百度工程師淺談分散式日誌

作者 | 文庫基礎架構
導讀
我們做軟體開發時,或多或少的會記錄日誌。由於日誌不是系統的核心功能,常常被忽視,定位問題的時候才想起它。本文由淺入深的探討不起眼的日誌是否重要,以及分散式架構下的日誌運維工具應該具備哪些能力,希望感興趣的讀者能從本文獲得一些啟發,有所幫助。
全文8832字,預計閱讀時間23分鐘。
01 什麼是日誌
日誌是一種按照時間順序儲存記錄的資料,它記錄了什麼時間發生了什麼事情,提供精確的系統記錄,根據日誌資訊可以定位到錯誤詳情和根源。按照APM概念的定義,日誌的特點是描述一些離散的(不連續的)事件。
日誌是按照錯誤級別分級的,常見的錯誤級別有 FATAL / WARNING / NOTICE / DEBUG / TRACE 5種類型。通常我們會在專案裡面定義一個日誌列印級別,高於這個級別的錯誤日誌會資料落盤。

02 什麼時候記錄日誌
在大型網站系統架構裡面,日誌是其中的重要功能組成部分。它可以記錄下系統所產生的所有行為,並按照某種規範表達出來。我們可以使用日誌系統所記錄的資訊為系統進行排錯,優化效能。通過統計使用者行為日誌,幫助產品運營同學做業務決策。在安全領域,日誌可以反應出很多的安全攻擊行為,比如登入錯誤,異常訪問等。日誌能告訴你很多關於網路中所發生事件的資訊,包括效能資訊、故障檢測和入侵檢測。還可以為審計進行審計跟蹤,日誌的價值是顯而易見的。
03 日誌的價值
在大型網站系統架構裡面,日誌是其中的重要功能組成部分。它可以記錄下系統所產生的所有行為,並按照某種規範表達出來。我們可以使用日誌系統所記錄的資訊為系統進行排錯,優化效能。通過統計使用者行為日誌,幫助產品運營同學做業務決策。在安全領域,日誌可以反應出很多的安全攻擊行為,比如登入錯誤,異常訪問等。日誌能告訴你很多關於網路中所發生事件的資訊,包括效能資訊、故障檢測和入侵檢測。還可以為審計進行審計跟蹤,日誌的價值是顯而易見的。
04 分散式架構的日誌運維
4.1 為什麼要有運維工具
微服務發展迅猛的今天,鬆耦合的設計層出不窮,為簡化服務服務帶來了極大的便利。業務方向分工明確,研發同學只需要關心自己模組的版本迭代上線就好。隨著整個業務架構的擴大,服務例項的數量迎來了爆炸性的增長,往往帶來以下問題:
-
由不同團隊開發,使用不同的程式語言,日誌格式不規範統一;
-
微服務迭代速度快,日誌漏記、級別使用錯誤、難以提取有效資訊;
-
容器例項分佈在成千上萬臺伺服器上,橫跨多個數據中心,異構部署,難以串聯請求鏈路。
沒有工具的情況下,需要登入服務例項,檢視原始日誌,在日誌檔案中通過grep、awk方式獲得自己想要的資訊。但在規模較大的場景中,此方法效率低下,面臨問題包括日誌量太大不易歸檔、文字搜尋太慢、不方便多維度查詢。這時候需要更加高效的運維工具來代替人工訪問日誌。常見解決思路是建立集中式日誌收集系統,將所有節點上的日誌統一收集,管理,訪問。
4.2 運維工具建設
我們希望通過原始日誌可以理解系統行為,這需要建設具備效能分析,問題定位的能力的工具平臺。它能夠支援:
-
在故障發生前,分析風險和系統瓶頸;
-
在故障發生時,及時通知,快速定位解決問題;
-
在故障發生後,有歷史資料迅速覆盤。
通過建設具備日誌即時收集、分析、儲存等能力的工具平臺。使用者可以快速高效地進行問題診斷、系統運維、流量穩定性監控、業務資料分析等操作。比如搭建鏈路追蹤系統,能追蹤並記錄請求在系統中的呼叫順序,呼叫時間等一系列關鍵資訊,從而幫助我們定位異常服務和發現效能瓶頸,提升了系統的『可觀測性』。前面提到日誌在APM標準的定義下日誌的特點是描述一些離散的(不連續的)事件。這裡說下APM是什麼,方便更好的構建監控方面的知識體系。
05 APM和可觀測性
APM 是Application Performance Managment的縮寫,即:“應用效能管理”。可以把它理解成一種對分散式架構進行觀測分析優化的理念和方法論。監控系統(包括告警)作為SLA體系的一個重要組成部分,不僅在業務和系統中充當保鏢發現問題、排查問題的作用。
隨著系統不斷演進完善,我們可以獲得越多幫助於瞭解業務和系統的資料和資訊,這些資訊可以更進一步的幫助我們進行系統上的優化,由於可以梳理請求鏈路得出使用者的瀏覽偏好,甚至可以影響業務上的關鍵決策。
整體來說,整個APM體系就是將大三類資料(logs、metrics、trace)應用到四大模組中(收集、加工、儲存、展示),並在四個難點(程式異構,元件多樣,鏈路完整,時效取樣)上不斷優化。
可觀測性 是APM的一大特徵,主要由以下三大支柱構成,分別是Logging(日誌),Metrics(指標),以及Tracing(應用跟蹤)。
-
Logging:自動埋點/手動埋點,展現的是應用執行而產生的事件或者程式在執行的過程中間產生的一些日誌,可以詳細解釋系統的執行狀態,但是儲存和查詢需要消耗大量的資源。
-
Metrics:服務、端點、例項的各項指標,是一種聚合數值,儲存空間很小,可以觀察系統的狀態和趨勢,對於問題定位缺乏細節展示,最節省儲存資源。
-
Tracing:同一TraceId的呼叫序列,面向的是請求,可以輕鬆分析出請求中異常點,資源可能消耗較大,不過依據具體功能實現相對可控。

5.1 Metrics和Prometheus
Metrics:指標。
I think that the defining characteristic of metrics is that they are aggregatable: they are the atoms that compose into a single logical gauge, counter, or histogram over a span of time.
大致上可理解為一些可進行聚合計算的原子型資料。舉些例子:cpu佔用情況、系統記憶體佔用、介面響應時間、介面響應QPS、服務gc次數、訂單量等。這些都是根據時間序列儲存的資料值,可以在一段時間內進行一些求和、求平均、百分位等聚合計算。指標在監控系統中不可或缺,我們都需要收集每種指標在時間線上的變化,並作同比、環比上的分析。metrics的儲存形式為有時間戳標記的資料流,通常儲存在TSDB(時間序列資料庫)中。
Metrics側重於各種報表資料的收集和展示,常用在大規模業務的可用性建設、效能優化、容量管理等場景,通過視覺化儀表盤可高效地進行日常系統巡檢、快速檢視應用健康狀況,可以精準感知可用性和效能問題,為產品的穩定執行保駕護航。
Prometheus 是一個開源的監控解決方案,它能夠提供監控指標資料的採集、儲存、查詢以及監控告警等功能。作為雲原生基金會(CNCF)的畢業專案,Prometheus 已經在雲原生領域得到了大範圍的應用,並逐漸成為了業界最流行的監控解決方案之一。
下圖為Prometheus的工作流程,可以簡單理解為:Prometheus server定期拉取目標例項的採集資料,時間序列儲存,一方面通過配置報警規則,把觸發的報警傳送給接收方,一方面通過元件Grafana把資料以圖形化形式展示給使用者。

5.2 Logging和ELK
Logging:日誌。
I think that the defining characteristic of logging is that it deals with discrete events.
日誌是系統執行時發生的一個個事件的記錄。Logging的典型特徵就是它和孤立的事件(Event)強關聯,一個事件的產生所以導致了一條日誌的產生。舉個例子就是一個網路請求是一個事件,它被雲端接到後Nginx產生了一個訪問log。大量的不同外部事件間基本是離散的,比如多個使用者訪問雲端業務時產生的5個事件間沒有必然的關係,所以在一個服務節點的角度上看這些事件產生的日誌間也是離散的。
關於日誌管理平臺,相信很多同學聽說過最多的就是ELK(elastic stack),ELK是三款軟體的簡稱,分別是Elasticsearch、 Logstash、Kibana組成。在APM體系中,它可以實現關鍵字的分散式搜尋和日誌分析,能夠快速定位到我們想要的日誌,通過視覺化平臺的展示,能夠從多個維度來對日誌進行細化跟蹤。
Elasticsearch基於java,是個開源分散式搜尋引擎,它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。它的特點有:分散式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料來源,自動搜尋負載等。
Kibana基於nodejs,是一款開源的資料分析和視覺化平臺,它是Elastic Stack成員之一,設計用於和Elasticsearch協作。您可以使用Kibana對Elasticsearch索引中的資料進行搜尋、檢視、互動操作。您可以很方便的利用圖表、表格及地圖對資料進行多元化的分析和呈現。
Logstash基於java,是一個開源的用於收集,分析和儲存日誌的工具,能夠同時從多個來源採集資料,轉換資料,然後將資料傳送到最喜歡的儲存庫中(我們的儲存庫當然是ElasticSearch)。
下面是ELK的工作原理:

ELK中的L理解成Logging Agent比較合適。Elasticsearch和Kibana是儲存、檢索和分析log的標準方案。在高負載的ELK平臺迭代實踐中,常常採用一些優化策略。比如:ElasticSearch 做冷熱資料分離,歷史索引資料關閉;Filebeat更加輕量,對資源消耗更少,替代Logstash作為資料收集引擎;增加訊息佇列做資料緩衝,通過解耦處理過程實現削峰平谷,幫助平臺頂住突發的訪問壓力。
ELK的缺點也是明顯的,部署這樣一套日誌分析系統,不論是儲存還是分析所需要佔用的機器成本是挺大的。業務日誌是時時列印的,大規模的線上服務一天日誌量可能達到TB級別,如果採用ELK平臺,在保證關鍵日誌資訊入庫的同時,有針對性的對所需日誌檔案進行採集和過濾是必不可少的。
5.3 Tracing、OpenTracing和Apache SkyWalking
.Tracing:鏈路。
I think that the single defining characteristic of tracing , then, is that it deals with information that is request-scoped.
鏈路可理解為某個最外層請求下的所有呼叫資訊。在微服務中一般有多個呼叫資訊,如從最外層的閘道器開始,A服務呼叫B服務,呼叫資料庫、快取等。在鏈路系統中,需要清楚展現某條呼叫鏈中從主調方到被調方內部所有的呼叫資訊。這不僅有利於梳理介面及服務間呼叫的關係,還有助於排查慢請求產生的原因或異常發生的原因。
Tracing最早提出是來自Google的論文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,它讓Tracing流行起來。而Twitter基於這篇論文開發了Zipkin並開源了這個專案。再之後業界百花齊放,誕生了一大批開源和商業Tracing系統。
Tracing 以請求的維度,串聯服務間的呼叫關係並記錄呼叫耗時,即保留了必要的資訊,又將分散的日誌事件通過Span層串聯, 幫助我們更好的理解系統的行為、輔助除錯和排查效能問題。它的基本概念如下兩點:
-
Trace(呼叫鏈):OpenTracing中的Trace(呼叫鏈)通過歸屬於此呼叫鏈的Span來隱性的定義。一條Trace(呼叫鏈)可以被認為是一個由多個Span組成的有向無環圖(DAG圖),可以簡單理解成一次事務;
-
Span(跨度):可以被翻譯為跨度,可以被理解為一次方法呼叫,一個程式塊的呼叫,或者一次RPC/資料庫訪問,只要是一個具有完整時間週期的程式訪問,都可以被認為是一個Span。
對於一個元件來說,一次處理過程產生一個 Span,這個 Span 的生命週期是從接收到請求到返回響應這段過程,在單個Trace中,存在多個Span。
舉個例子,比如一個請求使用者訂單資訊的介面,流量分發到了應用層例項(Span A)來處理請求,應用層例項(Span A)需要請求訂單中心服務例項(Span B)來獲取訂單資料,同時請求使用者中心服務例項(Span C)來獲取使用者資料。基礎服務B、C可能還有其他依賴服務鏈路,則如下圖所示結構,Span間的因果關係如下:
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子節點, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 後被呼叫, FollowsFrom)
OpenTracing是一箇中立的(廠商無關、平臺無關)分散式追蹤的API 規範,提供統一介面,可方便開發者在自己的服務中整合一種或多種分散式追蹤的實現。由於近年來各種鏈路監控產品層出不窮,當前市面上主流的工具既有像Datadog這樣的一攬子商業監控方案,也有AWS X-Ray和Google Stackdriver Trace這樣的雲廠商產品,還有像Zipkin、Jaeger這樣的開源產品。
雲原生基金會(CNCF) 推出了OpenTracing標準,推進Tracing協議和工具的標準化,統一Trace資料結構和格式。OpenTracing通過提供平臺無關、廠商無關的API,使得開發人員能夠方便新增(或更換)追蹤系統的實現。比如從Zipkin替換成Jaeger/Skywalking等後端。

在眾多Tracing產品中,值得一提的是國人自研開源的產品Skywalking。它是一款優秀的APM工具,專為微服務、雲原生架構和基於容器架構而設計,支援Java、.Net、NodeJs等探針方式接入專案,資料儲存支援Mysql、Elasticsearch等。功能包括了分散式鏈路追蹤,效能指標分析和服務依賴分析等。2017年加入Apache孵化器,2019年4月17日Apache董事會批准SkyWalking成為頂級專案,目前百度廠內有一些業務線採用skywalking作為主要的日誌運維平臺。
5.4 Metrics,Logging和 Tracing 結合
指標、日誌、鏈路在監控中是相輔相成的。現在再來看上圖中,兩兩相交的部分:
-
通過指標和日誌維度,我們可以做一些事件的聚合統計,例如,繪製流量趨勢圖,某應用每分鐘的錯誤日誌數
-
通過鏈路和日誌系統,我們可以得到某個請求詳細的請求資訊,例如請求的入參、出參、鏈路中途方法打印出的日誌資訊;
-
通過指標和鏈路系統,我們可以查到請求呼叫資訊,例如 SQL執行總時長、各依賴服務呼叫總次數;
可見,通過這三種類型資料相互作用,可以得到很多在某種型別資料中無法呈現的資訊。例如下圖是一個故障排查的示例,首先,我們從訊息通知中發現告警,進入metrics指標面板,定位到有問題的資料圖表,再通過指標系統查詢到詳細的資料,在logging日誌系統查詢到對應的錯誤,通過tracing鏈路追蹤系統檢視鏈路中的位置和問題(當然也可以先用鏈路追蹤系統進行故障的定位,再查詢詳細日誌),最後修復故障。這是一個典型的將三個系統串聯起來應用的示例。

06 文庫在日誌運維上的實踐
6.1 匯聚監控
文庫App對於域名、中介軟體、依賴服務等流量穩定性,機器資源的監控,基於廠內現有的解決方案(Bns+Argus監控系統+Sia視覺化平臺)實現。工作流程可以理解為:
-
在日誌採集平臺(Argus)配置資料採集規則,異常判斷規則和報警配置規則;
-
通過服務例項對映配置(Bns)獲取到要採集日誌的例項列表,例項服務的log format要符合採集規則的正則表示式;
-
Agent上報日誌分析資料給MQ消化,MQ存入TSDB;
-
日誌匯聚後的分析計算結果符合異常判斷規則,則觸發對應配置的報警規則;
-
報警規則可以配置多維度分級分時間和不同方式提醒到接收人。同時,通過配置群聊機器人對包括資源,接入層,執行層,服務及底層依賴的等服務,依據閥值進行基本實時的監控報警;
-
視覺化平臺(Sia)通過 metric 配置從 TSDB 中讀出相應資料,進行圖形化展示。

6.2 批量查詢
即時日誌撈取工具在我們業務開發中也是比較常見的,通常通過批量併發執行遠端伺服器指令來實現,解決依次執行的繁鎖,讓運維操作更安全便捷。
這種工具不依賴agent,只通過ssh就可以工作,一般通過中控機或者賬戶密碼等方式做ssh訪問控制,執行grep,tail等命令獲取日誌,然後對logs進行分析,可以解決日常中很多的需求。簡化程式碼如下。
package main
import (
"fmt"
"log"
"os/exec"
"runtime"
"sync"
)
// 併發環境
var wg sync.WaitGroup
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
instancesHost := getInstances()
wg.Add(len(instancesHost))
for _, host := range instancesHost {
go sshCmd(host)
}
wg.Wait()
fmt.Println("over!")
}
// 執行查詢命令
func sshCmd(host string) {
defer wg.Done()
logPath := "/xx/xx/xx/"
logShell := "grep 'FATAL' xx.log.20230207"
cmd := exec.Command("ssh", "PasswordAuthentication=no", "ConnectTimeout=1", host, "-l", "root", "cd", logPath, "&&", logShell)
out, err := cmd.CombinedOutput()
fmt.Printf("exec: %s\n", cmd)
if err != nil {
fmt.Printf("combined out:\n%s\n", string(out))
log.Fatalf("cmd.Run() failed with %s\n", err)
}
fmt.Printf("combined out:\n%s\n", string(out))
}
// 獲取要查詢的例項ip地址庫
func getInstances() []string {
return []string{
"x.x.x.x",
"x.x.x.x",
"x.x.x.x",
}
}
把如上程式碼部署在中控機上ssh免密登入,通過go run batch.go或執行go build後的二進位制檔案,可以實現批量查詢日誌的基礎能力。在此基礎上增加傳參,可以實現指定叢集例項,指定exec命令,併發度控制,優化輸出等功能。
6.3 鏈路跟蹤
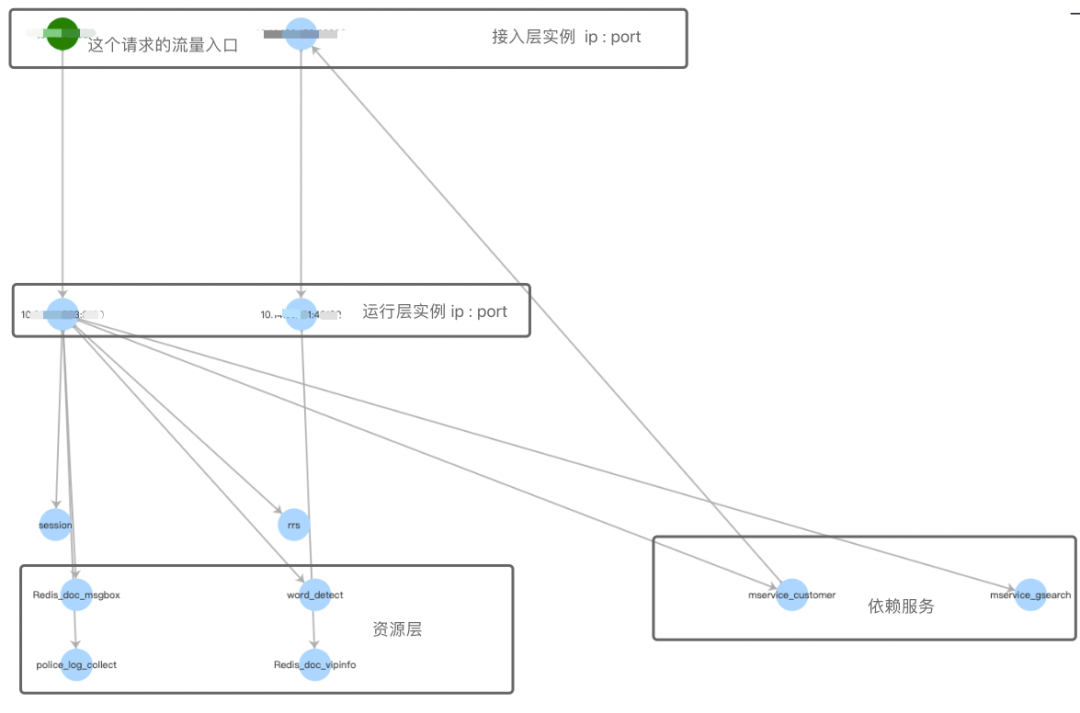
文庫自研的全鏈路日誌跟蹤平臺,支援trace全鏈路日誌跟蹤,指標匯聚,關鍵資訊高亮,搜尋範圍覆蓋nginx,nodejs,php,go等異構微服務,還支援動態繪製呼叫鏈路圖。使用者可以通過查詢tracid的方式獲得一個請求鏈路的http分析,呼叫服務的次數匯聚,日誌list和拓撲鏈路圖。
透傳trace的底層流程是在接入層nginx擴充套件生成的一個20 -26位長、編碼了nginx所在機器ip和請求時間的純數字字串。這個字串在請求日誌、服務執行日誌、rpc日誌中記錄,通過Http Header向下透傳,在服務間呼叫過程中,在當前層記錄呼叫的下一層例項ip:port資訊,保證trace引數維持。
綠色的節點為鏈路呼叫的起始節點,一般是文庫接入層。滑鼠hover到哪個節點會title展示詳情,並在整個鏈路中隱去與之不相關的節點鏈路。如果節點有fatal,warning的日誌,節點背景色會以紅色,黃色展示。
07 日誌的壞味道
-
資訊不明確。後果:執行效率降低;
-
格式不規範。後果:不可讀,無法採集;
-
日誌過少,缺乏關鍵資訊。後果:降低定位問題效率;
-
參雜了臨時、冗餘、無意義的日誌。後果:生產列印大量日誌消耗效能;
-
日誌錯誤級別使用混亂。後果:導致監控誤報;
-
使用字串拼接方式,而非佔位符。後果:可維護性較低;
-
程式碼迴圈體打非必要的日誌。後果:有宕機風險;
-
敏感資料未脫敏。後果:有隱私資訊洩露風險;
-
日誌檔案未按小時分割轉儲。後果:不易磁碟空間回收;
-
服務呼叫間沒有全域性透傳trace資訊。後果:不能構建全鏈路日誌跟蹤。
08 日誌 good case
-
能快速的定位問題;
-
能提取有效資訊,瞭解原因;
-
瞭解線上系統的執行狀態;
-
匯聚日誌關鍵資訊,可以發現系統的瓶頸;
-
日誌隨著專案迭代,同步迭代;
-
日誌的列印和採集、上報服務,不能影響系統的正常執行。
09 結語
在萬物上雲的時代,通過搭建合適的日誌運維平臺來賦予資料搜尋、分析和監控預警的能力,讓沉寂在伺服器的日誌"動"起來,可以幫助我們在資料分析,問題診斷,系統改進的工作中更加順利的進行,希望本文的內容對大家的實踐有所幫助。
——END——
推薦閱讀:
- 精準水位在流批一體資料倉庫的探索和實踐
- 視訊編輯場景下的文字模版技術方案
- 淺談活動場景下的圖演算法在反作弊應用
- 百度工程師帶你玩轉正則
- Serverless:基於個性化服務畫像的彈性伸縮實踐
- 百度APP iOS端記憶體優化-原理篇
- 從稀疏表徵出發、召回方向的前沿探索
- 效能平臺數據提速之路
- 採編式AIGC視訊生產流程編排實踐
- 百度工程師漫談視訊理解
- PGLBox 超大規模 GPU 端對端圖學習訓練框架正式釋出
- 百度工程師淺談分散式日誌
- 百度工程師帶你瞭解Module Federation
- 巧用Golang泛型,簡化程式碼編寫
- Go語言DDD實戰初級篇
- 百度工程師帶你玩轉正則
- Diffie-Hellman金鑰協商演算法探究
- 貼吧低程式碼高效能規則引擎設計
- 淺談許可權系統在多利熊業務應用
- 分散式系統關鍵路徑延遲分析實踐