JNI 中錯誤的信號處理導致 JVM 崩潰問題分析
編者按:JNI 是 Java 和 C 語言交互的主要手段,要想做好 JNI 的編程並不容易,需要了解 JVM 內部機理才能避免一些錯誤。本文分析 Cassandra 使用 JNI 本地庫導致 JVM 崩潰的一個案例,最後定位問題根源是信號的錯誤處理(一些 C 編程人員經常會截獲信號,做一些額外的處理),該案例提示 JNI 編程時不要隨意截獲信號處理。
現象
在使用 Cassandra 時遇到運行時多個位置都有發生 crash 現象,並且沒有 hs_err 文件生成,這裏列舉了其中一個 crash 位置:
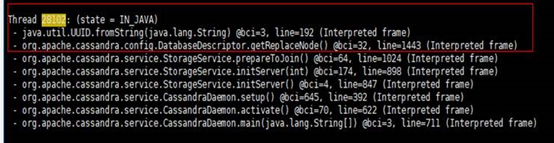
分析
首先直接基於上面這個 crash 的 core 文件展開分析,下面分別是對應源碼上下文和指令上下文:

使用 GDB 調試對應的 core 文件,如下圖所示:
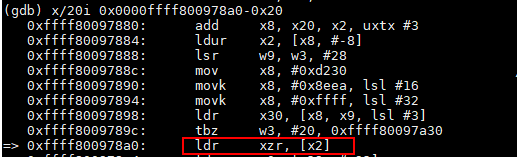
在 GDB 中進行單步調試(GDB 調試可以參考官方文檔),配合源代碼發現 crash 的原因是傳入的 name 為 null,導致調用 name.split("\_") 時觸發了 SIGSEGV 信號,直接 crash。暫時拋開這個方法傳入 name 為 null 是否有問題不論,從 JVM 運行的機制來説,這裏有個疑問,遇到一個 Null Pointer 為什麼不是拋出 Null Pointer Exception(簡稱 NPE)而是直接 crash 了呢?
這裏有一個知識需要普及一下:Java 層面的 NPE 主要分為兩類,一類是代碼中主動拋出 NPE 異常,並被 JVM 捕獲 (這裏的代碼既可以是 Java 代碼,也可以是 JVM 內部代碼);另一類隱式 NPE(其原理是 JVM 內部遇到空指針訪問,會產生 SIGSEGV 信號, 在 JVM 內部還會檢查運行時是否存在 SIGSEGV 信號)。
帶着上面的疑問,又看了幾處其他位置的 crash,發現都是因為對象為 null 導致的 SIGSEGV,卻都沒有拋出 NPE,而是直接 crash 了,再結合都沒有 hs_err 文件生成的現象, hs_err 文件生成功能位於 JVM 的 SIGSEGV 信號處理函數中,代碼如下:
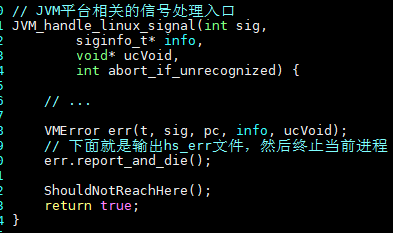
由於 hs_err 文件沒有產生,一個很自然的推斷:Cassandra 運行中可能篡改了或者捕獲了 SIGSEGV 信號,並且可能做了處理,以至於 JVM 無法正常處理 SIGSEGV 信號。
然後排查業務方是否在 Cassandra 中用到了自定義的第三方 native 庫,果然筆者所猜測的,有兩個 native 庫裏都對 SIGSEGV 信號做了捕獲,註釋掉這些代碼後重新跑對方的業務,crash 現象不再發生,問題(由於 Cassandra 中對 NPE 有異常處理導致 JVM 崩潰)解決。
總結
C/C++ 的組件在配合 Java 一起使用時,需要注意的一點就是不要隨意去捕獲系統信號,特別是 SIGSEGV、SIGILL、SIGBUS 等,因為會覆蓋掉 JVM 中的信號捕獲邏輯。附錄 這裏貼一個 demo 可以用來複現 SIGSEGV 信號覆蓋造成的後果,有興趣的可以跑一下:
// JNITest.java
import java.util.UUID;
public class JNITest {
public static void main(String[] args) throws Exception {
System.loadLibrary("JNITest");
UUID.fromString(null);
}
}
// JNITest.c
#include <signal.h>
#include <jni.h>
JNIEXPORT
jint JNICALL JNI_OnLoad(JavaVM *jvm, void *reserved) {
signal(SIGSEGV, SIG_DFL);//如果註釋這條語句,在運行時會出現 NullPointerExcetpion 異常
return JNI_VERSION_1_8;
}
通過 GCC 編譯並執行就可以觸發相同的問題,編譯執行命令如下:
$ gcc -Wall -shared -fPIC JNITest.c -o libJNITest.so -I$JAVA_HOME/include -I$JAVA_HOME/include/linux
$ javac JNITest.java
\$ java -Xcomp -Djava.library.path=./ JNITest
後記
如果遇到相關技術問題(包括不限於畢昇 JDK),可以進入畢昇 JDK 社區查找相關資源(點擊原文進入官網),包括二進制下載、代碼倉庫、使用教學、安裝、學習資料等。畢昇 JDK 社區每雙週週二舉行技術例會,同時有一個技術交流羣討論 GCC、LLVM、JDK 和 V8 等相關編譯技術,感興趣的同學可以添加如下微信小助手,回覆 Compiler 入羣。

本文分享自微信公眾號 - openEuler(openEulercommunity)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- 玩轉機密計算從 secGear 開始
- openEuler資源利用率提升之道06:虛擬機混部OpenStack調度
- openGauss Cluster Manager RTO Test
- JVM 鎖 bug 導致 G1 GC 掛起問題分析和解決【畢昇JDK技術剖析 · 第 2 期】
- 手把手帶你玩轉 openEuler | openEuler 的使用
- 681名學生中選!暑期2021開啟火熱“開源之夏”!
- 手把手帶你玩轉 openEuler | 初識 openEuler
- StratoVirt 中的 PCI 設備熱插拔實現
- 使用 NMT 和 pmap 解決 JVM 資源泄漏問題
- JNI 中錯誤的信號處理導致 JVM 崩潰問題分析
- Java Flight Recorder - 事件機制詳解
- 畢昇 JDK 8u292、11.0.11 發佈!
- StratoVirt 中的虛擬網卡是如何實現的?
- openEuler結合ebpf提升ServiceMesh服務體驗的探索
- 我的openEuler社區參與之旅
- StratoVirt 的中斷處理是如何實現的?
- 看看畢昇 JDK 團隊是如何解決 JVM 中 CMS 的 Crash
- 使用 perf 解決 JDK8 小版本升級後性能下降的問題【畢昇JDK技術剖析 · 第 1 期】
- 2021年畢昇 JDK 的第一個重要更新來了
- 漏洞盒子 × openEuler | 廣邀白帽共築安全的Linux開放應用生態