提高IT運維效率,深度解讀京東雲基於自然語言處理的運維日誌異常檢測AIOps落地實踐
作者:京東科技 張憲波、張靜、李東江
基於NLP技術對運維日誌聚類,從日誌角度快速發現線上業務問題
日誌在IT行業中被廣泛使用,日誌的異常檢測對於識別系統的運行狀態至關重要。解決這一問題的傳統方法需要複雜的基於規則的有監督方法和大量的人工時間成本。我們提出了一種基於自然語言處理技術運維日誌異常檢測模型。為了提高日誌模板向量的質量,我們改進特徵提取,模型中使用了詞性(PoS)和命名實體識別(NER)技術,減少了規則的參與,利用 NER 的權重向量對模板矢量進行了修改,分析日誌模板中每個詞的 PoS 屬性,從而減少了人工標註成本,有助於更好地進行權重分配。為了修改模板向量,引入了對日誌模板標記權重的方法,並利用深度神經網絡(DNN)實現了基於模板修正向量的最終檢測。我們的模型在三個數據集上進行了有效性測試,並與兩個最先進的模型進行了比較,評估結果表明,我們的模型具有更高的準確度。
日誌是記錄操作系統等 IT 領域中的操作狀態的主要方法之一,是識別系統是否處於健康狀態的重要資源。因此,對日誌做出準確的異常檢測非常重要。日誌異常一般有三種類型,即異常個體日誌、異常日誌序列和異常日誌定量關係。我們主要是識別異常個體日誌,即包含異常信息的日誌。
一般來説,日誌的異常檢測包括三個步驟: 日誌解析、特徵提取和異常檢測。解析工具提取的模板是文本數據,應將其轉換為數字數據,以便於輸入到模型中。為此,特徵提取對於獲得模板的數字表示是必要的。在模板特徵提取方面,業界提出了多種方法來完成這一任務。獨熱編碼是最早和最簡單的方法之一,可以輕鬆地將文本模板轉換為便於處理的數字表示,但是獨熱編碼是一種效率較低的編碼方法,它佔用了太多的儲存空間來形成一個零矢量,而且在使用獨熱編碼時,忽略了日誌模板的語義信息。除了這種方便的編碼方法外,越來越多的研究人員應用自然語言處理(NLP)技術來實現文本的數字轉換,其中包括詞袋,word2vec 等方法。雖然上述方法可以實現從文本數據到數字數據的轉換,但在日誌異常檢測方面仍然存在一些缺陷。詞袋和 word2vec 考慮到模板的語義信息,可以有效地獲得單詞向量,但是它們缺乏考慮模板中出現的每個模版詞的重要性調節能力。此外,深度神經網絡(DNN)也被用於模板的特徵提取。
我們的模型主要改進特徵提取,同時考慮每個標記的模版詞語義信息和權重分配,因為標記結果對最終檢測的重要性不同。我們利用兩種自然語言處理技術即PoS和命名實體識別(NER),通過以下步驟實現了模板特徵的提取。具體來説,首先通過 FT-Tree 將原始日誌消息解析為日誌模板,然後通過 PoS 工具對模板進行處理,獲得模板中每個詞的 PoS 屬性,用於權重向量計算。同時,通過 word2vec 將模板中的標記向量化為初始模板向量,並利用權值向量對初始模板向量進行進一步修改,那些重要的模版詞的 PoS屬性將有助於模型更好地理解日誌含義。對於標記完 PoS 屬性的模版詞,詞對異常信息識別的重要性是不同的,我們使用 NER 在模版的 PoS屬性中找出重要性高的模版詞,並且被 NER 識別為重要的模版詞將獲得更大的權重。然後,將初始模板向量乘以這個權重向量,生成一個複合模板向量,輸入到DNN模型中,得到最終的異常檢測結果。為了減少對日誌解析的人力投入,併為權重計算做準備,我們採用了 PoS 分析方法,在不引入模板提取規則的情況下,對每個模版詞都標記一個 PoS 屬性。
解析模板的特徵提取過程是異常檢測的一個重要步驟,特徵提取的主要目的是將文本格式的模板轉換為數字向量,業界提出了各種模板特徵提取方法:
One-hot 編碼:在 DeepLog 中,來自一組 k 模板ti,i∈[0,k)的每個輸入日誌模板都被編碼為一個One-hot編碼。在這種情況下,對於日誌的重要信息ti 構造了一個稀疏的 k 維向量 V = [ v0,v1,... ,vk-1] ,並且滿足j不等於i, j∈[0,k),使得對於所有vi= 1和 vj = 0。
**自然語言處理(NLP):**為了提取日誌模板的語義信息並將其轉換為高維向量,LogRobust 利用現成的 Fast-Text 算法從英語詞彙中提取語義信息,能夠有效地捕捉自然語言中詞之間的內在關係(即語義相似性) ,並將每個詞映射到一個 k 維向量。使用 NLP 技術的各種模型也被業界大部分人使用,如 word2vec 和 bag-of-words 。
**深度神經網絡(DNN):**與使用 word2vec 或 Fast-Text 等細粒度單元的自然語言處理(NLP)不同,LogCNN 生成基於29x128codebook的日誌嵌入,該codebook是一個可訓練的層,在整個訓練過程中使用梯度下降進行優化。
**Template2Vec:**是一種新方法,基於同義詞和反義詞來有效地表示模板中的詞。在 LogClass 中,將經典的加權方法 TF-IDF 改進為 TF-ILF,用逆定位頻率代替逆文檔頻率,實現了模板的特徵構造。
一段原始日誌消息是一個半結構化的文本,比如一個從在線支付應用程序收集的錯誤日誌讀取為: HttpUtil-request 連接失敗,Read timeout at jave.net。它通常由兩部分組成,變量和常量(也稱為模板)。對於識別個體日誌的異常檢測,目的是從原始日誌解析的模板中識別是否存在異常信息。我們的模型使用 PoS 分析以及 NER 技術來進行更精確和省力的日誌異常檢測。PoS 有助於過濾標記有不必要的 PoS 屬性的模版詞,NER的目標是將重要性分配給所有標記為重要的 PoS 屬性的模版詞。然後通過模板向量和權向量的乘積得到複合模板向量。
我們的日誌異常檢測模型包括六個步驟,即模板解析、 PoS分析、初始向量構造、基於NER的權重計算、複合向量和最終檢測。檢測的整個過程如圖1所示:
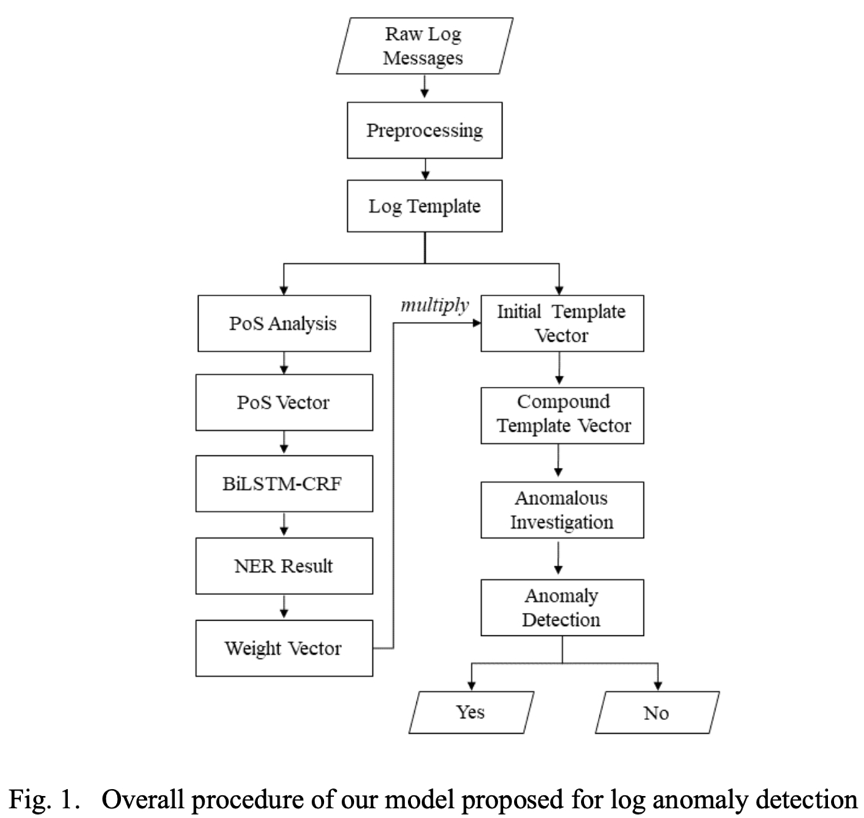
第一步:模板解析
初始日誌是半結構化的文本,它們包含一些不必要的信息,可能會造成混亂或阻礙日誌檢測。因此,需要預處理來省略變量,比如一些數字或符號,並提取常量,即模板。以前面提到的日誌消息為例,原始日誌HttpUtil-request 連接[wx/v1/pay/prepay]的模板失敗,Read timeout at jave.net。可以提取為: HttpUtil 請求連接 * 失敗讀取時間為 * 。我們使用簡單而有效的方法 FT-Tree 來實現日誌解析,我們沒有引入複雜的基於規則的規則來去除那些不太重要的標記,比如停止詞。
第二步:PoS 分析
上一步的模版解析結果只有英語單詞、短語和一些非母語單詞保留在解析好的模板中,這些模版詞具有各種 PoS 屬性,例如 VB 和 NN。根據我們對大量日誌模板的觀察,一些 PoS 屬性對於模型理解模板所傳達的意義很重要,而其他屬性可以忽略。如圖3所示,解析模板中的單詞“ at”在理論上是不必要的,相應的 PoS 屬性“ IN”也是不必要的,即使去掉 IN 的標記,我們仍然可以判斷模板是否正常。因此,在我們得到了 PoS 向量之後,我們可以通過去掉那些具有特定 PoS 屬性的模版詞來簡化模板。剩餘的模版詞對於模型更好地理解模板內容非常重要。
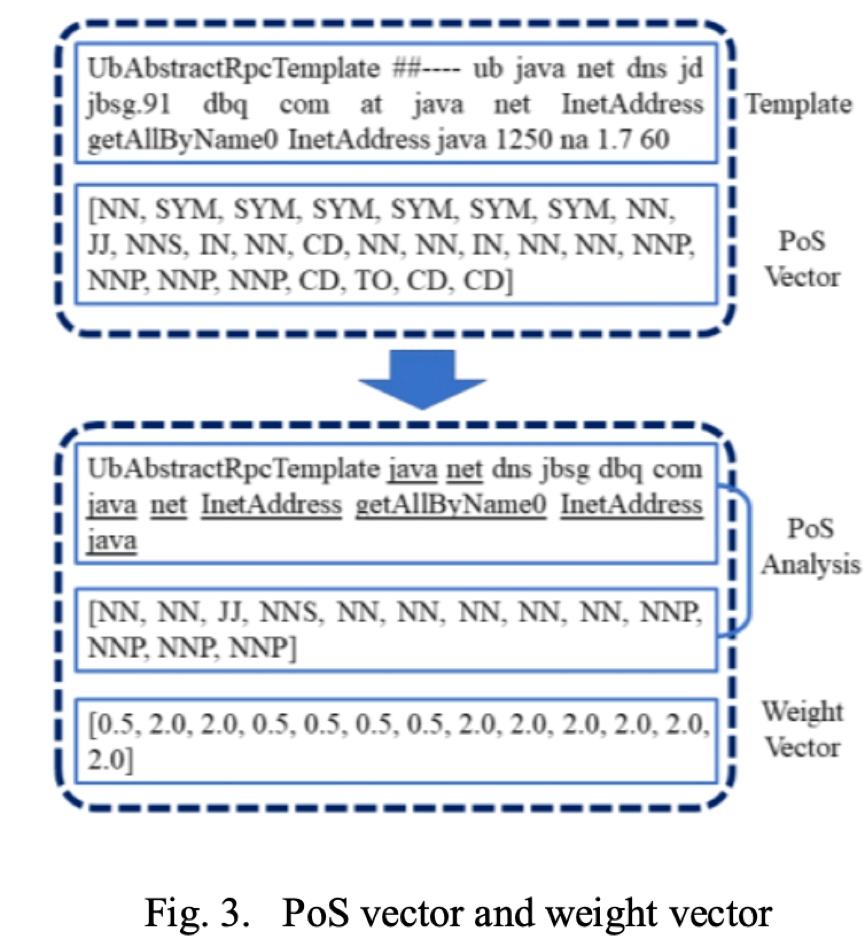
第三步:初始模板向量構造
在獲得 PoS 矢量的同時,模板也被編碼成數字向量。為了考慮模板的語義信息,在模型中使用 word2vec 來構造模板的初始向量。該初始向量將與下一步得到的權重向量相乘,得到模板的複合優化表示。
第四步: 權重分析
首先對模板中的模版詞進行 PoS 分析處理,剔除無意義的模版詞。至於其餘的模版詞,有些是關鍵的,用於傳達基本信息,如服務器操作、健康狀態等。其他的可能是不太重要的信息,比如動作的對象、警告級別等等。為了加大模型對這些重要模版詞的學習力度,我們構造了一個權重向量來突出這些重要的模版詞。為此,我們採用了 NER 技術,通過輸入已定義的重要實體,學習挑選標記為重要實體的所有模版詞。該過程如圖所示:
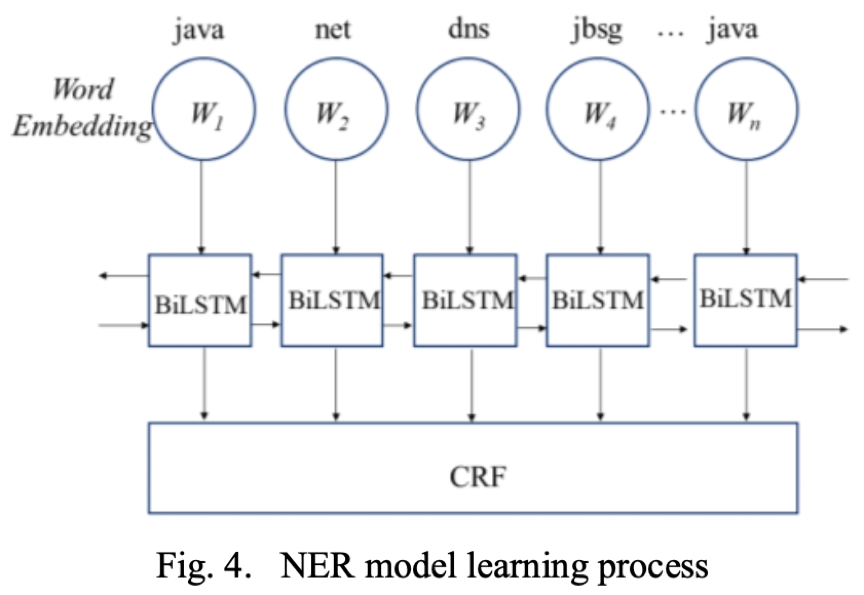
CRF 是 NER 通常使用的工具,它也被用於我們的模型識別模版詞的重要性。也就是説,通過向模型提供標記為重要的模版詞,模型可以學習識別那些未標註的日誌的重要的模版詞。一旦模板中的模版詞被 CRF 識別出來,相應的位置就會賦予一個權重值(2.0)。因此,我們得到一個權向量 W。
第五步:複合向量
在獲得權重向量 W 之後,通過將初始向量 V’乘以權重向量 W,可以得到一個表示模板的複合優化向量 V。重要的模版詞分配更大權重,而其他的模版詞分配更小的。
第六步:異常檢測
將第五步得到的複合矢量 v 輸入到最終全連接層中,以便進行異常檢測。完全連通層的輸出分別為0或1,表示正常或異常。
•模型評估
我們通過實驗驗證了該模型對日誌異常檢測的改進效果。採用了兩個公共數據集,以及一套我們內部數據集,來驗證我們模型的實用性。我們將自己的結果與業界針對日誌異常檢測提出的兩個Deeplog 和 LogClass模型進行了比較。
CANet 的框架是用 PyTorch 構建的,我們在35個訓練週期中選擇新加坡隨機梯度下降(SGD)作為優化器。學習速度設定為2e4。所有的超參數都是從頭開始訓練的。
**(1)數據集:**我們選取了兩套公共集和一套公司內部數據集進行模型評估,BGL 和 HDFS 都是用於日誌分析的兩個常用公共數據集:**HDFS:是從運行基於 Hadoop 的作業的200多個 Amazon EC2節點收集的。它由11,175,629條原始日誌消息組成,16,838條被標記為“異常”。BGL:**收集自 BlueGene/L 超級計算機系統 ,包含4,747,963條原始日誌消息,其中348,469條是異常日誌。每條日誌消息都被手動標記為異常或者正常。**數據集 A:**是從我們公司內部收集來進行實際驗證的數據集。它包含915,577條原始日誌消息和210,172條手動標記的異常日誌。
**(2)base模型:**我們將自己的模型在三個數據集上,與兩個業界最先進的模型(DeepLog和LogClass)進行比較:DeepLog: 是一個基於深度神經網絡的模型,利用長短期記憶(LSTM)來實現檢測。DeepLog 採用一次性編碼作為模板向量化方法。LogClass: LogClass 提出了一種新的方法——逆定位頻率(ILF) ,在特徵構造中對日誌文字進行加權。這種新的加權方法不同於現有的反文檔頻率(IDF)加權方法。
**(3)模型評估結果:**我們從Precision、Recall和F1-score三個方面評估兩個base模型和我們的模型的異常檢測效果,在 HDFS 數據集上,我們的模型獲得了最高的 F1得分0.981,此外,我們的模型在召回方面也表現最好。LogClass 在Precision上取得了最好的成績,比我們的稍微高一點。在第二套數據集BGL上,我們的模型在召回率Recall(0.991)和 F1-score (0.986)方面表現最好,但在Precision上略低於 LogClass。在第三套數據集 A 上三個模型的性能,我們的模型實現了最佳性能,其次是 LogClass。
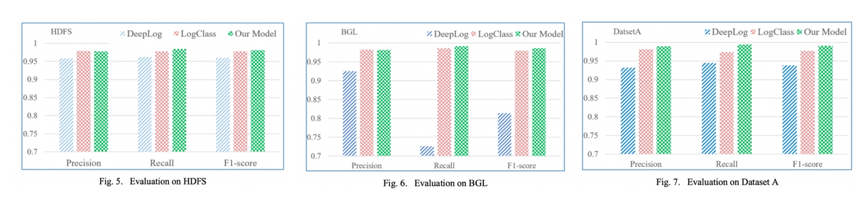
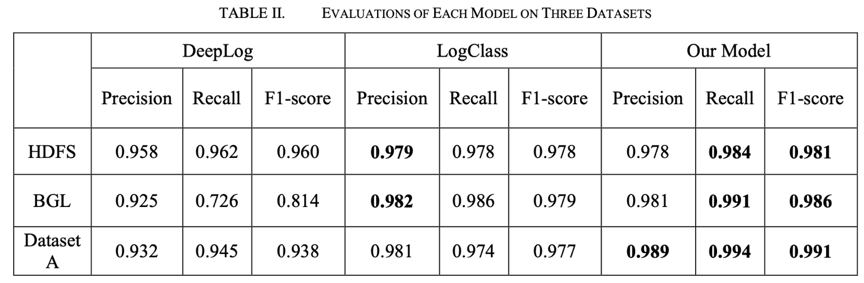
在所有的數據集中,我們的模型具有最好的 F1得分和最高的召回率,這意味着我們的模型造成的不確定性更小。
•Natural Language Processing-based Model for Log Anomaly Detection. SEAI.
•**ieeexplore檢索:**http://ieeexplore.ieee.org/abstract/document/9680175

•Themis智能運維平台智能文本分析功能視圖:(http://jdtops.jd.com/)

- 應用健康度隱患刨析解決系列之數據庫時區設置
- 對於Vue3和Ts的心得和思考
- 一文詳解擴散模型:DDPM
- zookeeper的Leader選舉源碼解析
- 一文帶你搞懂如何優化慢SQL
- 京東金融Android瘦身探索與實踐
- 微前端框架single-spa子應用加載解析
- cookie時效無限延長方案
- 聊聊前端性能指標那些事兒
- Spring竟然可以創建“重複”名稱的bean?—一次項目中存在多個bean名稱重複問題的排查
- 京東金融Android瘦身探索與實踐
- Spring源碼核心剖析
- 深入淺出RPC服務 | 不同層的網絡協議
- 安全測試之探索windows遊戲掃雷
- 關於數據庫分庫分表的一點想法
- 對於Vue3和Ts的心得和思考
- Bitmap、RoaringBitmap原理分析
- 京東小程序CI工具實踐
- 測試用例設計指南
- 當你對 redis 説你中意的女孩是 Mia