詳解神經網路基礎部件BN層
摘要:在深度神經網路訓練的過程中,由於網路中引數變化而引起網路中間層資料分佈發生變化的這一過程被稱為內部協變數偏移(Internal Covariate Shift),而 BN 可以解決這個問題。
本文分享自華為雲社群《神經網路基礎部件-BN層詳解》,作者:嵌入式視覺 。
一,數學基礎
1.1,概率密度函式
隨機變數(random variable)是可以隨機地取不同值的變數。隨機變數可以是離散的或者連續的。簡單起見,本文用大寫字母 XX 表示隨機變數,小寫字母 xx 表示隨機變數能夠取到的值。例如,x1x1 和 x2x2 都是隨機變數 XX 可能的取值。隨機變數必須伴隨著一個概率分佈來指定每個狀態的可能性。
概率分佈(probability distribution)用來描述隨機變數或一簇隨機變數在每一個可能取到的狀態的可能性大小。我們描述概率分佈的方式取決於隨機變數是離散的還是連續的。
當我們研究的物件是連續型隨機變數時,我們用概率密度函式(probability density function, PDF)而不是概率質量函式來描述它的概率分佈。
更多內容請閱讀《花書》第三章-概率與資訊理論,或者我的文章-深度學習數學基礎-概率與資訊理論。
1.2,正態分佈
當我們不知道資料真實分佈時使用正態分佈的原因之一是,正態分佈擁有最大的熵,我們通過這個假設來施加儘可能少的結構。
實數上最常用的分佈就是正態分佈(normal distribution),也稱為高斯分佈 (Gaussian distribution)。
如果隨機變數 XX ,服從位置引數為 μμ、尺度引數為 σσ 的概率分佈,且其概率密度函式為:
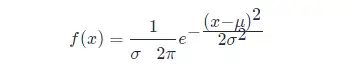
則這個隨機變數就稱為正態隨機變數,正態隨機變數服從的概率分佈就稱為正態分佈,記作:
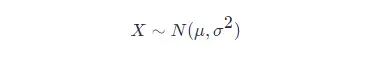
如果位置引數 μ=0μ=0,尺度引數 σ=1σ=1 時,則稱為標準正態分佈,記作:
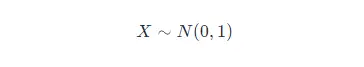
此時,概率密度函式公式簡化為:
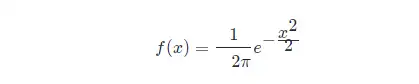
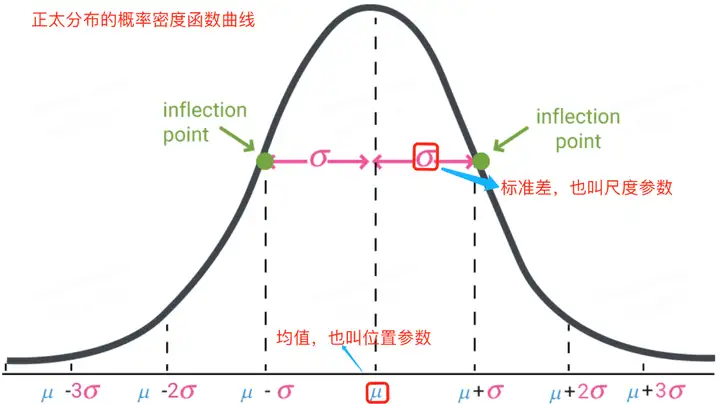
正太分佈的數學期望值或期望值 μμ 等於位置引數,決定了分佈的位置;其方差 σ2σ2 的開平方或標準差 σσ 等於尺度引數,決定了分佈的幅度。正太分佈的概率密度函式曲線呈鐘形,常稱之為鐘形曲線,如下圖所示:
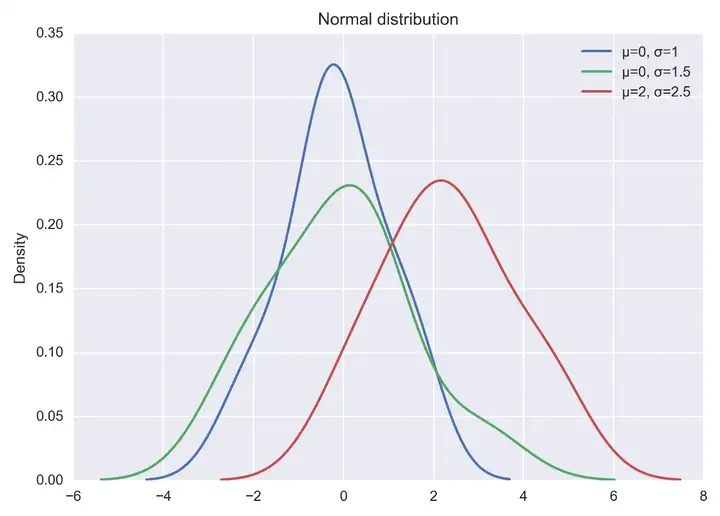
視覺化正態分佈,可直接通過 np.random.normal 函式生成指定均值和標準差的正態分佈隨機數,然後基於 matplotlib + seaborn 庫 kdeplot函式繪製概率密度曲線。示例程式碼如下所示:
import seaborn as sns
x1 = np.random.normal(0, 1, 100)
x2 = np.random.normal(0, 1.5, 100)
x3 = np.random.normal(2, 1.5, 100)
plt.figure(dpi = 200)
sns.kdeplot(x1, label="μ=0, σ=1")
sns.kdeplot(x2, label="μ=0, σ=1.5")
sns.kdeplot(x3, label="μ=2, σ=2.5")
#顯示圖例
plt.legend()
#新增標題
plt.title("Normal distribution")
plt.show()以上程式碼直接執行後,輸出結果如下圖:
當然也可以自己實現正太分佈的概率密度函式,程式碼和程式輸出結果如下:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(dpi = 200)
plt.style.use('seaborn-darkgrid') # 主題設定
def nd_func(x, sigma, mu):
"""自定義實現正太分佈的概率密度函式
"""
a = - (x-mu)**2 / (2*sigma*sigma)
f = np.exp(a) / (sigma * np.sqrt(2*np.pi))
return f
if __name__ == '__main__':
x = np.linspace(-5, 5)
f = nd_fun(x, 1, 0)
p1, = plt.plot(x, f)
f = nd_fun(x, 1.5, 0)
p2, = plt.plot(x, f)
f = nd_fun(x, 1.5, 2)
p3, = plt.plot(x, f)
plt.legend([p1 ,p2, p3], ["μ=0,σ=1", "μ=0,σ=1.5", "μ=2,σ=1.5"])
plt.show()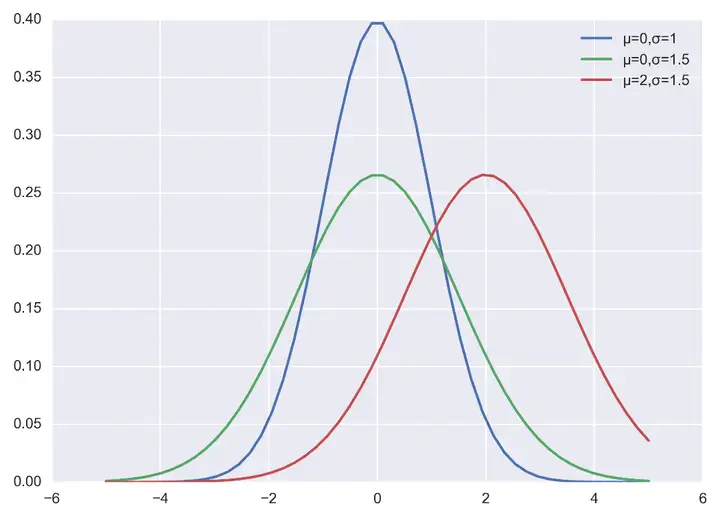
二,背景
訓練深度神經網路的複雜性在於,因為前面的層的引數會發生變化導致每層輸入的分佈在訓練過程中會發生變化。這又導致模型需要需要較低的學習率和非常謹慎的引數初始化策略,從而減慢了訓練速度,並且具有飽和非線性的模型訓練起來也非常困難。
網路層輸入資料分佈發生變化的這種現象稱為內部協變數轉移,BN 就是來解決這個問題。
2.1,如何理解 Internal Covariate Shift
在深度神經網路訓練的過程中,由於網路中引數變化而引起網路中間層資料分佈發生變化的這一過程被稱在論文中稱之為內部協變數偏移(Internal Covariate Shift)。
那麼,為什麼網路中間層資料分佈會發生變化呢?
在深度神經網路中,我們可以將每一層視為對輸入的訊號做了一次變換(暫時不考慮啟用,因為啟用函式不會改變輸入資料的分佈):
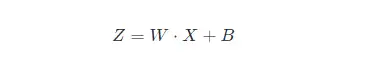
其中 WW 和 BB 是模型學習的引數,這個公式涵蓋了全連線層和卷積層。
隨著 SGD 演算法更新引數,和網路的每一層的輸入資料經過公式5的運算後,其 ZZ 的分佈一直在變化,因此網路的每一層都需要不斷適應新的分佈,這一過程就被叫做 Internal Covariate Shift。
而深度神經網路訓練的複雜性在於每層的輸入受到前面所有層的引數的影響—因此當網路變得更深時,網路引數的微小變化就會被放大。
2.2,Internal Covariate Shift 帶來的問題
- 網路層需要不斷適應新的分佈,導致網路學習速度的降低。
- 網路層輸入資料容易陷入到非線性的飽和狀態並減慢網路收斂,這個影響隨著網路深度的增加而放大。
隨著網路層的加深,後面網路輸入 xx 越來越大,而如果我們又採用 Sigmoid 型啟用函式,那麼每層的輸入很容易移動到非線性飽和區域,此時梯度會變得很小甚至接近於 00,導致引數的更新速度就會減慢,進而又會放慢網路的收斂速度。
飽和問題和由此產生的梯度消失通常通過使用修正線性單元啟用(ReLU(x)=max(x,0)ReLU(x)=max(x,0)),更好的引數初始化方法和小的學習率來解決。然而,如果我們能保證非線性輸入的分佈在網路訓練時保持更穩定,那麼優化器將不太可能陷入飽和狀態,進而訓練也將加速。
2.3,減少 Internal Covariate Shift 的一些嘗試
- 白化(Whitening): 即輸入線性變換為具有零均值和單位方差,並去相關。
白化過程由於改變了網路每一層的分佈,因而改變了網路層中本身資料的表達能力。底層網路學習到的引數資訊會被白化操作丟失掉,而且白化計算成本也高。 - 標準化(normalization)
Normalization 操作雖然緩解了 ICS 問題,讓每一層網路的輸入資料分佈都變得穩定,但卻導致了資料表達能力的缺失。
三,批量歸一化(BN)
3.1,BN 的前向計算
論文中給出的 Batch Normalizing Transform 演算法計算過程如下圖所示。其中輸入是一個考慮一個大小為 mm 的小批量資料 BB。

論文中的公式不太清晰,下面我給出更為清晰的 Batch Normalizing Transform 演算法計算過程。
設 mm 表示 batch_size 的大小,nn 表示 features 數量,即樣本特徵值數量。在訓練過程中,針對每一個 batch 資料,BN 過程進行的操作是,將這組資料 normalization,之後對其進行線性變換,具體演算法步驟如下:
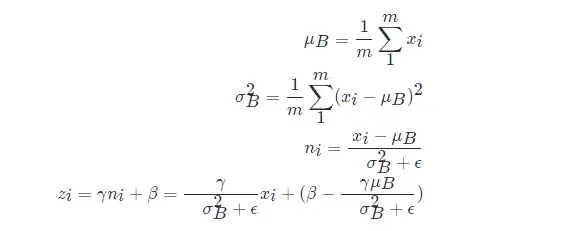
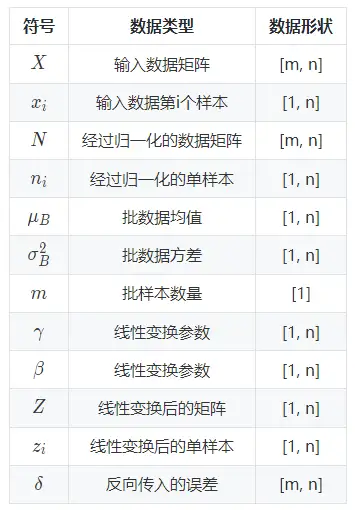
以上公式乘法都為元素乘,即 element wise 的乘法。其中,引數 γ,βγ,β 是訓練出來的, ϵϵ 是為零防止 σB2σB2 為 00 ,加的一個很小的數值,通常為1e-5。公式各個符號解釋如下:
其中:
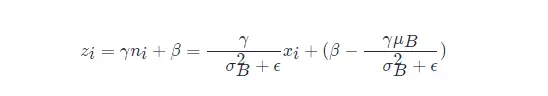
可以看出 BN 本質上是做線性變換。
3.2,BN 層如何工作
在論文中,訓練一個帶 BN 層的網路, BN 演算法步驟如下圖所示:

在訓練期間,我們一次向網路提供一小批資料。在前向傳播過程中,網路的每一層都處理該小批量資料。 BN 網路層按如下方式執行前向傳播計算:
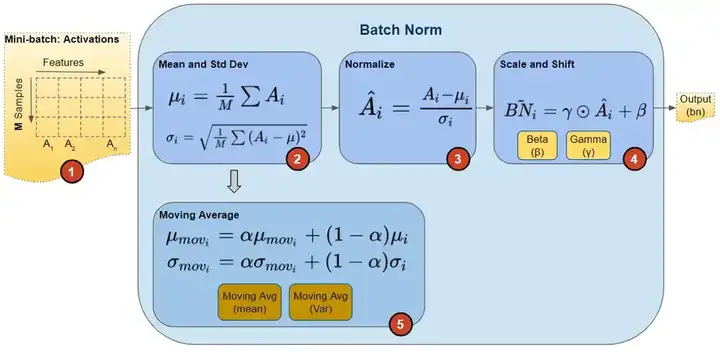
圖片來源這裡。
注意,圖中計算均值與方差的無偏估計方法是吳恩達在 Coursera 上的 Deep Learning 課程上提出的方法:對 train 階段每個 batch 計算的 mean/variance 採用指數加權平均來得到 test 階段 mean/variance 的估計。
在訓練期間,它只是計算此 EMA,但不對其執行任何操作。在訓練結束時,它只是將該值儲存為層狀態的一部分,以供在推理階段使用。
如下圖可以展示BN 層的前向傳播計算過程資料的 shape ,紅色框出來的單個樣本都指代單個矩陣,即運算都是在單個矩陣運算中計算的。
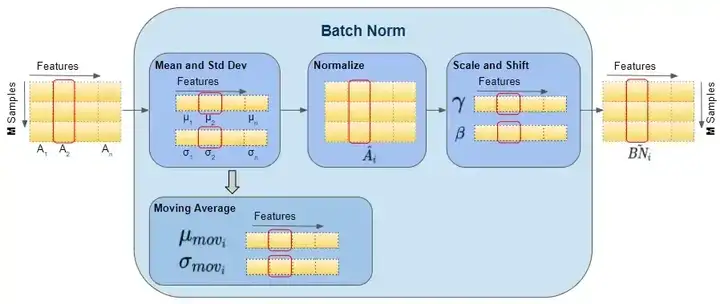
圖片來源 這裡。
BN 的反向傳播過程中,會更新 BN 層中的所有 ββ 和 γγ 引數。
3.3,訓練和推理式的 BN 層
批量歸一化(batch normalization)的“批量”兩個字,表示在模型的迭代訓練過程中,BN 首先計算小批量( mini-batch,如 32)的均值和方差。但是,在推理過程中,我們只有一個樣本,而不是一個小批量。在這種情況下,我們該如何獲得均值和方差呢?
第一種方法是,使用的均值和方差資料是在訓練過程中樣本值的平均,即:
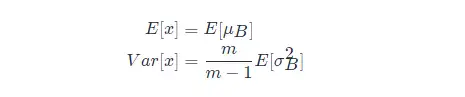
這種做法會把所有訓練批次的 μμ 和 σσ 都儲存下來,然後在最後訓練完成時(或做測試時)做下平均。
第二種方法是使用類似動量的方法,訓練時,加權平均每個批次的值,權值 αα 可以為0.9:
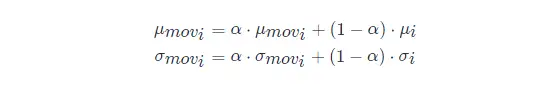
推理或測試時,直接使用模型檔案中儲存的 μmoviμmovi 和 σmoviσmovi 的值即可。
3.4,實驗
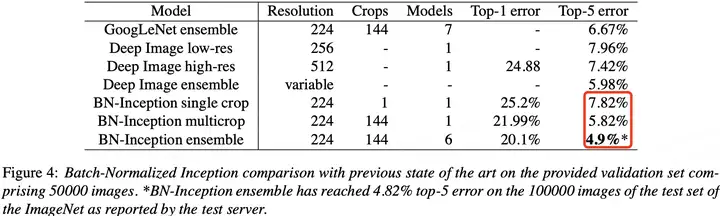
BN 在 ImageNet 分類資料集上實驗結果是 SOTA 的,如下表所示:
3.5,BN 層的優點
- BN 使得網路中每層輸入資料的分佈相對穩定,加速模型訓練和收斂速度。
- 批標準化可以提高學習率。在傳統的深度網路中,學習率過高可能會導致梯度爆炸或梯度消失,以及陷入差的區域性最小值。批標準化有助於解決這些問題。通過標準化整個網路的啟用值,它可以防止層引數的微小變化隨著資料在深度網路中的傳播而放大。例如,這使 sigmoid 非線性更容易保持在它們的非飽和狀態,這對訓練深度 sigmoid 網路至關重要,但在傳統上很難實現。
- BN 允許網路使用飽和非線性啟用函式(如 sigmoid,tanh 等)進行訓練,其能緩解梯度消失問題。
- 不需要 dropout 和 LRN(Local Response Normalization)層來實現正則化。批標準化提供了類似丟棄的正則化收益,因為通過實驗可以觀察到訓練樣本的啟用受到同一小批量樣例隨機選擇的影響。
- 減少對引數初始化方法的依賴。
參考資料
- 維基百科-正態分佈
- Batch Norm Explained Visually — How it works, and why neural networks need it
- 15.5 批量歸一化的原理
- Batch Normalization原理與實戰
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析