消除視覺Transformer與卷積神經網路在小資料集上的差距
摘要:本文通過多種操作構建混合模型,增強視覺Transformer捕捉空間相關性的能力和其進行通道多樣性表徵的能力,彌補了Transformer在小資料集上從頭訓練的精度與傳統的卷積神經網路之間的差距。
本文分享自華為雲社群《[NeurIPS 2022] 消除視覺Transformer與卷積神經網路在小資料集上的差距》,作者:Hint。
本文簡要介紹NeurIPS 2022錄用的論文“Bridging the Gap Between Vision Transformers and
Convolutional Neural Networks on Small Datasets”的主要工作。該論文旨在通過增強視覺Transformer中的歸納偏置來提升其在小資料集上從隨機初始化開始訓練的識別效能。本文通過多種操作構建混合模型,增強視覺Transformer捕捉空間相關性的能力和其進行通道多樣性表徵的能力,彌補了Transformer在小資料集上從頭訓練的精度與傳統的卷積神經網路之間的差距。目前該論文的程式碼處於待開源,在附錄部分已有每個模組詳細的虛擬碼展示。

1 研究背景
卷積神經網路 (Convolutional Neural Networks, CNN) 作為骨幹網路 (Backbone) 已經在計算機視覺領域佔據主導地位相當長的一段時間。而近三年來視覺Transformer (Vision Transformers, ViT) 逐漸成為另一種典型的Backbone模型,在計算機視覺各個任務上取得了令人滿意的效果。原版的ViT [1]需要現在JFT-300M這樣大規模的資料集上預訓練,然後在ImageNet-1K上進行微調才能取得較好的效果。以往對於ViT的改進方法,例如DeiT [2],T2T-ViT [3], CvT [4], Swin Transformer [5]等方法已經可以在ImageNet-1K上從頭訓練取得較好的效果,但在更小的資料集例如CIFAR-100上,從頭訓練的精度與CNN仍有較大差距。
本文歸納了以往研究[6, 7, 8]的觀點,指出“訓練資料的不足使得ViT無法在網路的淺層關注到區域性區域”,進而對深層語義資訊的提取與加工造成影響。此外“訓練資料的不足還會使得ViT學習到的物體表徵不夠充分”,因而難以進行精確識別。針對上述兩個問題,本文指出訓練資料的缺乏使得ViT自身難以獲得“空間相關性”與“通道多樣性表徵”兩種歸納偏置,進而提出了多個模組來將歸納偏置引入ViT,極大地提升了其在小資料集上的識別效能。
2 方法簡述
(1)演算法主框架:如圖1所示,本文采用的是非金字塔型的Transformer結構,並使用class token進行分類。每個編碼器層包含一個頭互動的多頭注意力 (Head-Interacted Multi-Head Self-Attention, HI-MHSA) 以及一個動態聚合前饋神經網路 (Dynamic Aggregation Feed Forward, DAFF). 在patch embedding部分採用了連續重疊的塊嵌入模組 (Sequential Overlapped Patch Embedding, SOPE)。網路將最後一層輸出的class token送入到線性分類頭進行最後的識別。
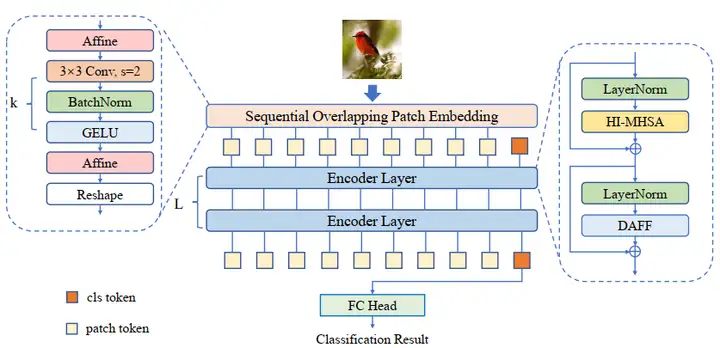
圖1: 整體架構
(2)連續重疊的塊嵌入模組SOPE:同目前其他主流的ViT一樣,本文同樣採用了卷積操作進行patch embedding。同時本文還引入了額外的仿射變換操作,增加在小資料集上訓練時的穩定性。
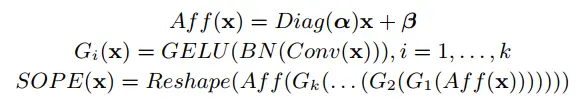
(3)動態聚合前饋神經網路DAFF:本文的在原版的前饋神經網路基礎上進行改進,在兩個線性層之間加入了深度卷積來進行領域資訊的捕捉,彌補了ViT在空間上歸納偏置的不足。同時本文在卷積旁路採用了shortcut連線,維持了原有的全域性資訊。由於class token無法參與卷積計算,同時又希望對class token進行資訊增強,因此作者引入了類似於通道注意力的操作,將卷積後的patch token進行全域性平均池化與非線性對映,再逐通道對class token進行加權。
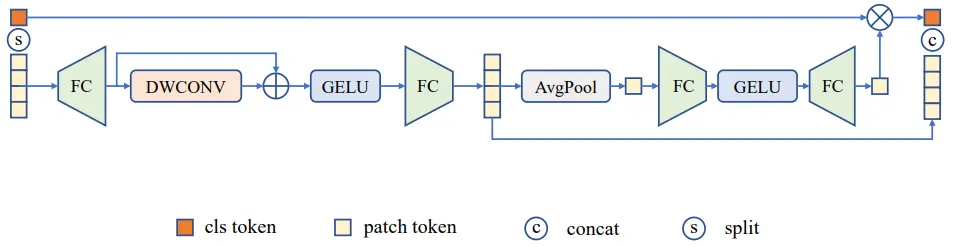
圖2:DAFF結構
(4)頭互動的多頭注意力HI-MHSA:在ViT中,計算注意力時會將向量分成多個頭,並在每個頭中單獨進行注意力的計算。由於資料量的不足,ViT所學習到的物體表徵無法進行精確識別,每個頭中所包含的物體表徵相對較弱,因此本文額外引入了head token,旨在將各個頭中較弱的物體表徵融合形成足夠強的表徵。在資料送入多頭注意力計算前,會先進行head token的提取。輸入資料會根據設定的注意力頭的數量,將資料劃分成同等數量的分段,然後將每個分段重新對映成和原來一樣的通道數。head token將會和其他所有token一起進行注意力的計算。此時每一個注意力頭都會獲得來自於其他注意力頭的資訊,將各個較弱的表徵融合成了足以進行精確識別的物體表徵。流程如圖3所示。
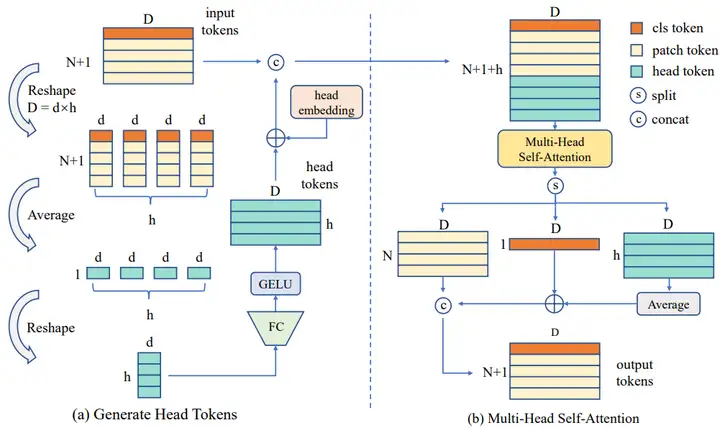
圖3:HI-MHSA結構
3 實驗結果
本文在多個小資料集上進行“從頭訓練 (train from scratch)”,包含CIFAR-100以及多個DomainNet的資料集,同時還在ImageNet-1K上進行實驗,證明本文方法在較大的資料集上同樣有效。
(1)在CIFAR-100上與SOTA的對比如下表。可以看到本文方法不僅可以超越以往所有ViT和Hybrid系列方法,同時還能以較少的引數量超越CNN的精度。
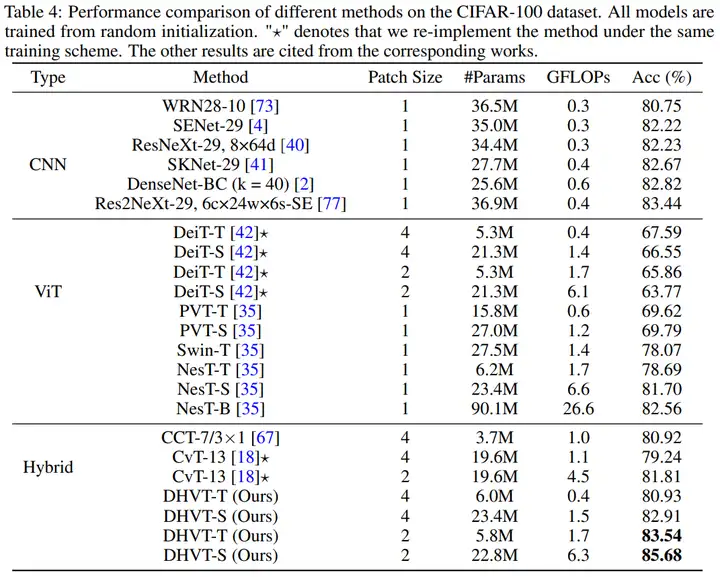
(2)DomainNet資料集的統計資訊,以及各個方法在DomainNet資料集上的效果如下,同樣展現了本文方法在精度上的優越性。

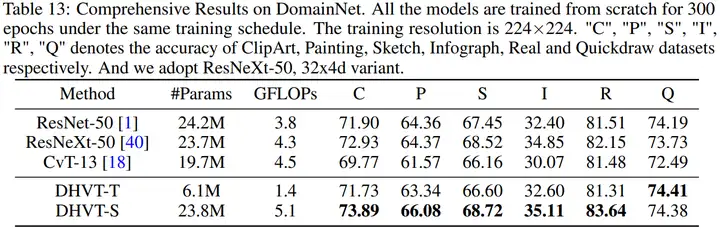
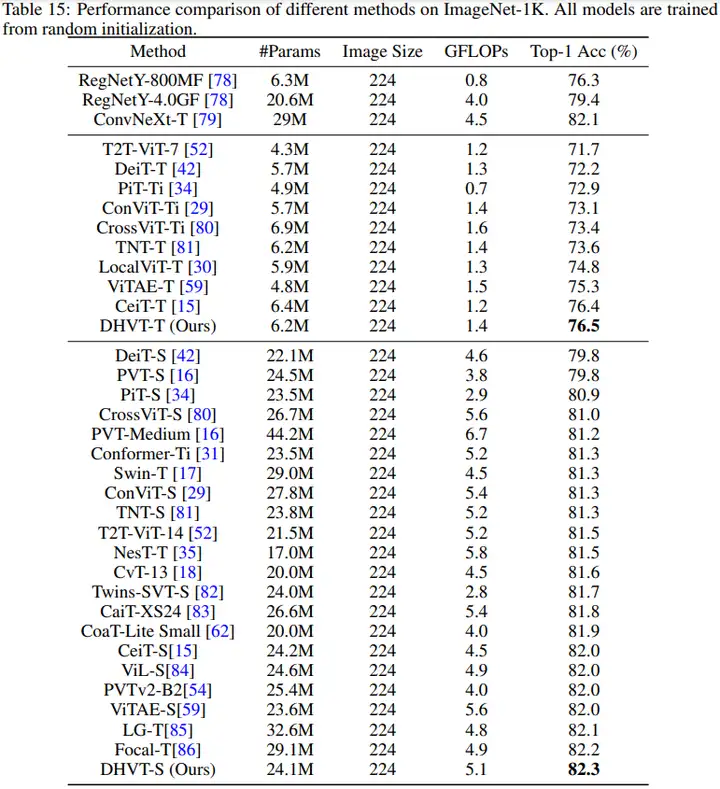
(3)本文方法與SOTA方法在ImageNet-1K上的對比結果如下。可以看到本文方法超越了以往所有的非金字塔型ViT模型,同時還能超越同期的較多金字塔型ViT模型。
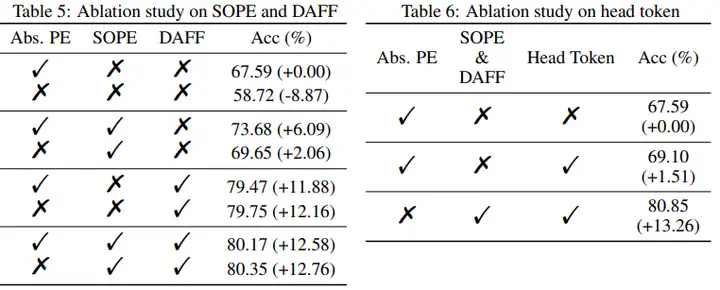
(4)消融實驗部分同樣展示了本文各個模組的有效性。
4 視覺化結果
本文展示了注意力視覺化結果。下圖4展示了各個head token的注意力分佈不同,表明了各個資料分段和注意力頭對應不同的物體表徵。

圖4:head token的注意力視覺化
本文還展示了在ImageNet-1K上訓練出來的注意力分佈,如圖5所示。由於head token放在了其他token的後面,因此注意力圖最右邊的幾列表示所有token對head token的注意力啟用。
可以看到所有的token在網路的淺層時主要關注臨近的token,提取區域性資訊。到了中間層,例如7-10層時,模型進行全域性資訊的互動,同時利用head token將各個head的表徵融合在一起。到了最深層的11和12層,模型再次迴歸到全域性資訊的篩選,得到最終的分類資訊表徵。該圖展示了一種可能的ViT資訊提取方式,可能會對未來ViT模型的資訊提取模式帶來啟發。

圖5:DHVT-S在ImageNet-1K上的注意力視覺化
5 總結
本文通過彌補ViT模型所缺失的兩種歸納偏置,極大地提升了其在小資料集上的分類精度,達到了與傳統CNN持平甚至更好的效果。同時本文所引入的注意力互動機制可能會對未來研究產生啟發。但本文的方法同樣存在缺陷,例如優良的精度是以巨大的計算代價帶來的,期待未來的後續工作能夠探索到在計算負擔和精度直接進行良好折中的方法。
相關資源:
論文地址:http://arxiv.org/pdf/2210.05958.pdf
程式碼連結:http://github.com/ArieSeirack/DHVT (待補全開源)
參考文獻
[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. PMLR, 2021: 10347-10357.
[3] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 558-567.
[4] Wu H, Xiao B, Codella N, et al. Cvt: Introducing convolutions to vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 22-31.
[5] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[6] Raghu M, Unterthiner T, Kornblith S, et al. Do vision transformers see like convolutional neural networks?[J]. Advances in Neural Information Processing Systems, 2021, 34: 12116-12128.
[7] Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.
[8] d’Ascoli S, Touvron H, Leavitt M L, et al. Convit: Improving vision transformers with soft convolutional inductive biases[C]//International Conference on Machine Learning. PMLR, 2021: 2286-2296.
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析