圖數據庫在中國移動金融風控的落地應用
本文整理自中國移動算法工程師——汪海濤在 NebulaGraph 2022 年度用户大會上的分享,現場視頻見 B 站:http://www.bilibili.com/video/BV1Ae4y127a8/
各位朋友上午好,我是來自中國移動的算法工程師汪海濤。接下來我主要聊一聊圖數據庫在中國移動,特別是金融風控場景的落地應用。
為什麼中國移動要建設圖平台?
全國 9 億用户,每天產生大量數據
中國移動有非常多的數據,全國的用户每天都會產生海量的數據。如何從這麼大數據量裏面挖掘出有用的信息,然後用到金融風控場景?這就是我們需要做的事情。
之前,我們是以手機號為維度去提取特徵,然後去做一些模型或規則判斷一個手機號是否是有違約風險。但僅僅基於手機號很難綜合去考慮風險情況,因此我們就想採用圖計算技術去綜合看一個手機號以及周圍的其他手機號的信息,然後共同評判它的風險。
最開始是基於消費金融的場景,從比如説像螞蟻金服、微信以及京東白條這樣一些產品切入,通過用户通話數據、短信數據、設備等多維度的一些信息,去判斷用户風險。但中國移動數據量這麼大,不管我們要做什麼,最大的訴求就是需要有一個非常高性能的平台去支撐數據分析。
為什麼選擇 NebulaGraph 圖數據庫?
JanusGraph vs TigerGraph vs NebulaGraph
我們最早是採用了 JanusGraph 加上 Spark 去建設我們平台,但是通過一些測試,我們發現 JanusGraph 的查詢性能以及導入性能都比較一般,然後 GraphX 的話,它的計算性能其實也比較一般,特別是它需要的內存量特別大,因此我們後來又開始去調研了市場上很多的圖產品,並且對一些圖產品做了測試,包括國外的產品,像 TigerGraph 之類的等等,但是因為一些特殊原因,中國移動是在美國商務部的實體清單上,所以很多外國的產品我們是沒法去採購和使用的。
因此最後,我們是選擇國內的幾家廠商進行了一些測試和比較,最後選擇了以 NebulaGraph 作為圖數據庫,然後以 Plato 作為圖計算引擎這樣一個整體的架構。
中國移動是如何搭建圖平台的?
圖平台建設概況
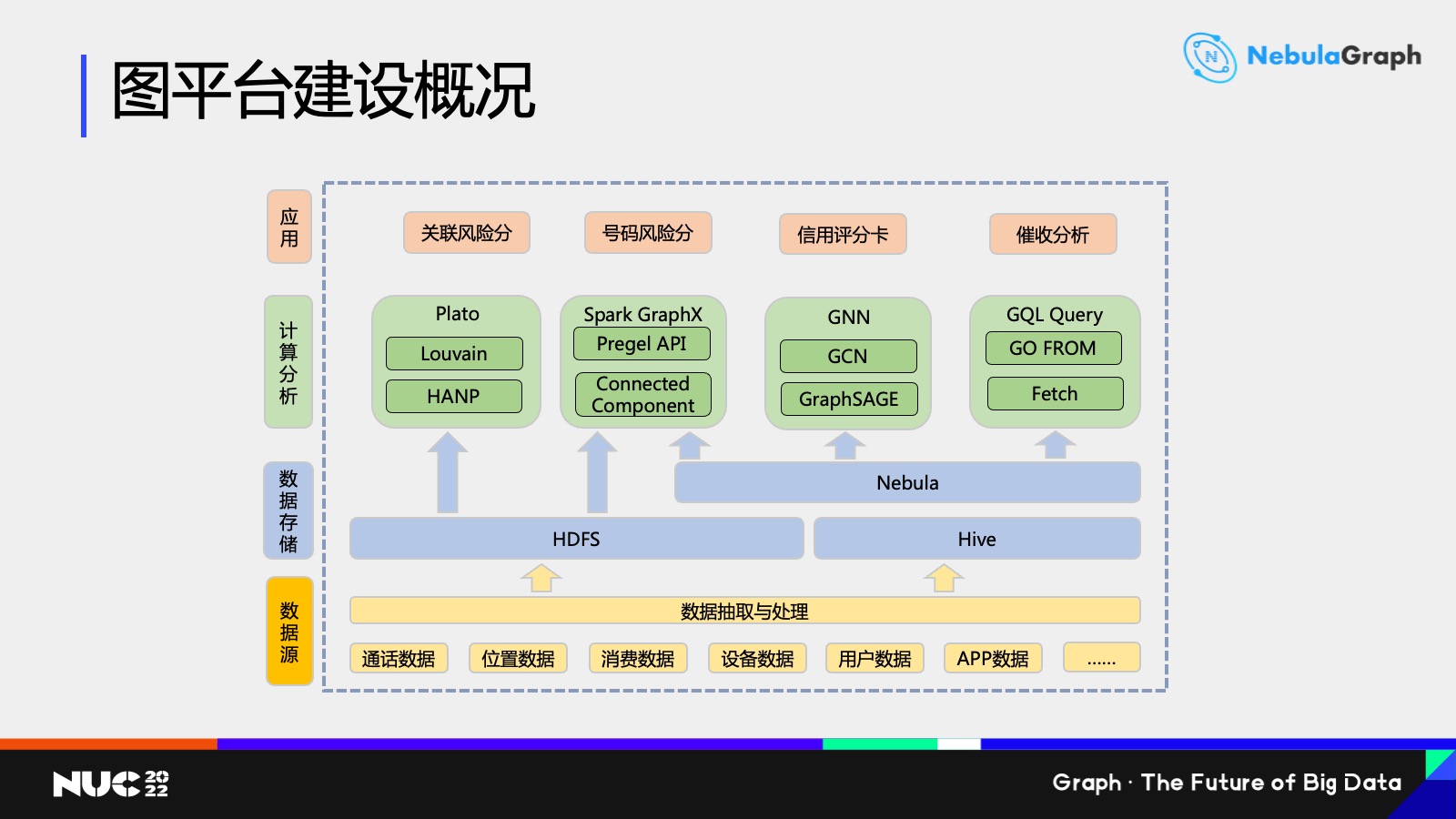
我們整體的架構大概是這樣的——
最底層是我們的數據源,中國移動建設有一個全國大數據中心,主要包括通話數據、位置數據、消費數據、設備數據、用户數據和 APP 數據等等,我們每月把這些數據抽取到 HDFS 裏面,然後把其中有用的數據抽取到 NebulaGraph 數據庫裏面,那麼這裏用的就是 Nebula 的一個導入工具,這是我們圖數據存儲這一層。
再上一層是計算分析層,這也是我們建模和業務分析人員主要使用的一些框架。首先第一個是 Plato,它是騰訊之前開源的一個圖計算引擎,但是據我所知騰訊現在已經不維護這一套引擎了,因此我們也是專門找一些工程師,然後去維護這裏面的一套框架,以及修復一些小 bug 之類的。
那麼它包含的算法其實很多的,這裏我主要是列舉了兩個社區發現算法:Louvain 算法和 HANP 算法。它裏面還包含一個 LPA 算法,因為 LPA 算法的話是 HANP 算法一個簡化版,所以這裏我沒有列出來。
然後裏面還有一個我們有可能後面會用到的關於隨機遊走類的算法,主要是基於隨機遊走得到一個節點序列,會為我們後面用於圖神經網絡訓練做一個前期數據預處理的工作。
第三個是 GNN,就是圖神經網絡。圖神經網絡是最近幾年興起的一個領域,我們現在主要是基於這些模型做一些簡單的產品,看看能不能取得比以往的方法更好的一些效果。最後就是基於 NebulaGraph 查詢語言,主要就是 GO 語句和 FETCH 語句做一些簡單查詢。
再上一層的話就是應用層。首先是關聯風險分,關聯風險分主要是基於配套的社區發現算法來做的。第二個號碼風險分和最後一個催收分析主要是基於 Nebula 的查詢語句來做的,主要就是查詢用户跟一度、二度聯繫人以及一些違約用户,或是催收專用號碼進行一些主動或被動的呼叫。第三個信用評分卡是基於圖神經網絡來做的,主要是用邏輯迴歸或者決策樹之類的模型,希望通過圖神經網絡做一些提高。
圖數據結構介紹

- 點數據
點數據主要是有四類,第一個是手機號,手機號也是我們最重要的點數據,主要是包括比如這手機號它是屬於哪個市的,是否發生過停機等等,還有一些消費信息。第二個是地理位置,主要基於基站。第三個身份證,作為唯一身份證識別,可能也會有年齡或學歷之類的標誌。最後是設備信息,一般手機會有一個設備值,有對應的型號、設備系統等。
- 邊數據
目前邊數據的話,一個是用户跟用户的通話數據,第二個是手機號和身份之間的對應關係,第三個是手機號和設備之間對應關係,第四個是手機號跟地理位置之間對應關係,那麼這些是我們在圖數據庫裏面保存的一些數據。
圖技術在中國移動有哪些應用?
應用1:號碼風險分
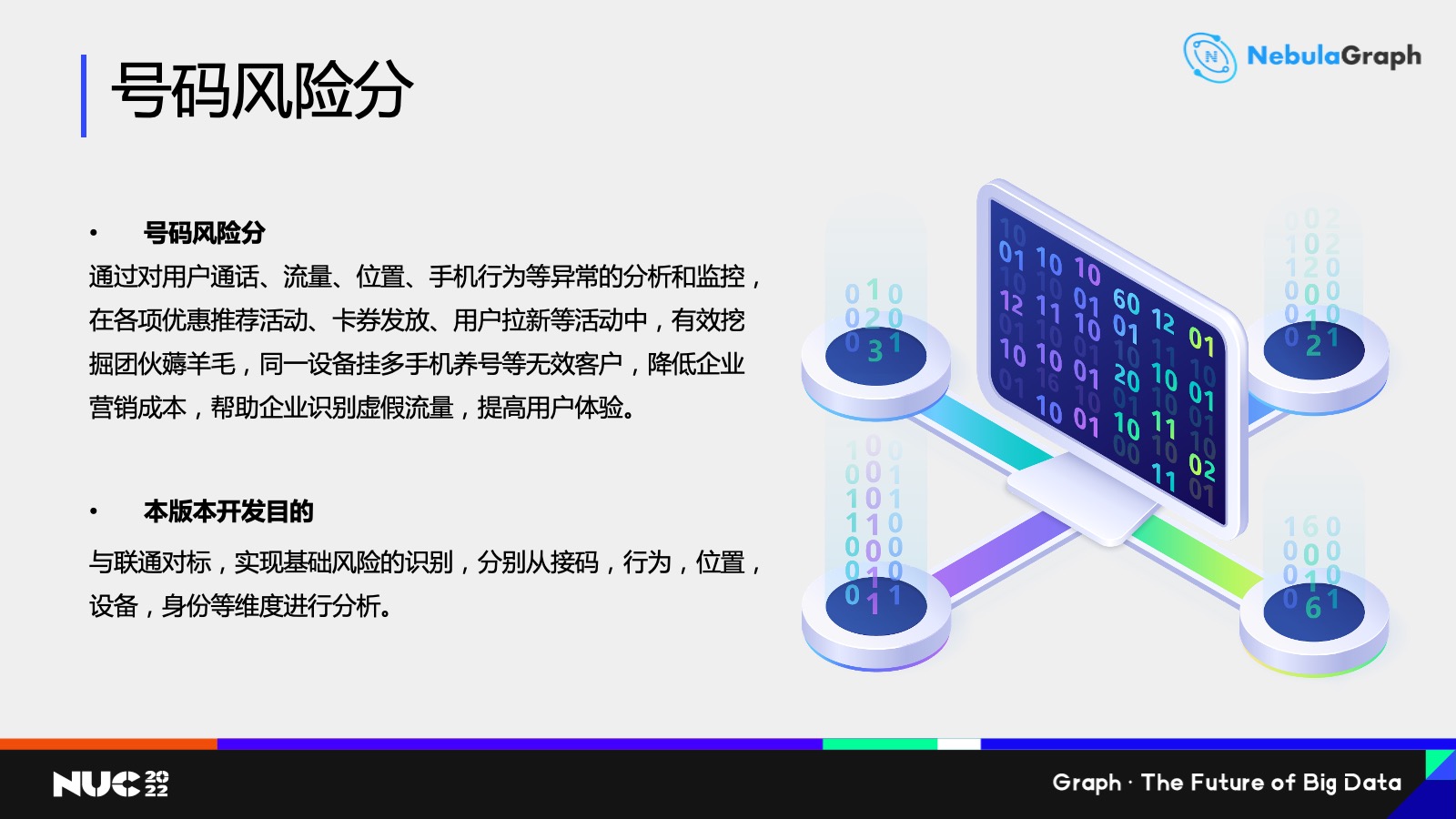
首先是號碼風險分模型,主要用在羊毛黨識別這個場景。我們會根據用户的通話流量位置以及手機行為信息去判斷一個號碼有沒有可能是個羊毛黨,主要通過四個模塊——
第一個是接碼模塊,我們會跟一些外面數據公司合作,判斷一個號碼有沒有可能是一個接碼號碼,如果是,我們會認為這個號碼是薅羊毛的可能性就很大。
第二個行為異常號碼,比如説這個手機號是否當月一次通話都沒有,然後是不是每月都基本只有固定的月租這樣的消費。這種號碼我們認為它可能是一個小號,或者是專門用來去薅羊毛的號碼。
第三個是位置異常,比如説這個手機是否一個月下來就是在一個位置從來沒有動過,可能只是放在家裏偶爾用一下,不會帶出去這種。對於這種號碼的話,我們認為它的風險也是相對比較大的。
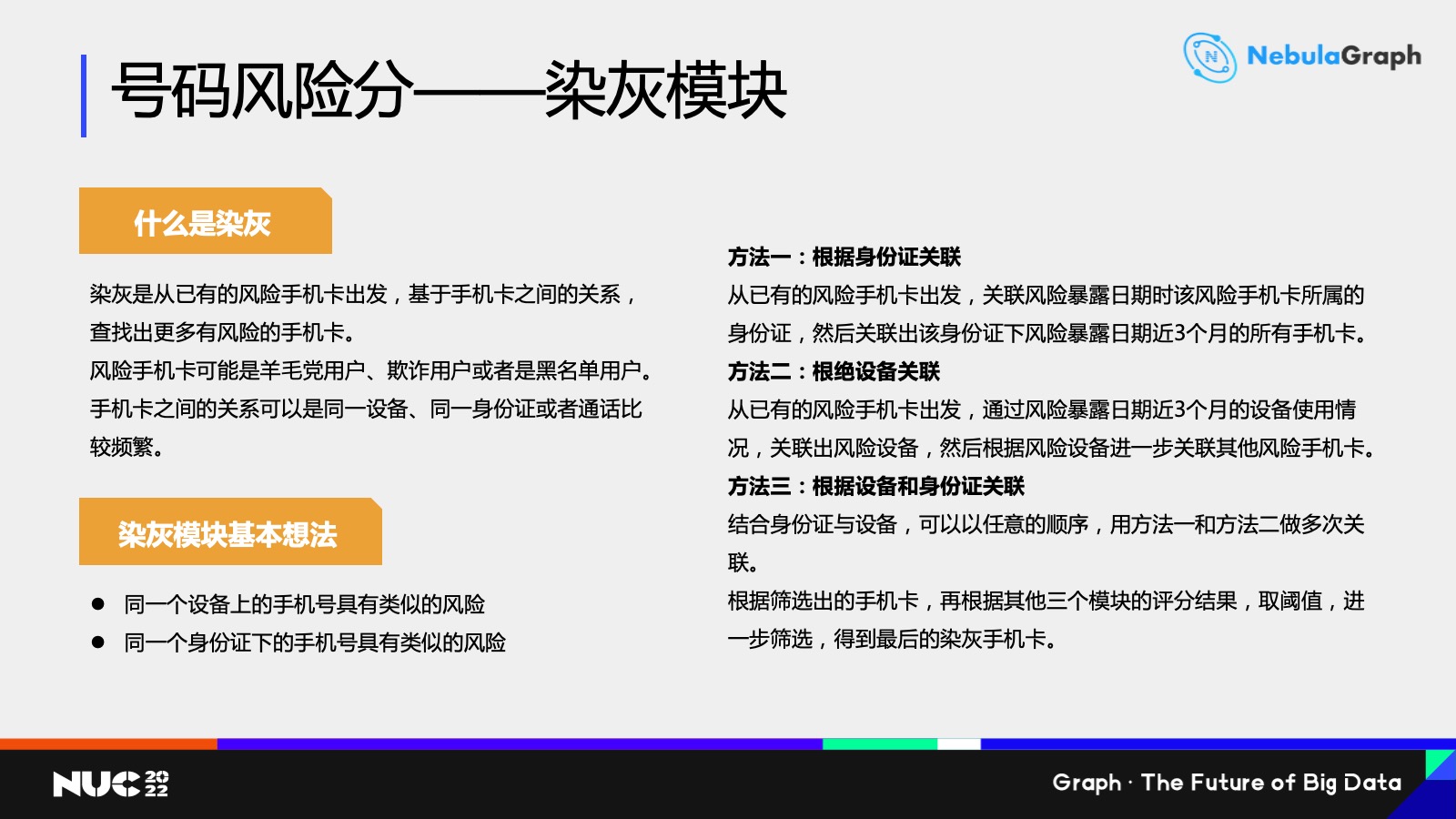
第四個是染灰模塊,圖技術主要就是用於這個模型。基於前三個模塊的結果,我們首先獲得了一批已經確定的羊毛黨用户,那麼我們可不可以發現他的一些共同特徵?比如説可能有幾個羊毛黨(號碼)是屬於同一個用户的,那麼我們是不是可以看看這個用户下面其他手機號是不是也可能是羊毛黨?
另外,如果發現有一堆手機號是之前在同一個設備上使用過,我們可能也會認為這個設備上對應的其他手機號也可能會是一些羊毛黨。專業的羊毛黨會採用卡池這種設備專門去薅羊毛,用圖技術就可以快速發現並識別。
應用2 :關聯風險分
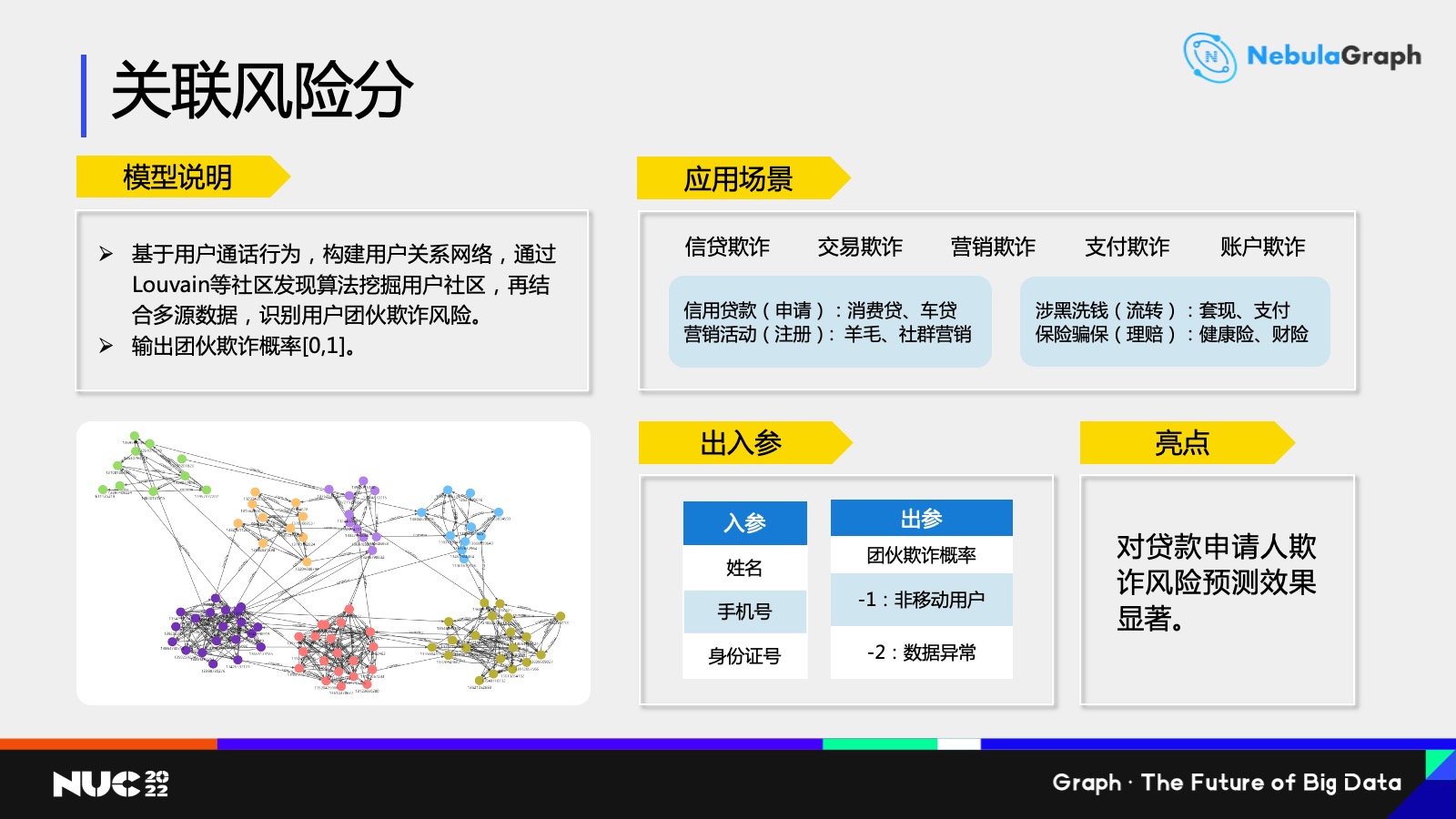
然後是關聯風險分,通俗來説就是「近朱者赤近墨者黑」。
在平時交際圈,如果你的違約可能性比較低,那麼周圍人可能違約性也會比較低。基於這樣一種想法,我們主要做法就是首先基於移動所有用户構建一個關係網絡,然後採用一些社區發現類的算法去挖掘這個社區中個人的評分以及個人之間的關係,通過對這個社區打分,去識別出這個社區是否是欺詐或低信用社區。
關聯風險分的主要應用場景就是欺詐領域,比如信貸欺詐、交易欺詐、營銷欺詐、支付欺詐以及賬户欺詐等等多個方面。
應用3:圖神經網絡(GNN)
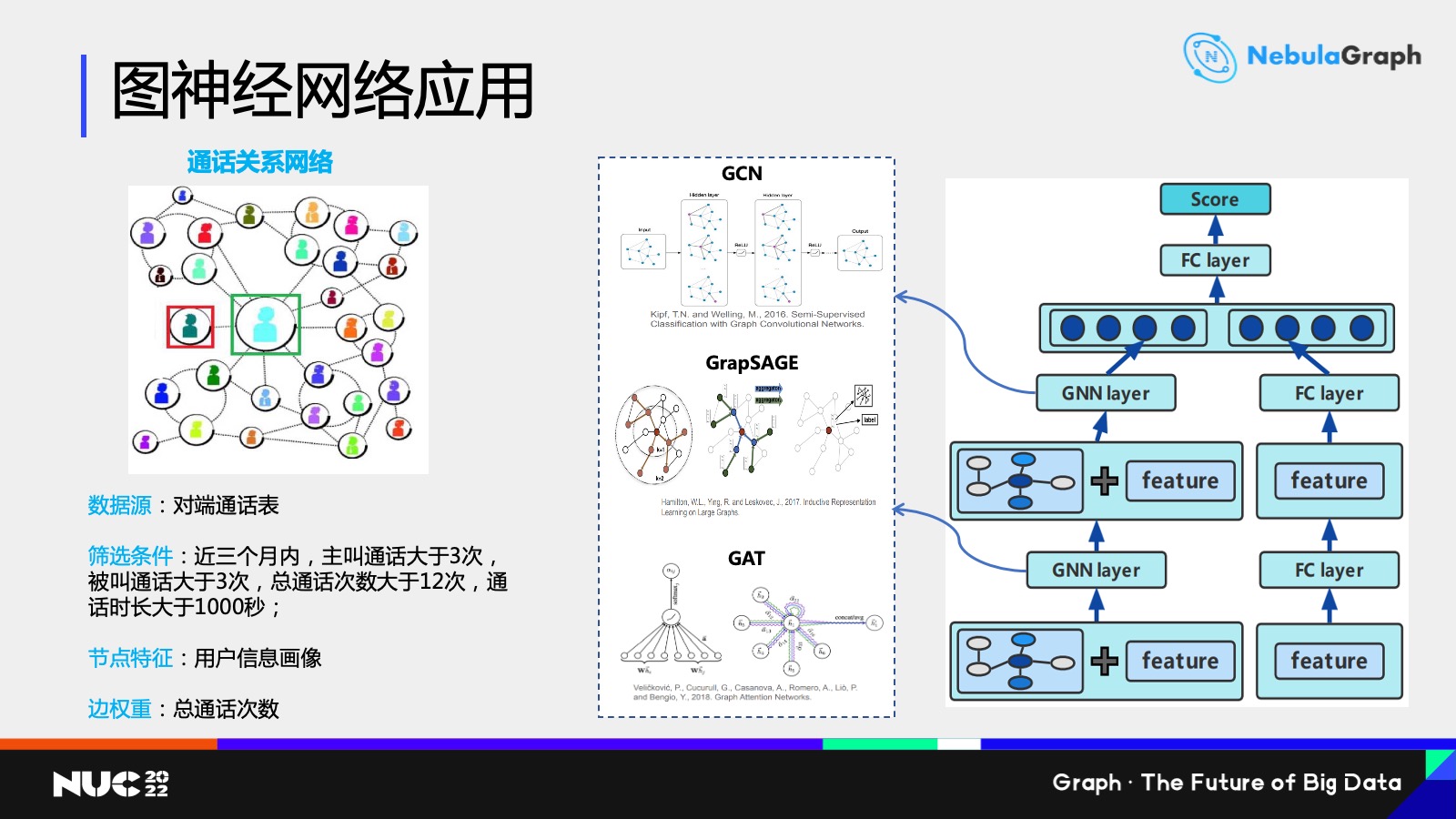
最後是關於圖神經網絡的一些應用,主要是用於金融風控信用評分卡的場景。過去我們用做信用評分卡大部分都是先提取用户特徵,再訓練一個邏輯迴歸模型或者是角色數字類的模型。
那麼現在,我們想通過圖神經網絡做一些模型,通過用户之間通話數據,比如近三個月主動通話、被動通話以總通話次數是否達到要求,去判斷要不要保留這樣一條邊。
我們大概提取 100 多個主要的特徵去錄模,這裏的模型相對來説比較簡單,目前是嘗試了一個雙塔的模型,左邊的是關於圖神經網絡聚合的這樣一個模型,右邊用户特徵本身的一個全連接網絡做了這樣 MLP 的模型。左邊的神經網絡聚合,是比較簡單也是最常用的——GCN、GraphSAGE 和 GAT 這三個模型。
另外我們現在採用的是一個同構圖的網絡建模,後面可能會考慮異構圖,比如説考慮用 HAN 這樣的一些異構圖的模型去建模,把用户的身份證和設備以及位置信息這些點都歸納進來,然後一起進行建模。
圖數據應用的未來展望

1.數據血緣
中國移動大數據中心會提供給大概 30 多家客户的 50 多個項目進行共同的建模,建模工作裏包含的數據維表會特別多,因為我們會給每個用户都匹配數據,然後幫他們生成特徵,最後會把結果表也保存在數據庫裏面,大概現在有 1000 多張數據表,平時基本靠人工管理,後面看看能不能通過數據血緣的方式去做一個歸納。
2.圖神經網絡
中國移動除了大數據中心,還有人工智能中心,那裏有很多的 GPU 資源進行人工神經網絡的訓練,但是目前模型訓練效率比較低下,所以後面看看怎麼用圖數據技術去解決這個問題。
NebulaGraph Desktop,Windows 和 macOS 用户安裝圖數據庫的綠色通道,10s 拉起搞定海量數據的圖服務。通道傳送門:http://c.nxw.so/blVC6
想看源碼的小夥伴可以前往 GitHub 閲讀、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流圖數據庫技術和應用技能,留下「你的名片」一起玩耍呢~
- 圖數據庫在中國移動金融風控的落地應用
- 記一次 rr 和硬件斷點解決內存踩踏問題
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 圖數據庫中的“分佈式”和“數據切分”(切圖)
- 揭祕可視化圖探索工具 NebulaGraph Explore 是如何實現圖計算的
- 連接微信羣、Slack 和 GitHub:社區開放溝通的基礎設施搭建
- 圖數據庫認證考試 NGCP 錯題解析 vol.02:這 10 道題竟無一人全部答對
- 如何判斷多賬號是同一個人?用圖技術搞定 ID Mapping
- 複雜場景下圖數據庫的 OLTP 與 OLAP 融合實踐
- 如何運維多集羣數據庫?58 同城 NebulaGraph Database 運維實踐
- 有了 ETL 數據神器 dbt,表數據秒變 NebulaGraph 中的圖數據
- 基於圖的下一代入侵檢測系統
- 從實測出發,掌握 NebulaGraph Exchange 性能最大化的祕密
- 讀 NebulaGraph源碼 | 查詢語句 LOOKUP 的一生
- 當雲原生網關遇上圖數據庫,NebulaGraph 的 APISIX 最佳實踐
- 從全球頂級數據庫大會 SIGMOD 看數據庫發展趨勢
- 「實操」結合圖數據庫、圖算法、機器學習、GNN 實現一個推薦系統
- 如何輕鬆做數據治理?開源技術棧告訴你答案
- 圖算法、圖數據庫在風控場景的應用