悟空劉歧:技術瑕疵不除不快,開源社群程式碼說話
每個人愛上開源社群都有自己特別的理由,對於劉歧來說,這裡是一個技術控的天堂。
玩過音視訊技術的同學對悟空這個名字一定不陌生。悟空劉歧,FFmpeg 官方顧問、Maintainer,FFmpeg 社群最活躍的貢獻者之一,《FFmpeg 從入門到精通》作者。
FFmpeg——老牌開源專案,萬能播放器的根基。劉歧——喜歡技術、只想討論技術問題的程式設計師。
二者之間的“羈絆”來自於劉歧對於一個技術“瑕疵”的不滿,為了解決自己眼中 FFmpeg 的一個不合理功能,劉歧開始了在 FFmpeg 社群的征程。FFmpeg 社群的治理屬於 Liberal Contribution(自由貢獻)模式,個人影響力取決於貢獻多寡,重大決策基於共識決定,一切靠程式碼說話。毫無疑問,對於只愛技術的劉歧來說,這是一個好地方。和社群成員們一起討論技術,共同解決 Bug,時不時提交些新的程式碼成了劉歧在工作與生活之外獨特且有效的放鬆方式。 就這樣,劉歧慢慢在開源社群紮根、成長……
初入開源社群
大學畢業,劉歧到一家做空中充值終端機的公司工作。在這裡,他正式踏上了自己的開源之旅。
當時劉歧所在公司自研的電路板移植了 Linux 作業系統,劉歧參與了給系統寫驅動的工作,自然他也遇到了所有程式設計師都會遇到的各種 Bug,為了解決隨時可能出現的問題,劉歧開始向前輩們尋求幫助。Linux Kennel 中文郵件列表成為劉歧的求解渠道。
Linux Kennel 中文郵件列表給劉歧留下的初印象是“熱情”:“基本上你發一個問題,大夥馬上就回復了。可能是因為郵件列表剛建立不久,大家看到終於有一個新人加入進來問問題,肯定特別開心,立刻就想回復。”出於一種整體良好的社群體驗和對技術的熱情,劉歧開始長期在這個開源軟體的郵件列表社群中潛水學習,偶爾遇到問題會向大夥請教。
如果說第一份工作給了劉歧一個進入開源社群的緣由,那麼第二份工作則是為他帶來了紮根在社群的契機。
劉歧在第二份工作中主要做圖形影象處理。一次偶然機會,和同事在聊天過程中,劉歧發現對方在許多技術基礎知識、技術視野等方面與自己非常不同,“感覺他的技術很紮實”。箇中原因就是這位同事深度參與了 BSD 的程式碼開發與維護。
這激起了劉歧想要深度參與一個開源專案的興趣——不僅僅和自己的同事交流技術、不僅僅是侷限於自家公司的業務範圍,而是可以和更多的人在一起討論更廣泛的技術問題,由此來提升自己的技術視野。
對於一家商業公司來說,程式碼的要求往往是滿足當下業務需求,很少去考慮這些程式碼是否能有更長的生命週期,是否足夠優雅等等。但在開源社群,來自千行百業的程式設計師相互交流、碰撞,便給了軟體一個不斷成長的溫床。
有了深度參與開源專案的念頭之後不久,劉歧開始做雲儲存、雲轉碼系統工作,用到了 FFmpeg,遇到問題時,劉歧會像在 Linux Kennel 中文社群解決 bug 的方式那樣,去 FFmpeg 社群搜尋是否已經有人遇到過同樣的問題,該怎麼解決這些問題,“遇到問題的第一個感覺就是,這個問題我肯定不是第一個遇到,那我在網上或者郵件列表裡肯定能搜到相關內容或 Patch。”
同時,劉歧也開始嘗試深度參與 FFmpeg 社群,他會觀察社群中的成員間是如何交流溝通的,提 Patch 的流程是怎樣等等。用他自己的話來說,就是“光是瞭解這個社群我就花了 2 年。”逐漸他發現,許多問題在社群中還沒有被解決或是提及。機會,在這個時候到來。
發現問題
2014 年上半年,劉歧接觸了一個客戶,需要用 FFmpeg 做 HLS 切片。彼時用 FFmpeg 在切片時,有個引數對 CDN 不夠友好。 當時 FFmpeg 的切片原理會按照順序生成 1、2、3、4 片,第 4 片結束後會回滾到第 1 片。每片的時間長度是 2 秒,所以第 8-10 秒的視訊切片就會被標記為序號 1。這就導致在 CDN 裡,快取時間長度出現問題。當用戶播放完 0-2 秒的 1.ts 之後,第 1 片視訊應該被重新整理掉,但實際上並沒有,那麼使用者播放到 8-10 秒的 1.ts 時,播的依舊是 0-2 秒的內容。加上時間戳精準度的影響,視訊就會卡住,一段時間之後再跳轉到新的畫面,非常影響使用者觀感。
“這是一個不標準的處理方式。”實際上,這個問題劉歧並不是第一次遇到,他會嘗試和客戶反饋,建議不用回滾,而是按照遞增的方式去生成。但這帶來新的問題——佔儲存。回滾的方式是為了節省儲存,不會無休止的往裡寫新檔案。
不僅如此,客戶還認為,既然 FFmpeg 裡提供了這個操作選項,存在即合理,就可以沿用。
劉歧此前也試過向 FFmpeg 社群提改進意見,“往 flv 裡提 hevc,在 2013 年年底的時候,國內很多公司就開始使用這個技術了,但是我往 FFmpeg 社群提這個 Patch 的時候,社群裡的人是反對的,因為沒有相應地參考標準,所以不接受這個方式。”
在一個技術控眼裡,這種技術功能上的“瑕疵”不除不快,FFmpeg 社群拒絕改進的理由也並不能讓劉歧讓步。
“我那時的觀念就是,FFmpeg 也是人寫的,選項是人來定的,那麼我就有可能是那個人。”於是,劉歧立志要加入 FFmpeg 維護者列表,然後“幹掉那個選項”。
刪掉一個小功能需要幾年?
想要刪掉功能,要先成為維護者。
在 FFmpeg 社群,一名維護者通常需要先頻繁地提交高質量的程式碼,在社群“混臉熟”,獲取一定的認可度。接下來才可能會被大夥邀請成為維護者,或者自行申請成為維護者。
按照這個路徑,劉歧開始刷 Patch。頻繁的程式碼提交行為吸引了時任 FFmpeg 首席維護者 Michael 的目光。不過,Michael 的關注對此刻的劉歧來說是一種“折磨”。
“他頻繁地找我麻煩,不斷地否定我,在我提 Patch 的時候經常測試不通過。”這對劉歧的打擊非常大。現在當我們提到要營造一個良好的開源社群氛圍、留住新鮮血液時,往往認為需要給新加入的貢獻者更多的耐心、更細緻禮貌的指導、適當的鼓勵等等。很顯然,當時的劉歧遇到的是高難度劇本:“那種環境,基本上相當於你在故意刁難我,放到很多人身上肯定就不幹了。但我當時的目標非常明確,我就是要成為維護者,就是要把這件事做成,隨你怎麼刁難我。”
Michael 的“刁難”在事後看來更像是劉歧進階路上的測試。比如指出問題的時候,Michael 也會關注劉歧是否有解決問題的能力,在劉歧解決不了的問題上會耐心的指導。一來二去,兩人的交流漸漸多了起來,劉歧對 FFmpeg 的掌握能力也在日漸精進。
有一天,Michael 問劉歧:有沒有興趣成為維護者?
“誘惑力這麼大的事情,我怎麼可能拒絕!”興奮中的劉歧還特意把這“歷史性”的時刻截圖發給朋友。
就這樣,劉歧成為了維護者中的一員。他想起了曾經看過的一個小故事,當你拔蘿蔔發現某根特別難拔的時候,這個蘿蔔可能是一個非常大的蘿蔔,而你,把它拔出來以後也將會有很大的收穫。“當時想成為維護者,可能就是在拔那個最難拔的蘿蔔。”
2016 年,劉歧成為維護者的第一年,他做的第一件事就是把切片功能標記為“棄用”。到這裡,已經花了他 2 年的時間。
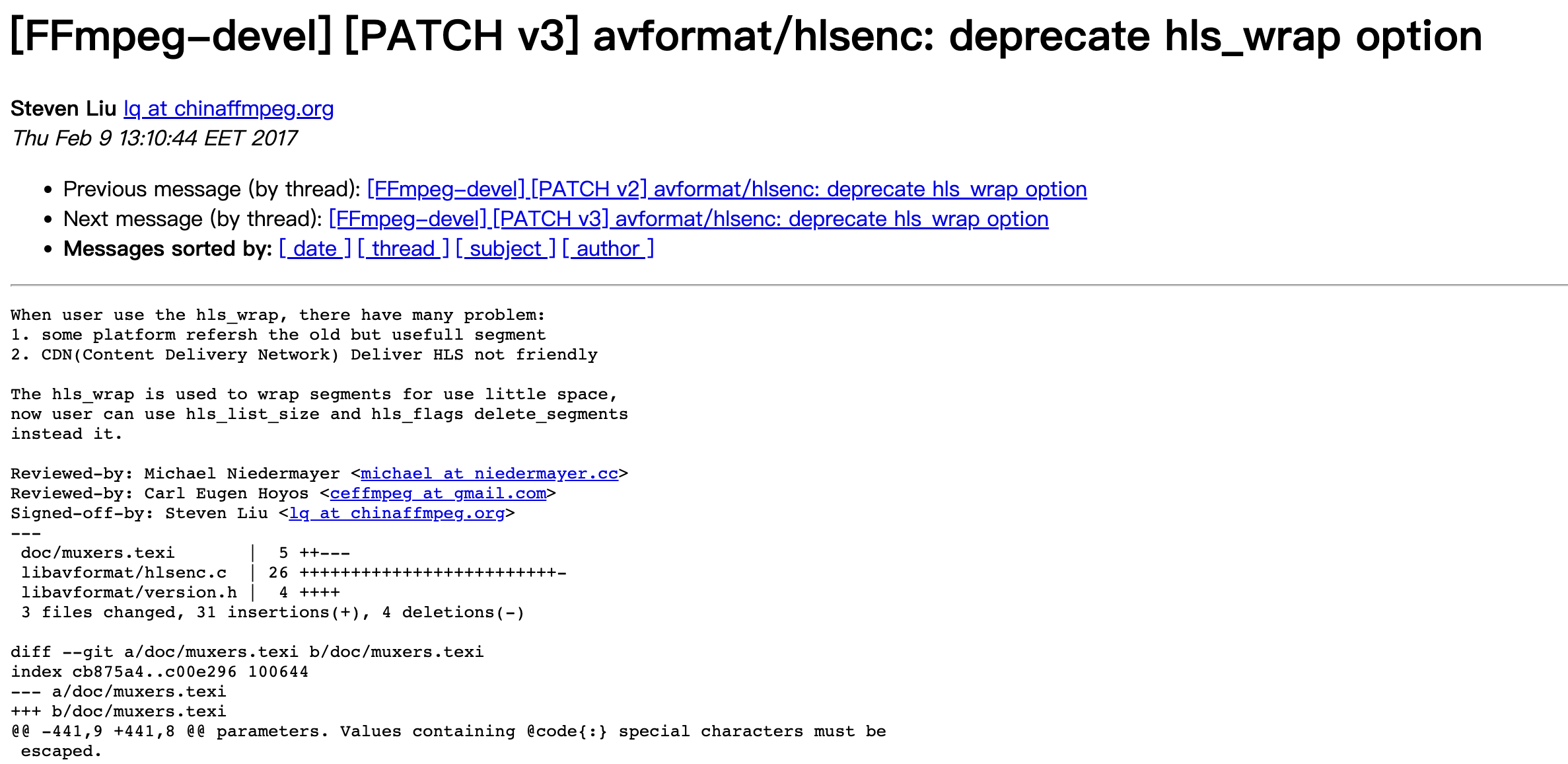
按照 FFmpeg 社群的規定,棄用某項功能時,需要提前警告使用者,並且等到下一次大版本更新的時候,提供替換解決方案,同時舊版本不會下線。劉歧提供了幾個新功能:比如直播時可以刪除舊的片,這樣就無需用回滾的方式,這樣也能節省儲存空間。但是對使用者來說,替換新版本、新功能需要時間,直到今天,還有 FFmpeg 使用者在使用老的 API 介面。對劉歧來說,這是一場持續了 8 年並且還在繼續的戰鬥……
成為顧問
在“棄用”切片功能的過程中,劉歧在 FFmpeg 社群一直沒閒著。從頻繁提交 Patch,到成為單一模組的維護者,慢慢隨著維護的模組越來越多,劉歧逐漸成為了一個通用維護者,2017 年,被推選為 Maintainer 和顧問便成了順理成章的事情。
相較於各個模組的維護者,Maintainer 的許可權更廣,會幫助不同模組的維護者一起 Review。而相較於 Maintainer,顧問的身份除了在社群內部是一個身份標,更重要的是可以代表 FFmpeg 社群去接一些顧問形式的工作,比如面向全球提供付費諮詢服務等等。
2017 年義大利有一家做意甲聯賽版權內容製作的公司在製作視訊內容時用到了 FFmpeg,遇到一個介面上的問題,於是發郵件給劉歧尋求幫助。此類的諮詢劉歧陸續還遇到了一些,費用每小時兩百美金左右,當然,有時候也會免費提供幫助。
這讓劉歧看到了線上音視訊剪輯工具的需求,便萌生了做一個專門的剪輯工具的想法。2017 年,來自朋友的合夥邀約讓這個想法開始落地,劉歧與朋友成立公司一起做剪輯工具,當時,某央媒是他們的客戶之一。雖然這次創業以快手的收購收尾,但在這之後,FFmpeg 社群毫無疑問成為劉歧作為一個技術人精神上的“世外桃源”。
再次成為商業公司程式設計師隊伍中的一份子之後,劉歧更多時候專注在公司本身音視訊基礎技術支援上,短暫地從 FFmpeg 社群“消失”。
“過了一段時間發現太累,就會到 FFmpeg 社群看看最新的架構,程式碼的發展等等,或是看看是不是有可以增加的功能,我就會給支援上。”每次關注 FFmpeg 社群的時候,劉歧會頻繁提交程式碼,“相當於在刷屏。因為你寫程式碼的時候,能夠專注地去思考,寫完之後提 Patch 之後可以和大夥一起交流的過程是很享受的,那是很過癮的,我真的很上癮的。”
“社群中很多人都是這個狀態。”FFmpeg 的維護者中很多是像劉歧一樣的業餘維護者,做這個開發的人來自從事各個專業,比如量子物理博士、大學老師等等。當大家為了同一個技術聚集在一起時,便產生了對個體的強大吸引力,“開源最吸引我的就是跟別人討論技術,因為我這個人比較話癆,喜歡和人交流,在和別人交流的時候能重新整理自己的認知,學到很多東西。”

2019 年,劉歧首次接受 FFmpeg 贊助費用參加 GSoC Mentor Summit,與 FFmpeg 元老 Carl Eugen 合影
開源,一個可以純技術交流的土壤
“坦率地講,FFmpeg 社群沒有治理。”劉歧不喜歡過多討論技術之外的東西,恰好,FFmpeg 社群也很對他的胃口。
這個有著 20 多年的老牌開源專案社群一直以來都非常低調,發展平穩,就連唯一的一次“分裂”都以雙方的握手言和收場。FFmpeg 是法國程式設計師 Fabrice Bellard 在 2000 年發起的專案,Fabrice Bellard 提交了首個 Commit。FFmpeg 單詞中的 “FF” 指的是 “Fast Forward(快速前進)”,MPEG 是制定國際標準的組織,負責制定影音壓縮及傳輸的規格標準。
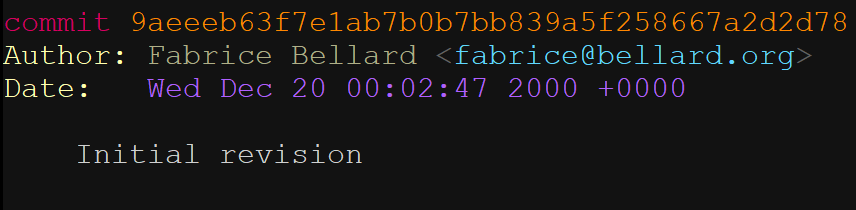
從 2004 年到 2015 年間,Michael Niedermayer 擔任首席維護者,擁有社群的最高決策權。但 Michael 的管理漸漸引起了一些人的不滿,2011 年,部分維護者出走,另建分支 Libav。後來 Libav 逐漸發展成 PC 播放 4K HDR 藍光最好的解決方案。分裂帶來的負面效果是:FFmpeg 專案進入到了一個不確定的時期,分支 Libav 一度比 FFmpeg 更活躍更有活力,於是 Debian 及其衍生髮行版都切換到了 Libav。
但到了 2015 年,Debian 專案布重新用 FFmpeg 取代 Libav,主要原因是 FFmpeg 更新更及時。當時,Libav 專案開發者指責 Michael 將 Libav 的程式碼合併到 FFmpeg,盜用了他們的成果。導致 Libav 在和 FFmpeg 的競爭中是失敗。當然,Michael 的支持者並不同意這個說法。
因為不想看到兩個專案徹底分裂,這次事件最終以 Michael 的辭職收場,Michael 在辭職信中稱,他希望兩個社群最終能合併,Libav 能重新加入 FFmpeg。
“慢慢地,好多人陸陸續續的回來了,兩個社群的程式碼開始合併。”當時的劉歧見證雙方最終的和解。而從那以後,FFmpeg 社群也再沒有設立首席維護者這一位置。
在劉歧看來,社群中的成員聚集在一起是為了讓 FFmpeg 更好,沒有商業目的、也沒有利益可言,因此,決策與發展全靠技術說話。
“你想做一件事,程式碼咔咔提上來之後,大夥沒有明確提出意見就直接合並。”劉歧介紹,大夥沒有管理理念,只會去判斷這件事能不能做,如果有人對提交上來的程式碼有反對意見,往往會指出具體哪裡不好,如果建議合理,提程式碼的人則會去修改。
FFmpeg 社群也曾想過建立一些社群規則。
和大多數開源社群一樣,人人都可以發表看法和意見必然帶來爭吵。據劉歧回憶,FFmpeg 社群的氛圍非常開放的,但是以前會更和諧,隨著後來加入的人多起來,成員間文化背景不同,經常會出現一些人格上的攻擊,在交流的時候會出現毫無原因否定他人的工作成果的狀況時有出現。
所以,在 2019 年,FFmpeg 社群成員東京線下交流會時,大家覺得應該成立一個社群委員會,專門去調和這種矛盾,同時再成立一個技術委員會去討論技術選型。

這兩個想法後來也比較佛系的執行著,用劉歧的話來說就是“還沒到那個地步。”同樣佛系的還有 FFmpeg 恥辱柱。
FFmpeg 提供了視訊解碼、編碼、後期處理等一系列功能,對世界上千奇百怪的視訊音訊編碼有著完善的支援,強大的功能使它成為市面上的許多視訊播放器的解決方案。但是,FFmpeg 也成為了程式碼被盜用得最嚴重的開源軟體之一,不少著名的播放軟體都是 FFmpeg 程式碼的偷竊者。FFmpeg 會將發現的那些不遵守開源協議的軟體名稱公開發布,其列表便被稱為“恥辱柱”。FFmpeg 社群並沒有實際去追究違規專案的責任,“恥辱柱”也在 2011 年停止了更新。
在劉歧的視角里,FFmpeg 社群實際上對於此類技術之外的事件並不十分在意。在他個人看來,開源專案使用者數量巨大,如果追究太多可能會涉及十幾億的使用者,況且 FFmpeg 的許多新功能抄襲者無法複製,“所以對這個事情,我們都比較佛系。”
FFmpeg 社群對劉歧的饋贈也體現在許多方面。比如前文提到的 FFmpeg 社群交流氛圍中常常火藥味十足,但是對劉歧大多數情況下是非常友好的,而且很坦誠、很直接地去指出問題。比如劉歧的程式碼某個地方邏輯確實沒考慮周全,他們就會很清晰地告訴他這個地方的邏輯沒考慮清楚,並不是攻擊。“火藥味我接觸得還比較多,只不過我是一個不太在意甚至可以忽略不計自尊心的人,很多時候我覺得火藥味濃一些是好事,至少大夥對我還是比較尊重的,不會有特別嚴重的人格攻擊。”
在開源社群,劉歧還交到了很好朋友,“這些朋友也會給我提供很多幫助,比如我需要某些資訊的時候,通過社群,大夥會提供給我我想知道的資訊,我想做某個功能的時候,也可以和大家交流,他們也很樂於給我提供一些支援。”
總而言之,這個屬於技術控的開源故事,正在快樂進行中。


2019 東京線下交流會期間 FFmpeg 社群成員合影
【溯源】在每一場對話中,追溯關於開源的故事,認識那些極客、自由,並堅持著的開源人。
OSCHINA 推出的開源人物專訪欄目【溯源】。
溯源,意指向源頭追溯,為開源求解。問渠哪得清如許,為有源頭活水來。每一個開源參與者,都是掀起開源浪潮最鮮活的源泉。所有開源故事,共同構建著我們今天看到的開源世界。
開源剛出現的數十年裡,為開源奔走的黑客團體都在遭受來自社會主流的冷漠和排斥。即便現在的軟體行業已經大喊出 “擁抱開源” 的口號,問題也依然存在。
我們不知道開源貢獻者、開源佈道師,以及所有參與開源的人還會面臨多少阻礙,但給予我們信心的是,更多的人在投身開源事業。
所以 OSCHINA 希望面向開發者社群,尋找每一個積極參與開源、對開源有想法的人,瞭解他們以及他們的開源故事,窺探故事中的開源事業發展規律。
【溯源】系列文章:
- 悟空劉歧:技術瑕疵不除不快,開源社群程式碼說話
- 挖掘非結構化資料潛能——向量資料庫的探索之路
- 【直播回顧】開源許可證冷熱知識大揭祕
- BSL:MySQL 之父關於兼顧開源與活下去的解法
- Jina AI:定義開源神經搜尋,A 輪融資 2 個億
- 學習 Rust 你需要一個認知框架
- 雙許可,我開源的軟體只能我拿來賺錢
- 開放協作的世界裡,每一份貢獻都值得回報
- 開源軟體出口管制合規政策與管控策略研究
- 當你瞭解了 Apahce 的過去,你就瞭解了 Apache Way
- 社群糾紛不斷:程式設計師何苦為難程式設計師
- 婦女節,見證女性科技力量
- 中年 Hadoop
- 寫了開源軟體沒申專利,反被索賠該怎麼辦?
- 嚴父 Rust
- 成立兩年不談營收,這家公司在想什麼?
- “Dying since 1995”的 PHP 怎麼還活著
- Rust 社群求變,PHP 大旗不倒?
- 對話西喬霍炬,什麼塑造了今天的程式設計世界?
- 如何評價一個開源專案(三)——價值流網路