如何用Alluxio加速雲上深度學習訓練?

歡迎來到【微直播間】,2min縱覽大咖觀點
隨著企業資料量的不斷增加,為了提高深度學習訓練的準確性、加快速度並且降低成本,許多企業開始逐步在雲上實施分散式訓練的方案,本期內容將結合阿里、微軟等實際應用案例,分享如何通過Alluxio加速雲上深度學習。
內容主要圍繞兩個部分展開:
內容概要:
Alluxio及其POSIX API簡介
>> Alluxio是一個java開源專案,是雲上的關於資料分析以及深度學習訓練的一個數據抽象層。
>> 使用Alluxio,可以對資料應用以及資料來源進行無縫連線。
>> Alluxio的一個很重要功能是能夠對資料進行讀寫快取,另一方面也可以對元資料進行本地快取。
>> Alluxio可以把來自不同的遠端儲存系統,以及分散式檔案系統的資料都掛載到Alluxio統一的名稱空間之內。通過Alluxio POSIX API,把這些資料變成類似於本地檔案的形式,提供給各種訓練任務。
使用Alluxio加速雲上訓練
Level 1 讀取快取與加速:直接通過Alluxio來加速對底層儲存系統中的資料訪問。
Level 2 資料預處理和訓練:之所以有二級玩法,主要因為一級玩法有一些先決條件,要麼資料已經處理好就放在儲存系統中,要麼訓練指令碼已經包含了資料預處理的步驟,資料預處理與訓練同時進行,而我們發現在很多使用者場景中,並不具備這些條件。
Level 3 資料抽象層:把Alluxio作為整個資料的抽象層。
以上僅為大咖演講概覽,完整內容點選影片觀看:

附件:大咖分享文字版完整內容可見下文

Alluxio及其POSIX API簡介

Alluxio是一個java開源專案,是雲上的關於資料分析以及深度學習訓練的一個數據抽象層。在Alluxio之上可以對接不同的資料應用,包括Spark、Flink這種ETL工具,Presto這種query工具,以及TensorFlow、PyTorch等深度學習框架。在Alluxio下面也可以連線不同資料來源,比如阿里雲、騰訊雲、HDFS等。

使用Alluxio,可以對資料應用以及資料來源進行無縫連線,Alluxio負責處理與不同資料來源以及不同系統的對接。
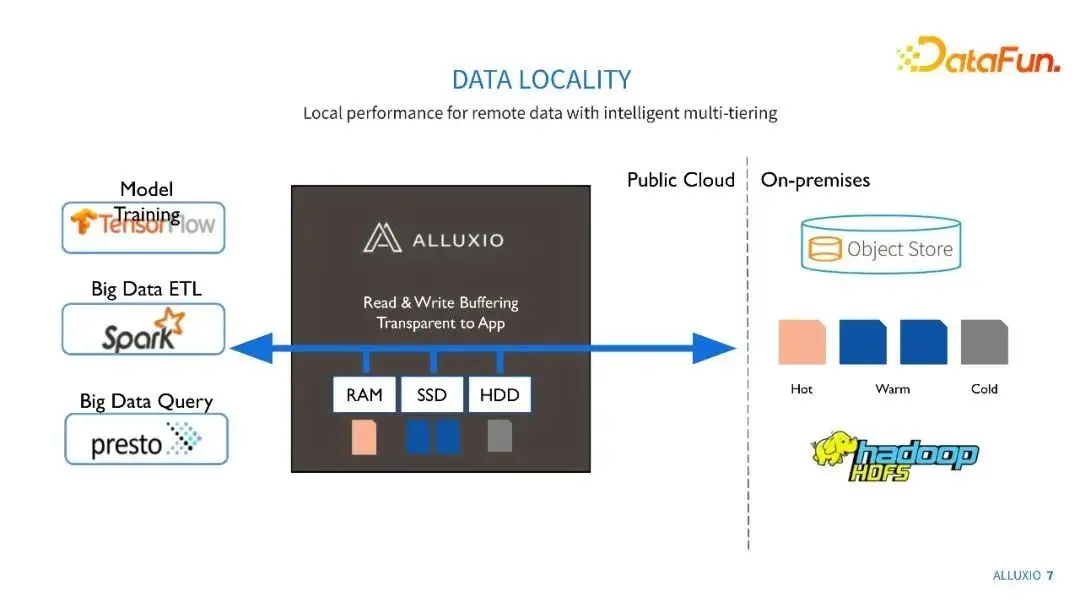
Alluxio的一個很重要功能是能夠對資料進行讀寫快取。大家可能很多資料是在雲端儲存上,或者是在遠端的HDFS和Ceph叢集上,如果每一次的資料應用都要去遠端不斷重複地拿同樣的資料,那麼整個拿資料的流程是非常耗時的,而且可能會導致我們整體訓練或資料處理效率不高。通過Alluxio,我們可以把一些熱資料在靠近資料應用的叢集進行快取,從而提升重複資料獲取的效能。
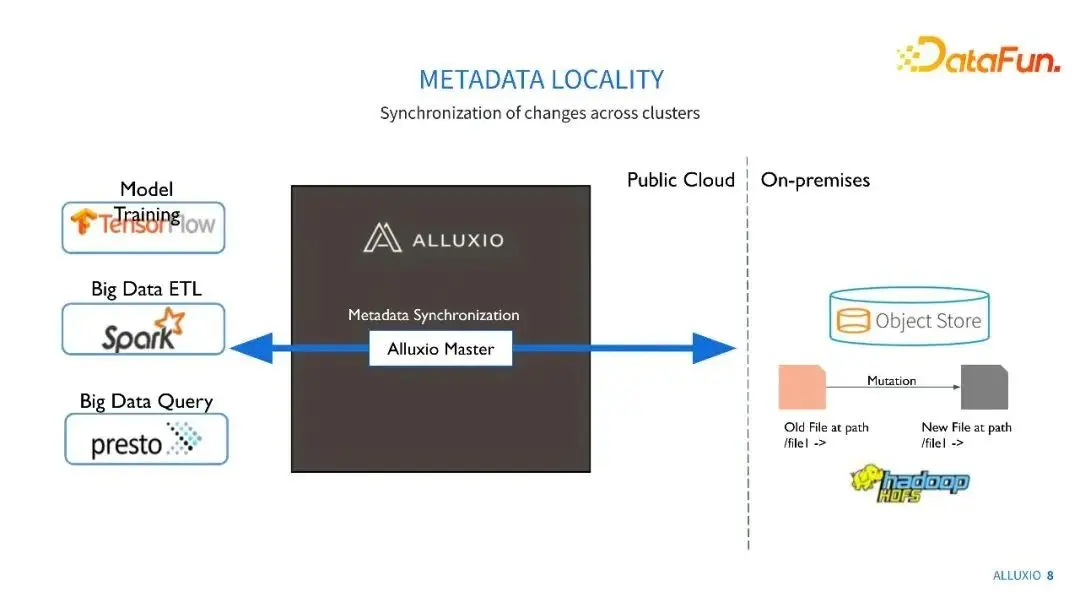
另一方面,我們也可以對元資料進行本地快取。每一次獲取元資料都要通過網路去獲取是比較慢的。如果通過Alluxio,可以直接從本地叢集獲取元資料,延時會大大縮短。同時,模型訓練的元資料需求是非常高壓的,我們在與螞蟻金服的實驗中,可以看到成千上萬QPS,如果全部壓力都壓到儲存系統中,儲存系統可能會不穩定,或進行一定的限流處理,導致一些讀取錯誤。通過Alluxio可以很好地分擔這部分元資料的壓力。
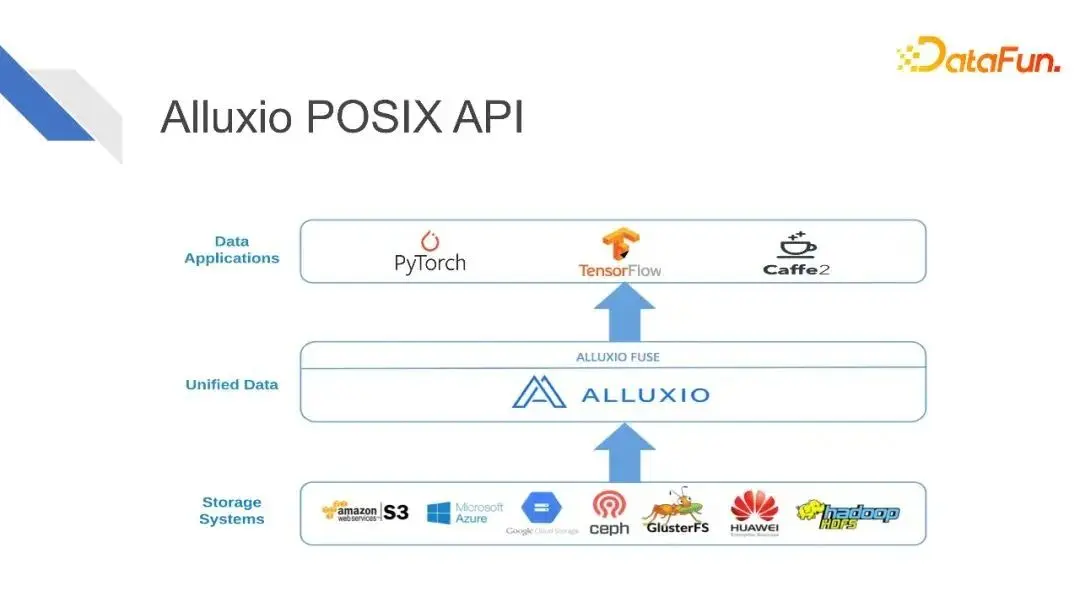
接下來重點講解一下Alluxio的POSIX API。
深度學習訓練框架PyTorch、TensorFlow、Caffe,它們的原生資料來源都是本地檔案系統。企業資料量日益擴大,導致我們需要去使用分散式資料來源。Alluxio可以把來自不同的遠端儲存系統,以及分散式檔案系統的資料都掛載到Alluxio統一的名稱空間之內。通過Alluxio POSIX API,把這些資料變成類似於本地檔案的形式,提供給各種訓練任務。
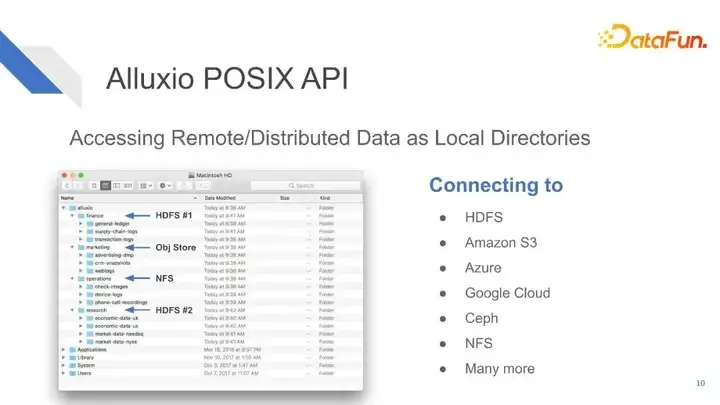
上圖直觀地展現了Alluxio POSIX API把遠端的分散式資料變成了本地資料夾的形式。
使用Alluxio加速雲上訓練
下面來具體講解如何使用Alluxio來加速雲上訓練。
Level 1 讀取快取與加速
一級玩法比較簡單,就是直接通過Alluxio來加速對底層儲存系統中的資料訪問。

如上圖示例,我們有一些資料儲存在我們的儲存系統中,它可能是已經經過資料預處理的資料,也可能是一些原始資料。我們的訓練在雲上的K8s叢集上,與資料來源之間存在一定的地理差異,獲取資料存在延時。我們的訓練需要重複去獲取同樣的資料來源,在這種情況下,使用Alluxio叢集,在靠近訓練的叢集內進行資料的快取可以極大地提升我們獲取資料的效能。
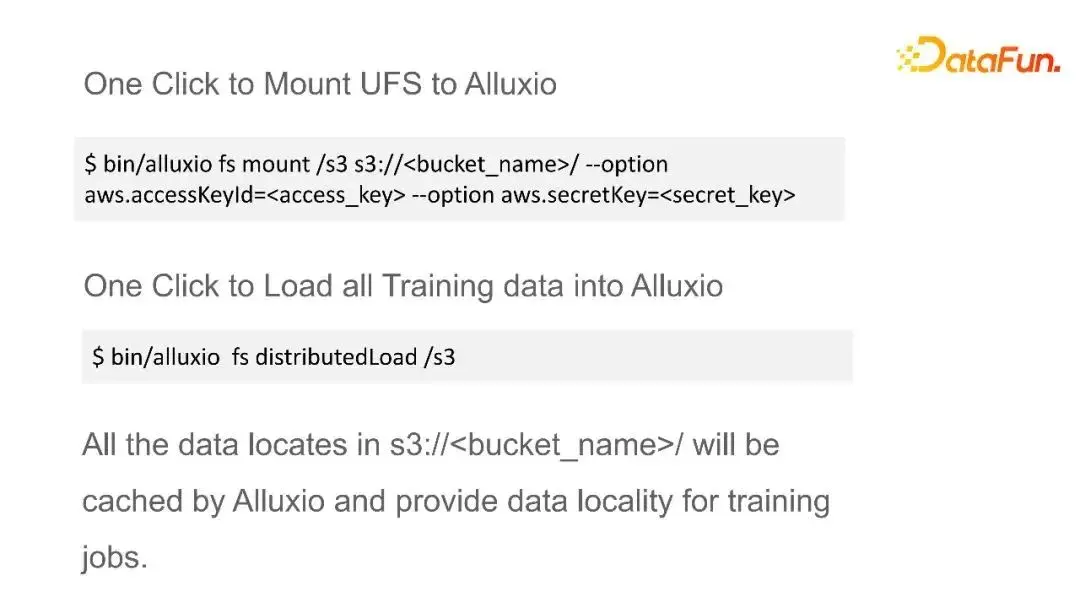
可以用簡單的命令來設定資料來源,以及一些安全引數,讓Alluxio可以去訪問這些資料來源。提供了資料來源地址以及安全引數之後,就可以把它掛載到Alluxio名稱空間內的一個資料夾目錄下面。掛載後,可以用一個命令來把所有的資料都一鍵地分散式載入到Alluxio當中,這樣所有資料都會進行分散式的快取,為我們的訓練任務提供本地資料效能。

上圖是阿里巴巴進行的一個實測,如果他們的訓練通過oss Fuse直接去訪問阿里雲端儲存,整個效能可能是幾百兆每秒,而通過Alluxio進行快取後,可以達到千兆每秒。

在Microsoft,他們的場景是:訓練資料全部存在Microsoft Azure裡面,有超過400個任務需要從Azure讀資料,並寫回到Azure中。這400個任務會涉及到上千個節點,而他們的訓練資料又是比較統一的。在使用Alluxio之前,他們的方案是把一份資料從Azure中不停地拷貝到上千臺機器上。整個過程耗時大,並且由於任務量太大了,常常會導致Azure對他們的資料請求進行限流處理,從而導致下載失敗,還要人工去恢復下載。通過使用Alluxio之後,Alluxio可以從Azure拿取一份資料,然後同樣的一份資料可以供給不同的訓練任務以及不同的機器,這樣load一次資料,就可以進行多次讀取。

在使用Alluxio之後,訓練任務無需等待資料完全下載到本地就可以開始訓練了。訓練結束之後,也可以通過Alluxio直接寫回到Azure。整個流程非常方便,並且gpu的使用率比較穩定。
Level 2 資料預處理和訓練
接下來看二級玩法。之所以會有二級玩法,主要是因為一級玩法有一些先決條件,要麼資料已經處理好就放在你的儲存系統中,要麼你的訓練指令碼已經包含了資料預處理的步驟,資料預處理與訓練同時進行,然而我們發現在很多使用者場景中,並不具備這些條件。
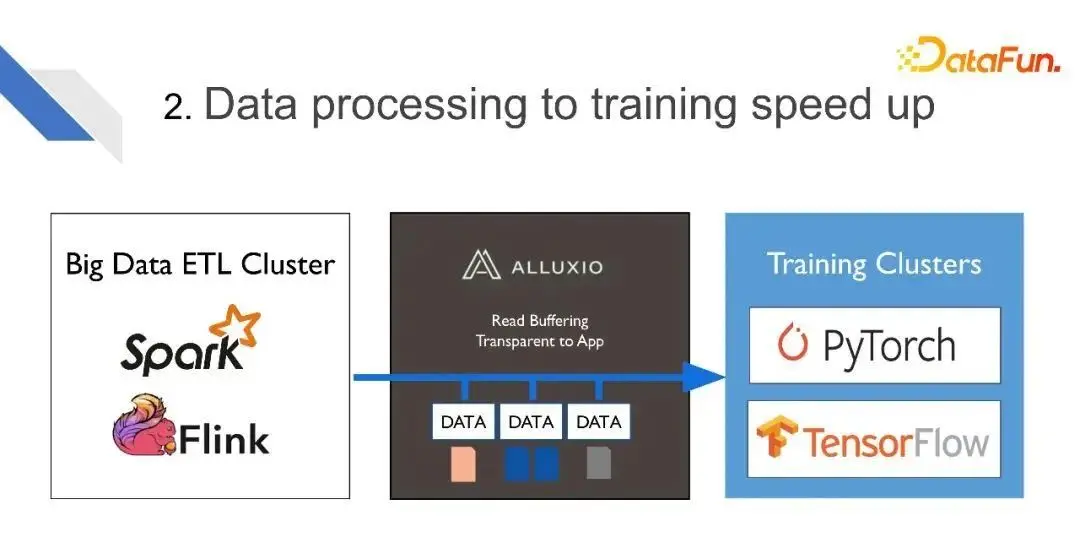
在很多使用者的場景裡,他們需要用其它方式來先對資料進行預處理,然後這部分預處理後的資料才能供給訓練。比如會用Spark、Flink等大資料ETL工具來進行資料預處理,處理好的資料寫到Alluxio,之後由Alluxio供給給訓練叢集。同時,對這部分資料可以進行備份、加速,來更快地提供給訓練叢集。

我們通過一個具體案例來了解這個流程。
在BOSS直聘,他們有兩個任務,首先是用Spark/Flink來對資料進行預處理,之後再對這部分預處理好的資料進行模型訓練。所有的中間結果和最後處理好的資料,都直接持久化到Ceph上,再由Ceph為模型訓練提供資料。把中間處理結果也放到Ceph中,會給Ceph增加很多的壓力。高壓的模型訓練給Ceph造成很大壓力。當ETL工作以及訓練多的時候,Ceph非常不穩定,整體效能受到影響。他們的解決辦法就是把Alluxio加到Spark/Flink和模型訓練之間。

Spark/Flink把中間結果寫到Alluxio之中,由Alluxio來提供給模型訓練。Alluxio在背後非同步地把這部分資料持久化到Ceph中,以保證這些預處理好的資料不會丟失。所以無論我們的資料來源是在本地還是遠端,即使資料持久化的速度比較慢,也不影響我們的訓練流程。並且Alluxio可以是一些單獨的叢集,如果ETL或training任務多的時候,可以起更多的Alluxio cluster來分擔這些任務,也可以對不同的Alluxio叢集進行資源分配、讀寫限額、許可權控制等。

這個流程可以提升儲存系統的穩定性,同時加速從資料預處理到訓練的整個流程,並且可以用更多的Alluxio叢集來應對更多的ETL或訓練需求。

我們發現大家會有不同的資料預處理方式。有些使用者用C++、python程式來進行資料清理、轉換等資料預處理。他們使用Alluxio把原始資料從底層儲存系統中載入到Alluxio的快取內,由Alluxio提供這部分資料預處理的框架,處理好的結果再寫回到Alluxio當中,模型訓練就可以用這部分預處理好的資料進行訓練。
Level 3 資料抽象層
Alluxio的三級玩法,就是把Alluxio作為整個資料的抽象層。

整個訓練叢集,不管它需要的資料來源來自何方,來自一些儲存系統,由大資料ETL處理好的資料,或者是C++、python處理好的資料,都可以通過Alluxio進行讀快取,供給給訓練。

另一方面,所有資料預處理的中間資料,以及訓練的中間資料,都可以通過Alluxio進行暫時的寫快取。對於資料預處理和訓練的結果,我們也可以通過Alluxio持久化到不同的儲存系統之中。
不管大家有什麼樣的資料應用,都可以通過Alluxio來對不同的資料來源中的資料進行讀寫操作。

比如陌陌,有很多Alluxio叢集,數千個節點,儲存超過100TB的資料,服務於搜尋以及訓練任務,他們還在不斷地開發新的應用場景。
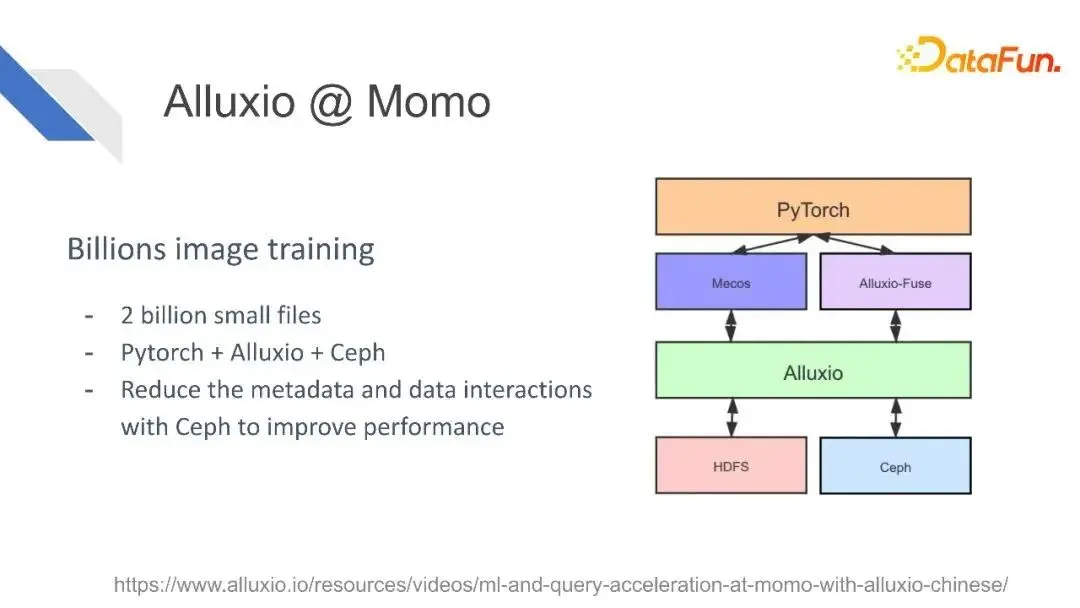
陌陌把Alluxio用作一個二十億的小檔案的訓練。
他們使用Alluxio來加速推薦系統模型的載入,以及ANN系統index的載入。

總結一下,Alluxio可能在以下這些場景對企業有所助益:
- 想要進行分散式訓練;
- 有大量的資料,可能無法在本地磁碟完整地存下來,或者有大量的小檔案/小圖片;
- 想要通過網路I/O直接去讀取資料,但網路I/O效能無法滿足GPU需求;
- 保證儲存系統的穩定性,避免超出限額的情況;
- 在多個不同的訓練任務中進行資料分享。
想要了解更多關於Alluxio的乾貨文章、熱門活動、專家分享,可點選進入【Alluxio智庫】:

- Alluxio跨叢集同步機制的設計與實現
- 如何借力Alluxio推動大資料產品效能提升與成本優化?
- 2023年五大趨勢預測 | 大資料分析、人工智慧和雲產業展望
- 如何用Alluxio加速雲上深度學習訓練?
- 【螞蟻】Alluxio在螞蟻集團大規模訓練中的應用
- 從博士論文到被各大廠應用,Alluxio 如何走過 7 年創業路
- Presto on Alluxio By Alluxio SDS 單節點搭建
- Alluxio Local Cache 監控指南 Alluxio Alluxio
- 幫助 Meta 解決 Presto 中的資料孤島問題
- B站基於Iceberg Alluxio助力湖倉一體專案落地實踐
- 【聯通】資料編排技術在聯通的應用
- 【聯通】資料編排技術在聯通的應用
- Alluxio 原始碼完整解析 | 你不知道的開源資料編排系統(下篇)
- Alluxio 原始碼完整解析 | 你不知道的開源資料編排系統 (上篇)
- Meta(Facebook): 基於Alluxio Shadow Cache優化Presto架構決策
- Apache頂級專案Ranger和Alluxio的最佳實踐(附教程)
- 金山雲團隊分享 | 5000字讀懂Presto如何與Alluxio搭配
- 2min速覽:從設計、實現和優化角度淺談Alluxio元資料同步
- 華能 Alluxio | 數字化浪潮下跨地域資料聯邦訪問與分析
- 什麼是一致性雜湊?可以應用在哪些場景?