontend/amundsen_application/static/js/config/config-default.ts
+++ b/frontend/amundsen_application/static/js/config/config-default.ts
tableLineage: {
- inAppListEnabled: false,
- inAppPageEnabled: false,
+ inAppListEnabled: true,
+ inAppPageEnabled: true,
externalEnabled: false,
iconPath: 'PATH_TO_ICON',
isBeta: false,
第三步,重新構建 Docker 映象,其中將重建前端影象。
docker-compose -f docker-amundsen-nebula.yml build
第四步,重新執行 up -d 以確保前端用新的配置:
docker-compose -f docker-amundsen-nebula.yml up -d
結果大概長這樣子:
$ docker-compose -f docker-amundsen-nebula.yml up -d
...
Recreating amundsenfrontend ... done
之後,我們可以訪問 http://localhost:5000/lineage/table/gold/hive/test_schema/test_table1 看到 Lineage (beta) 血緣按鈕已經顯示出來了:
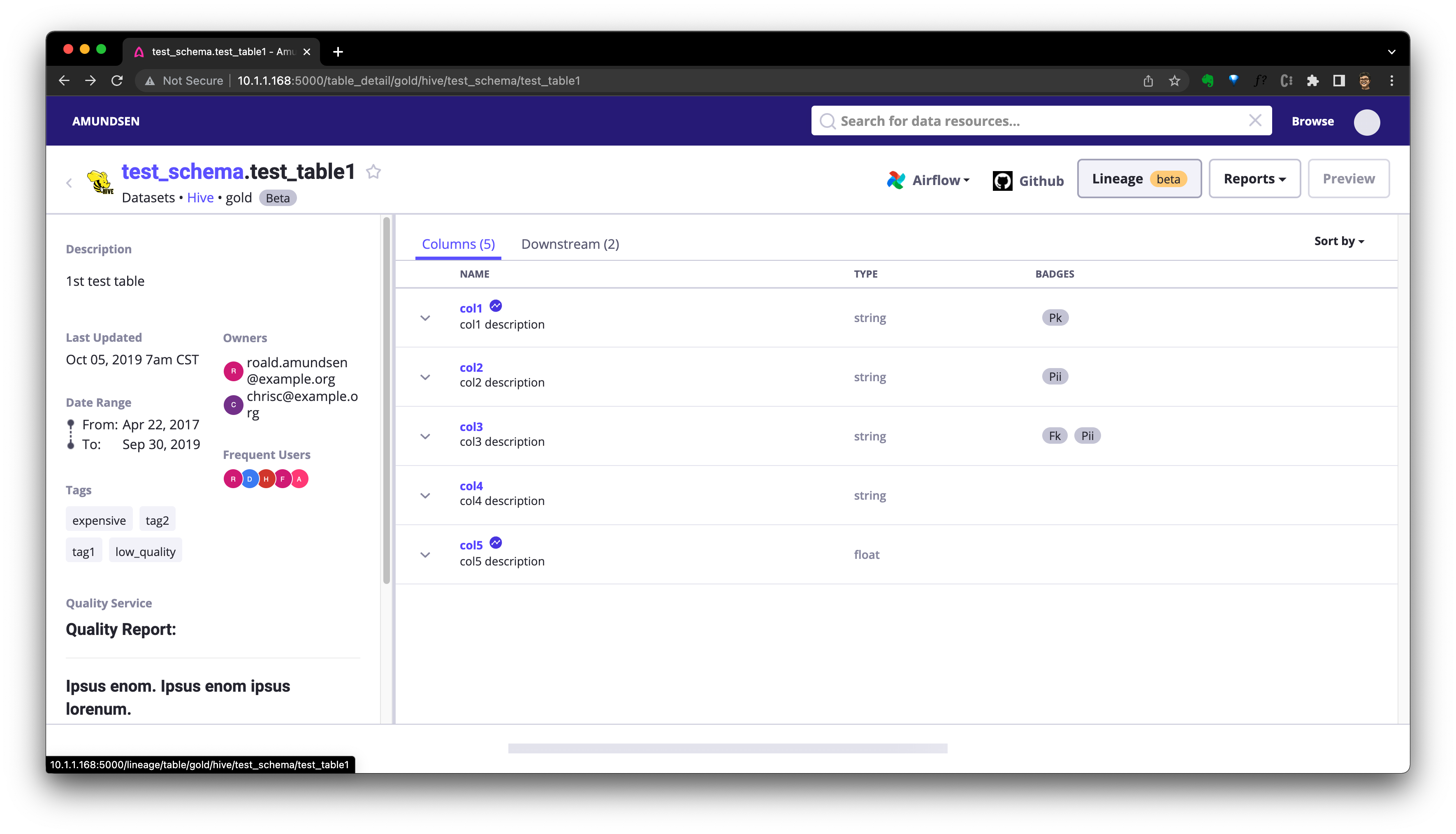
我們可以點選 Downstream 檢視該表的下游資源:
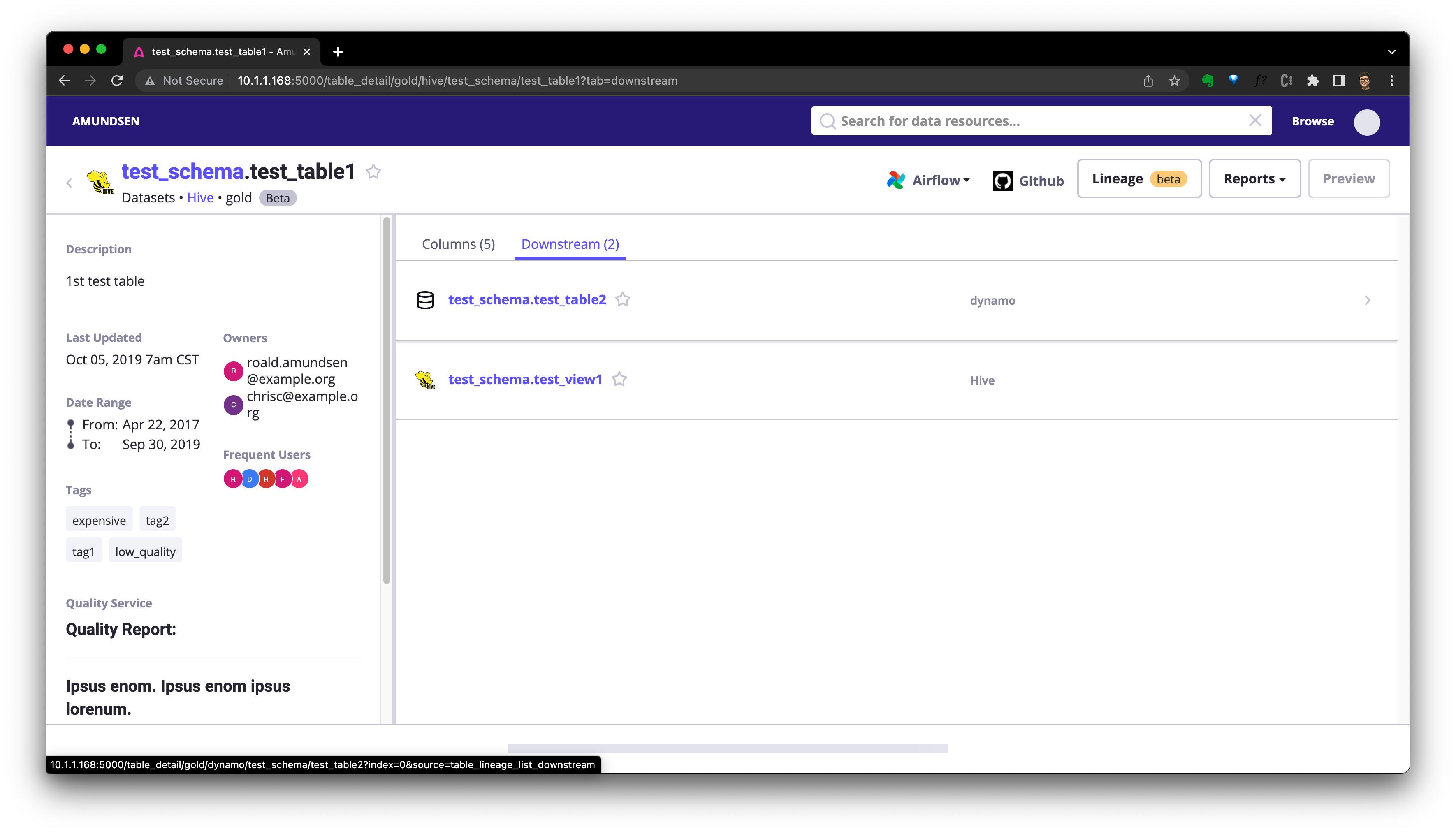
或者點選血緣按鈕檢視血緣的圖表式:
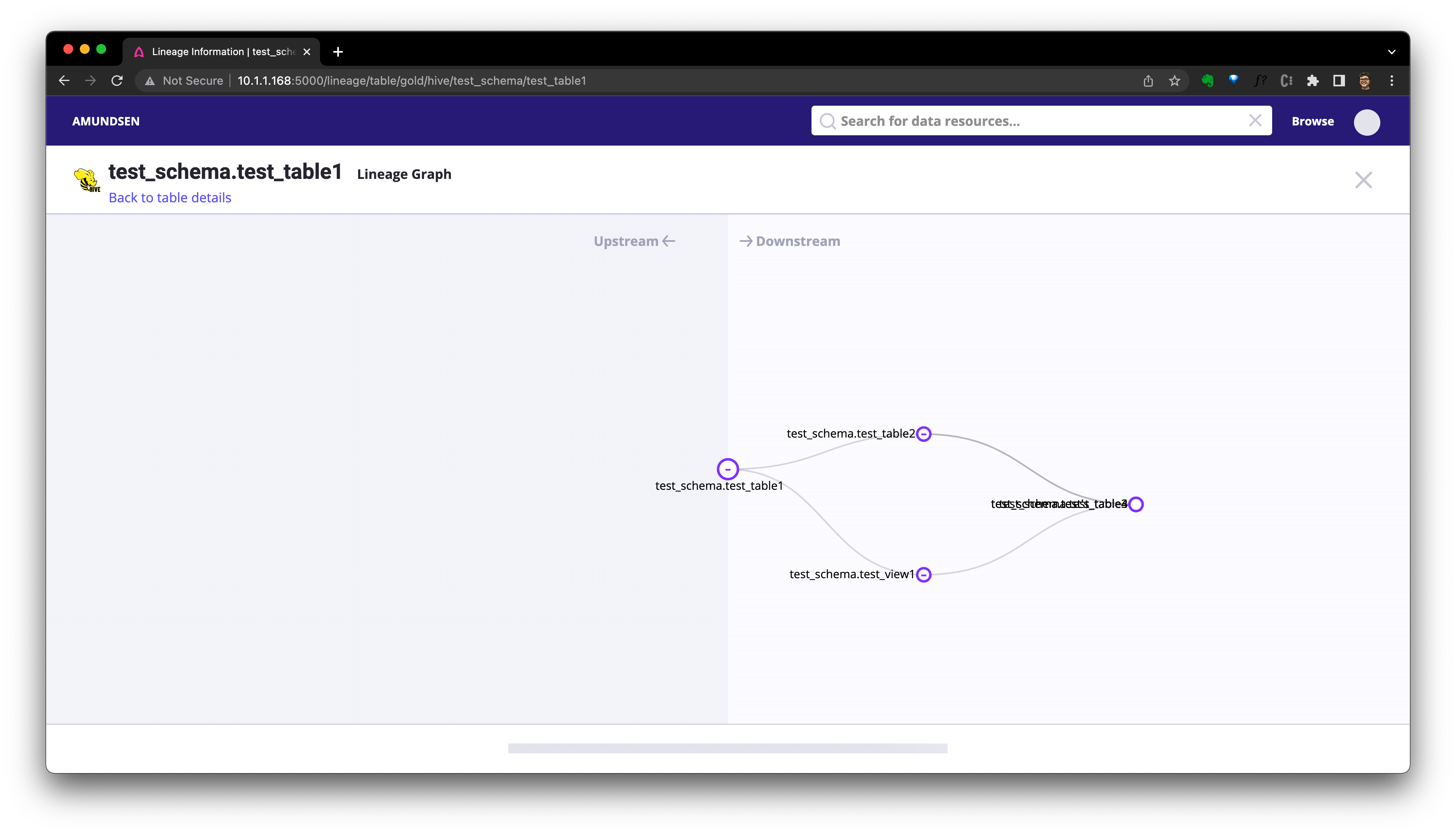
也有用於血緣查詢的 API。
下面這個例子中,我們用 cURL 呼叫下這個 API:
docker run -it --rm --net container:amundsenfrontend nicolaka/netshoot
curl "http://amundsenmetadata:5002/table/snowflake://dbt_demo.public/raw_inventory_value/lineage?depth=3&direction=both"
上面的 API 呼叫是查詢上游和下游方向的 linage,表 snowflake://dbt_demo.public/raw_inventory_value 的深度為 3。
結果應該是這樣的:
{
"depth": 3,
"downstream_entities": [
{
"level": 2,
"usage": 0,
"key": "snowflake://dbt_demo.public/fact_daily_expenses",
"parent": "snowflake://dbt_demo.public/fact_warehouse_inventory",
"badges": [],
"source": "snowflake"
},
{
"level": 1,
"usage": 0,
"key": "snowflake://dbt_demo.public/fact_warehouse_inventory",
"parent": "snowflake://dbt_demo.public/raw_inventory_value",
"badges": [],
"source": "snowflake"
}
],
"key": "snowflake://dbt_demo.public/raw_inventory_value",
"direction": "both",
"upstream_entities": []
}
實際上,這個血緣資料就是在我們的 dbtExtractor 執行期間提取和載入的,其中 extractor .dbt.{DbtExtractor.EXTRACT_LINEAGE} 預設為 true,因此,建立了血緣元資料並將其載入到了 Amundsen。
在 NebulaGraph 中洞察血緣
使用圖資料庫作為元資料儲存的兩個優點是:
圖查詢本身是一個靈活的 DSL for lineage API,例如,這個查詢幫助我們執行 Amundsen 元資料 API 的等價的查詢:
MATCH p=(t:`Table`) -[:`HAS_UPSTREAM`|:`HAS_DOWNSTREAM` *1..3]->(x)
WHERE id(t) == "snowflake://dbt_demo.public/raw_inventory_value" RETURN p
來,在 NebulaGraph Studio 或者 Explorer 的控制檯中查詢下:
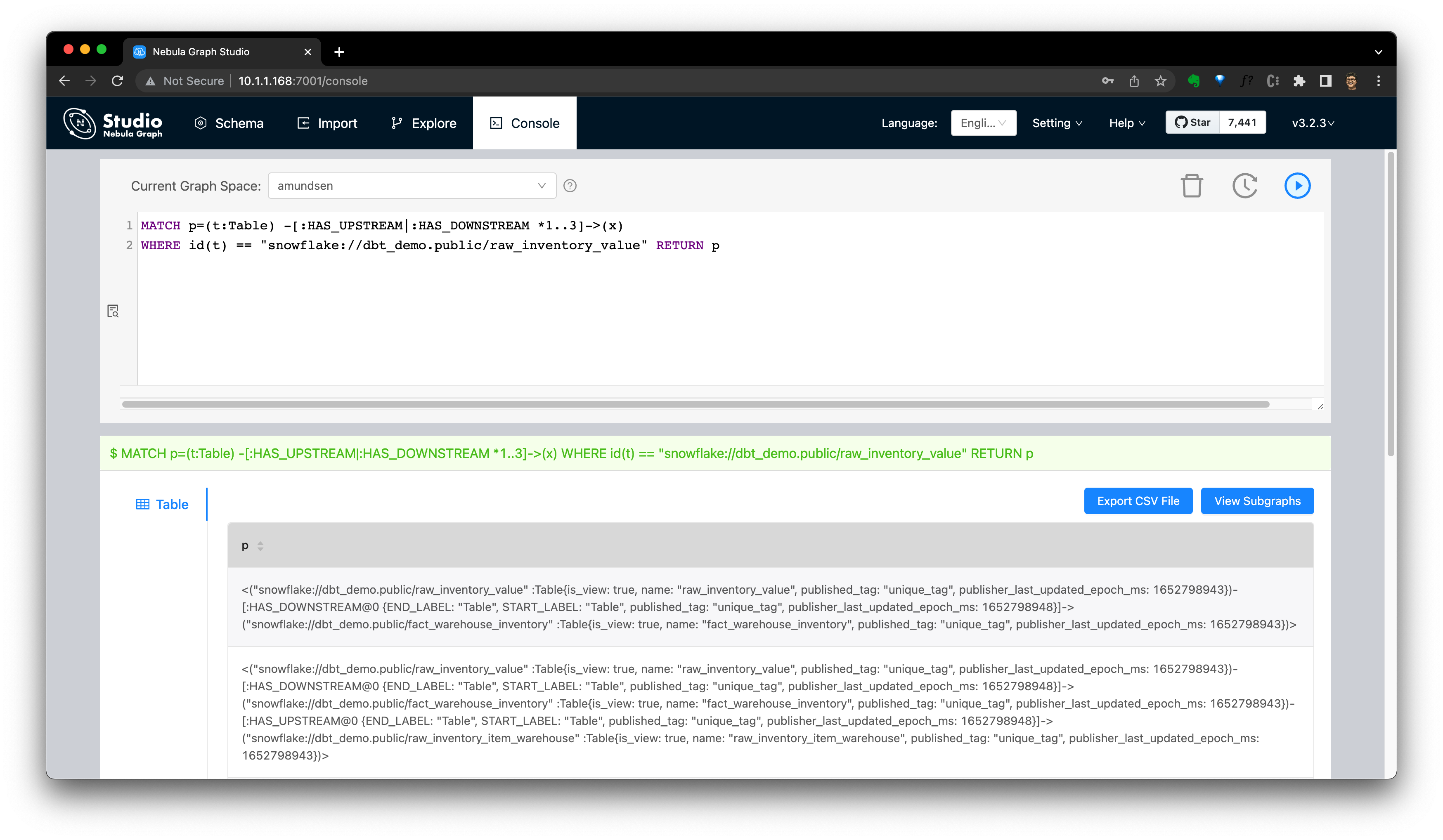
渲染下這個結果:
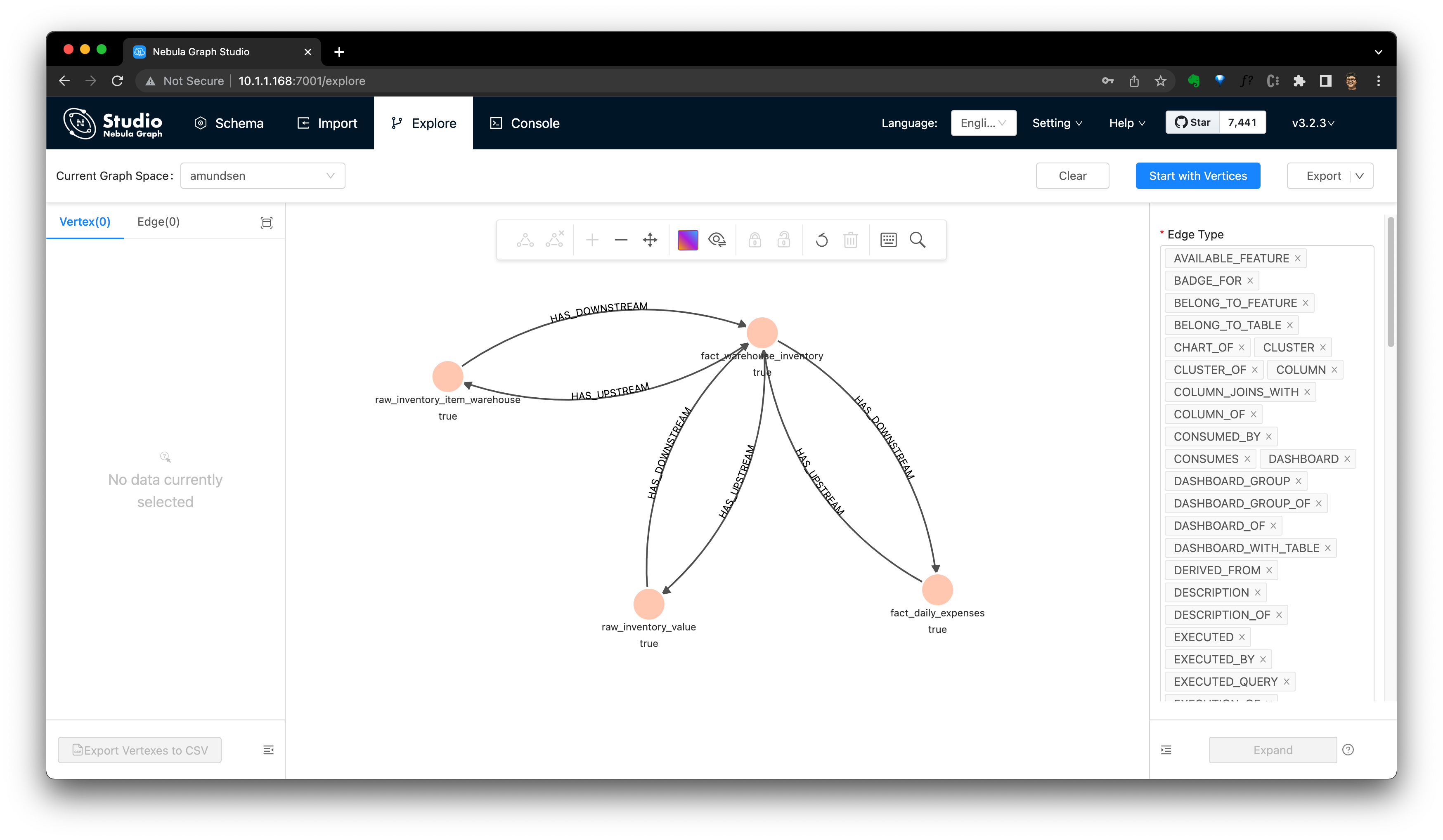
提取資料血緣
這些血緣資訊是需要我們明確指定、獲取的,獲取的方式可以是自己寫 Extractor,也可以是用已有的方式。比如:dbt 的 Extractor 和 Open Lineage 專案的 Amundsen Extractor。
通過 dbt
這個在剛才已經展示過了,dbt 的 Extractor 會從表級別獲取血緣同其他 dbt 中產生的元資料資訊一起被拿到。
通過 Open Lineage
Amundsen 中的另一個開箱即用的血緣 Extractor 是 OpenLineageTableLineageExtractor。
Open Lineage 是一個開放的框架,可以將不同來源的血統資料收集到一個地方,它可以將血統資訊輸出為 JSON 檔案,參見文件 http://www.amundsen.io/amundsen/databuilder/#openlineagetablelineageextractor。
下邊是它的 Amundsen Databuilder 例子:
dict_config = {
# ...
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.CLUSTER_NAME}': 'datalab',
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.OL_DATASET_NAMESPACE_OVERRIDE}': 'hive_table',
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.TABLE_LINEAGE_FILE_LOCATION}': 'input_dir/openlineage_nd.json',
}
...
task = DefaultTask(
extractor=OpenLineageTableLineageExtractor(),
loader=FsNebulaCSVLoader())
回顧
整套元資料治理/發現的方案思路如下:
- 將整個資料技術棧中的元件作為元資料來源(從任何資料庫、數倉,到 dbt、Airflow、Openlineage、Superset 等各級專案)
- 使用 Databuilder(作為指令碼或 DAG)執行元資料 ETL,以使用 NebulaGraph 和 Elasticsearch 儲存和索引
- 從前端 UI(使用 Superset 預覽)或 API 去使用、消費、管理和發現元資料
- 通過查詢和 UI 對 NebulaGraph,我們可以獲得更多的可能性、靈活性和資料、血緣的洞察
涉及到的開源
此參考專案中使用的所有專案都按字典順序在下面列出。
- Amundsen
- Apache Airflow
- Apache Superset
- dbt
- Elasticsearch
- meltano
- NebulaGraph
- Open Lineage
- Singer
謝謝你讀完本文 (///▽///)
要來近距離體驗一把圖資料庫嗎?現在可以用用 NebulaGraph Cloud 來搭建自己的圖資料系統喲,快來節省大量的部署安裝時間來搞定業務吧~ NebulaGraph 阿里雲端計算巢現 30 天免費使用中,點選連結來用用圖資料庫吧~
想看原始碼的小夥伴可以前往 GitHub 閱讀、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 使用者一起交流圖資料庫技術和應用技能,留下「你的名片」一起玩耍呢~
- 圖資料庫在中國移動金融風控的落地應用
- 記一次 rr 和硬體斷點解決記憶體踩踏問題
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網路應用
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網路應用
- 圖資料庫中的“分散式”和“資料切分”(切圖)
- 揭祕視覺化圖探索工具 NebulaGraph Explore 是如何實現圖計算的
- 連線微信群、Slack 和 GitHub:社群開放溝通的基礎設施搭建
- 圖資料庫認證考試 NGCP 錯題解析 vol.02:這 10 道題竟無一人全部答對
- 如何判斷多賬號是同一個人?用圖技術搞定 ID Mapping
- 複雜場景下圖資料庫的 OLTP 與 OLAP 融合實踐
- 如何運維多叢集資料庫?58 同城 NebulaGraph Database 運維實踐
- 有了 ETL 資料神器 dbt,表資料秒變 NebulaGraph 中的圖資料
- 基於圖的下一代入侵檢測系統
- 從實測出發,掌握 NebulaGraph Exchange 效能最大化的祕密
- 讀 NebulaGraph原始碼 | 查詢語句 LOOKUP 的一生
- 當雲原生閘道器遇上圖資料庫,NebulaGraph 的 APISIX 最佳實踐
- 從全球頂級資料庫大會 SIGMOD 看資料庫發展趨勢
- 「實操」結合圖資料庫、圖演算法、機器學習、GNN 實現一個推薦系統
- 如何輕鬆做資料治理?開源技術棧告訴你答案
- 圖演算法、圖資料庫在風控場景的應用