程式碼實戰帶你瞭解深度學習中的混合精度訓練
摘要:本文為大家介紹一下深度學習中的混合精度訓練,並通過程式碼實戰的方式為大家講解實際應用的理論,並對模型進行測試。
本文分享自華為雲社群《淺談深度學習中的混合精度訓練》,作者:李長安。
1 混合精度訓練
混合精度訓練最初是在論文Mixed Precision Training中被踢出,該論文對混合精度訓練進行了詳細的闡述,並對其實現進行了講解,有興趣的同學可以看看這篇論文。
1.1半精度與單精度
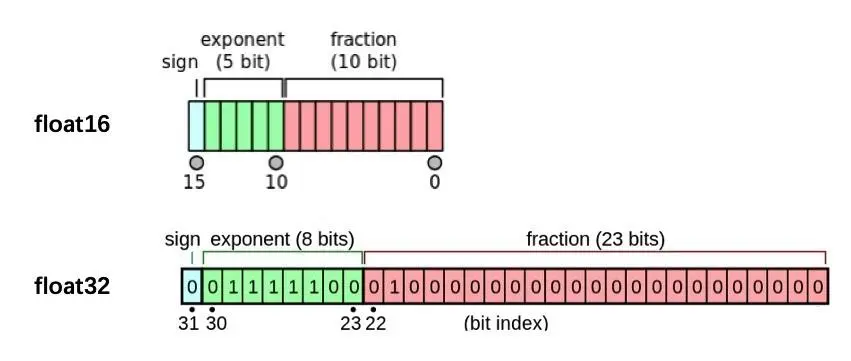
半精度(也被稱為FP16)對比高精度的FP32與FP64降低了神經網路的視訊記憶體佔用,使得我們可以訓練部署更大的網路,並且FP16在資料轉換時比FP32或者FP64更節省時間。
單精度(也被稱為32-bit)是通用的浮點數格式(在C擴充套件語言中表示為float),64-bit被稱為雙精度(double)。
如圖所示,我們能夠很直觀的看到半精度的儲存空間是單精度儲存空間的一半。
1.2為什麼使用混合精度訓練
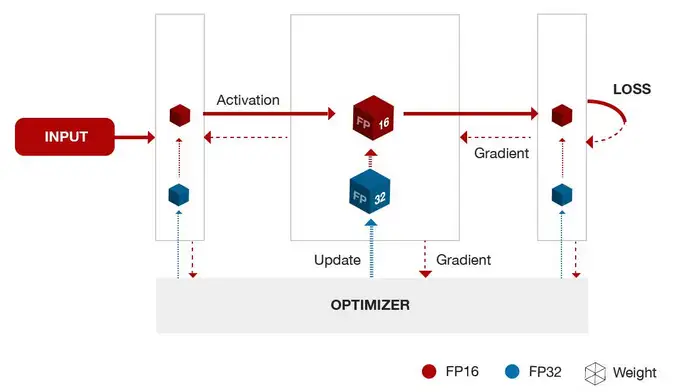
混合精度訓練,指代的是單精度 float和半精度 float16 混合訓練。
float16和float相比恰裡,總結下來就是兩個原因:記憶體佔用更少,計算更快。
記憶體佔用更少:這個是顯然可見的,通用的模型 fp16 佔用的記憶體只需原來的一半。memory-bandwidth 減半所帶來的好處:
模型佔用的記憶體更小,訓練的時候可以用更大的batchsize。
模型訓練時,通訊量(特別是多卡,或者多機多卡)大幅減少,大幅減少等待時間,加快資料的流通。
計算更快:目前的不少GPU都有針對 fp16 的計算進行優化。論文指出:在近期的GPU中,半精度的計算吞吐量可以是單精度的 2-8 倍;
損失控制原理:
2 實驗設計
本次實驗主要從兩個方面進行測試,分別在精度和速度兩個部分進行對比。實驗中採用ResNet-18作為測試物件,使用的資料集為美食資料集,共五種類別。
# 解壓資料集
!cd data/data64280/ && unzip -q trainset.zip2.1資料集預處理
import pandas as pd
import numpy as np
import os
all_file_dir = 'data/data64280/trainset'
img_list = []
label_list = []
label_id = 0
class_list = [c for c in os.listdir(all_file_dir) if os.path.isdir(os.path.join(all_file_dir, c))]
for class_dir in class_list:
image_path_pre = os.path.join(all_file_dir, class_dir)
for img in os.listdir(image_path_pre):
img_list.append(os.path.join(image_path_pre, img))
label_list.append(label_id)
label_id += 1
img_df = pd.DataFrame(img_list)
label_df = pd.DataFrame(label_list)
img_df.columns = ['images']
label_df.columns = ['label']
df = pd.concat([img_df, label_df], axis=1)
df = df.reindex(np.random.permutation(df.index))
df.to_csv('food_data.csv', index=0)
import pandas as pd
# 讀取資料
df = pd.read_csv('food_data.csv')
image_path_list = df['images'].values
label_list = df['label'].values
# 劃分訓練集和校驗集
all_size = len(image_path_list)
train_size = int(all_size * 0.8)
train_image_path_list = image_path_list[:train_size]
train_label_list = label_list[:train_size]
val_image_path_list = image_path_list[train_size:]
val_label_list = label_list[train_size:]2.2自定義資料集
import numpy as np
from PIL import Image
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle as pd
class MyDataset(Dataset):
"""
步驟一:繼承paddle.io.Dataset類
"""
def __init__(self, image, label, transform=None):
"""
步驟二:實現建構函式,定義資料讀取方式,劃分訓練和測試資料集
"""
super(MyDataset, self).__init__()
imgs = image
labels = label
self.labels = labels
self.imgs = imgs
self.transform = transform
# self.loader = loader
def __getitem__(self, index): # 這個方法是必須要有的,用於按照索引讀取每個元素的具體內容
fn = self.imgs
label = self.labels
# fn是圖片path #fn和label分別獲得imgs[index]也即是剛才每行中word[0]和word[1]的資訊
for im,la in zip(fn, label):
img = Image.open(im)
img = img.convert("RGB")
img = np.array(img).astype('float32') / 255.0
label = np.array([la]).astype(dtype='int64')
# 按照路徑讀取圖片
if self.transform is not None:
img = self.transform(img)
# 資料標籤轉換為Tensor
return img, label
# return回哪些內容,那麼我們在訓練時迴圈讀取每個batch時,就能獲得哪些內容
# ********************************** #使用__len__()初始化一些需要傳入的引數及資料集的呼叫**********************
def __len__(self):
# 這個函式也必須要寫,它返回的是資料集的長度,也就是多少張圖片,要和loader的長度作區分
return len(self.imgs)2.3訓練準備
import paddle
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
import paddle.vision.transforms as T
transform = T.Compose([
T.Resize([224, 224]),
T.ToTensor(),
# T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
# T.Transpose(),
])
train_dataset = MyDataset(image=train_image_path_list, label=train_label_list ,transform=transform)
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=16, shuffle=True)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import paddle
from paddle import ParamAttr
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout
from paddle.nn import AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
from paddle.nn.initializer import Uniform
import math
__all__ = ["ResNet18", "ResNet34", "ResNet50", "ResNet101", "ResNet152"]
class ConvBNLayer(nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None,
data_format="NCHW"):
super(ConvBNLayer, self).__init__()
self._conv = Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
data_format=data_format)
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
self._batch_norm = BatchNorm(
num_filters,
act=act,
param_attr=ParamAttr(name=bn_name + "_scale"),
bias_attr=ParamAttr(bn_name + "_offset"),
moving_mean_name=bn_name + "_mean",
moving_variance_name=bn_name + "_variance",
data_layout=data_format)
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None,
data_format="NCHW"):
super(BottleneckBlock, self).__init__()
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act="relu",
name=name + "_branch2a",
data_format=data_format)
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2b",
data_format=data_format)
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c",
data_format=data_format)
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride,
name=name + "_branch1",
data_format=data_format)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
class BasicBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None,
data_format="NCHW"):
super(BasicBlock, self).__init__()
self.stride = stride
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2a",
data_format=data_format)
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
act=None,
name=name + "_branch2b",
data_format=data_format)
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
stride=stride,
name=name + "_branch1",
data_format=data_format)
self.shortcut = shortcut
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv1)
y = F.relu(y)
return y
class ResNet(nn.Layer):
def __init__(self, layers=50, class_dim=1000, input_image_channel=3, data_format="NCHW"):
super(ResNet, self).__init__()
self.layers = layers
self.data_format = data_format
self.input_image_channel = input_image_channel
supported_layers = [18, 34, 50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(
supported_layers, layers)
if layers == 18:
depth = [2, 2, 2, 2]
elif layers == 34 or layers == 50:
depth = [3, 4, 6, 3]
elif layers == 101:
depth = [3, 4, 23, 3]
elif layers == 152:
depth = [3, 8, 36, 3]
num_channels = [64, 256, 512,
1024] if layers >= 50 else [64, 64, 128, 256]
num_filters = [64, 128, 256, 512]
self.conv = ConvBNLayer(
num_channels=self.input_image_channel,
num_filters=64,
filter_size=7,
stride=2,
act="relu",
name="conv1",
data_format=self.data_format)
self.pool2d_max = MaxPool2D(
kernel_size=3,
stride=2,
padding=1,
data_format=self.data_format)
self.block_list = []
if layers >= 50:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
if layers in [101, 152] and block == 2:
if i == 0:
conv_name = "res" + str(block + 2) + "a"
else:
conv_name = "res" + str(block + 2) + "b" + str(i)
else:
conv_name = "res" + str(block + 2) + chr(97 + i)
bottleneck_block = self.add_sublayer(
conv_name,
BottleneckBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block] * 4,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name,
data_format=self.data_format))
self.block_list.append(bottleneck_block)
shortcut = True
else:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
basic_block = self.add_sublayer(
conv_name,
BasicBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block],
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name,
data_format=self.data_format))
self.block_list.append(basic_block)
shortcut = True
self.pool2d_avg = AdaptiveAvgPool2D(1, data_format=self.data_format)
self.pool2d_avg_channels = num_channels[-1] * 2
stdv = 1.0 / math.sqrt(self.pool2d_avg_channels * 1.0)
self.out = Linear(
self.pool2d_avg_channels,
class_dim,
weight_attr=ParamAttr(
initializer=Uniform(-stdv, stdv), name="fc_0.w_0"),
bias_attr=ParamAttr(name="fc_0.b_0"))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for block in self.block_list:
y = block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, shape=[-1, self.pool2d_avg_channels])
y = self.out(y)
return y
def ResNet18(**args):
model = ResNet(layers=18, **args)
return model2.4訓練過程定義
import paddle
import numpy
import paddle.nn.functional as F
import time
def train(model):
model.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 用Adam作為優化函式
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
# print(y_data)
predicts = model(x_data)
loss = F.cross_entropy(predicts, y_data)
# 計算損失
acc = paddle.metric.accuracy(predicts, y_data, k=2)
loss.backward()
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
optim.step()
optim.clear_grad()
import paddle
import numpy
import paddle.nn.functional as F
import time
def train_amp(model):
model.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 用Adam作為優化函式
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0].astype('float16')
y_data = data[1]
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
with paddle.amp.auto_cast():
predicts = model(x_data)
loss = F.cross_entropy(predicts, y_data)
scaled = scaler.scale(loss) # scale the loss
scaled.backward() # do backward
acc = paddle.metric.accuracy(predicts, y_data, k=2)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(),
acc.numpy()))
optim.step()
optim.clear_grad()2.5開啟訓練
此部分,分別對兩種訓練方式進行對比,主要關注模型的訓練速度
model = ResNet18(class_dim=2)
strat = time.time()
train(model)
end = time.time()
print('no_amp:', end-strat)
epoch: 0, batch_id: 0, loss is: [0.21116894], acc is: [1.]
epoch: 1, batch_id: 0, loss is: [0.00010776], acc is: [1.]
epoch: 2, batch_id: 0, loss is: [2.5868081e-05], acc is: [1.]
epoch: 3, batch_id: 0, loss is: [1.442422e-05], acc is: [1.]
epoch: 4, batch_id: 0, loss is: [1.1086402e-05], acc is: [1.]
no_amp: 740.6813971996307
strat1 = time.time()
train_amp(model)
end1 = time.time()
print('with amp:', end1-strat1)
epoch: 0, batch_id: 0, loss is: [0.512834], acc is: [1.]
epoch: 1, batch_id: 0, loss is: [0.00025519], acc is: [1.]
epoch: 2, batch_id: 0, loss is: [5.9364465e-05], acc is: [1.]
epoch: 3, batch_id: 0, loss is: [3.2305197e-05], acc is: [1.]
epoch: 4, batch_id: 0, loss is: [2.4556812e-05], acc is: [1.]
with amp: 740.96032285690313 總結
對於本次實驗,由於迭代輪數較少,只迭代了5次,故時間上的優勢沒有體現出來,大家有興趣的可以增加迭代次數,或者換更深的網路進行測試。
從訓練的結果來看,使用混合精度訓練,其loss值是高於未使用混合精度訓練模型的。
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析