從 ClickHouse 到 Apache Doris,騰訊音樂內容庫資料平臺架構演進實踐
導讀:騰訊音樂內容庫資料平臺旨在為應用層提供庫存檔點、分群畫像、指標分析、標籤圈選等內容分析服務,高效為業務賦能。目前,內容庫資料平臺的資料架構已經從 1.0 演進到了 4.0 ,經歷了分析引擎從 ClickHouse 到 Apache Doris 的替換、經歷了資料架構語義層的初步引入到深度應用,有效提高了資料時效性、降低了運維成本、解決了資料管理割裂等問題,收益顯著。本文將為大家分享騰訊音樂內容庫資料平臺的資料架構演進歷程與實踐思考,希望所有讀者從文章中有所啟發。
作者:騰訊音樂內容庫資料平臺 張俊、代凱
騰訊音樂娛樂集團(簡稱“騰訊音樂娛樂”)是中國線上音樂娛樂服務開拓者,提供線上音樂和以音樂為核心的社交娛樂兩大服務。騰訊音樂娛樂在中國有著廣泛的使用者基礎,擁有目前國內市場知名的四大移動音樂產品:QQ音樂、酷狗音樂、酷我音樂和全民K歌,總月活使用者數超過8億。
業務需求
騰訊音樂娛樂擁有海量的內容曲庫,包括錄製音樂、現場音樂、音訊和視訊等多種形式。通過技術和資料的賦能,騰訊音樂娛樂持續創新產品,為使用者帶來更好的產品體驗,提高使用者參與度,也為音樂人和合作夥伴在音樂的製作、發行和銷售方面提供更大的支援。
在業務運營過程中我們需要對包括歌曲、詞曲、專輯、藝人在內的內容物件進行全方位分析,高效為業務賦能,內容庫資料平臺旨在整合各資料來源的資料,整合形成內容資料資產(以指標和標籤體系為載體),為應用層提供庫存檔點、分群畫像、指標分析、標籤圈選等內容分析服務。

圖片
資料架構演進
TDW 是騰訊最大的離線資料處理平臺,公司內大多數業務的產品報表、運營分析、資料探勘等的儲存和計算都是在TDW中進行,內容庫資料平臺的資料加工鏈路同樣是在騰訊資料倉庫 TDW 上構建的。截止目前,內容庫資料平臺的資料架構已經從 1.0 演進到了 4.0 ,經歷了分析引擎從 ClickHouse 到 Apache Doris 的替換、經歷了資料架構語義層的初步引入到深度應用,有效提高了資料時效性、降低了運維成本、解決了資料管理割裂等問題,收益顯著。接下來將為大家分享騰訊音樂內容庫資料平臺的資料架構演進歷程與實踐思考。
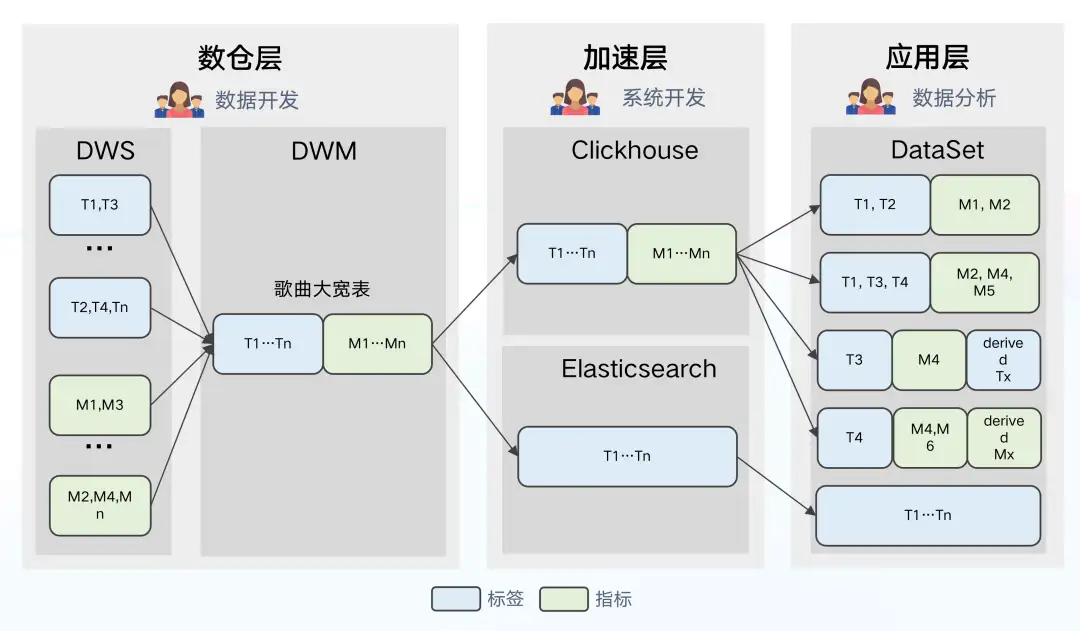
資料架構 1.0
圖片
如圖所示為資料架構 1.0 架構圖,分為數倉層、加速層、應用層三部分,資料架構 1.0 是一個相對主流的架構,簡單介紹一下各層的作用及工作原理:
- 數倉層:通過 ODS-DWD-DWS 三層將資料整合為不同主題的標籤和指標體系, DWM 集市層圍繞內容物件構建大寬表,從不同主題域 DWS 表中抽取欄位。
- 加速層:在數倉中構建的大寬表匯入到加速層中,Clickhouse 作為分析引擎,Elasticsearch 作為搜尋/圈選引擎。
- 應用層:根據場景建立 DataSet,作為邏輯檢視從大寬表選取所需的標籤與指標,同時可以二次定義衍生的標籤與指標。
存在的問題:
- 數倉層:不支援部分列更新,當上遊任一來源表產生延遲,均會造成大寬表延遲,進而導致資料時效性下降。
- 加速層:不同的標籤跟指標特性不同、更新頻率也各不相同。由於 ClickHouse 目前更擅長處理寬表場景,無區別將所有資料匯入大寬表生成天的分割槽將造成儲存資源的浪費,維護成本也將隨之升高。
- 應用層:ClickHouse 採用的是計算和儲存節點強耦合的架構,架構複雜,元件依賴嚴重,牽一髮而動全身,容易出現叢集穩定性問題,對於我們來說,同時維護 ClickHouse 和 Elasticsearch 兩套引擎的連線與查詢,成本和難度都比較高。
除此之外,ClickHouse 由國外開源,交流具有一定的語言學習成本,遇到問題無法準確反饋、無法快速獲得解決,與社群溝通上的阻塞也是促進我們進行架構升級的因素之一。
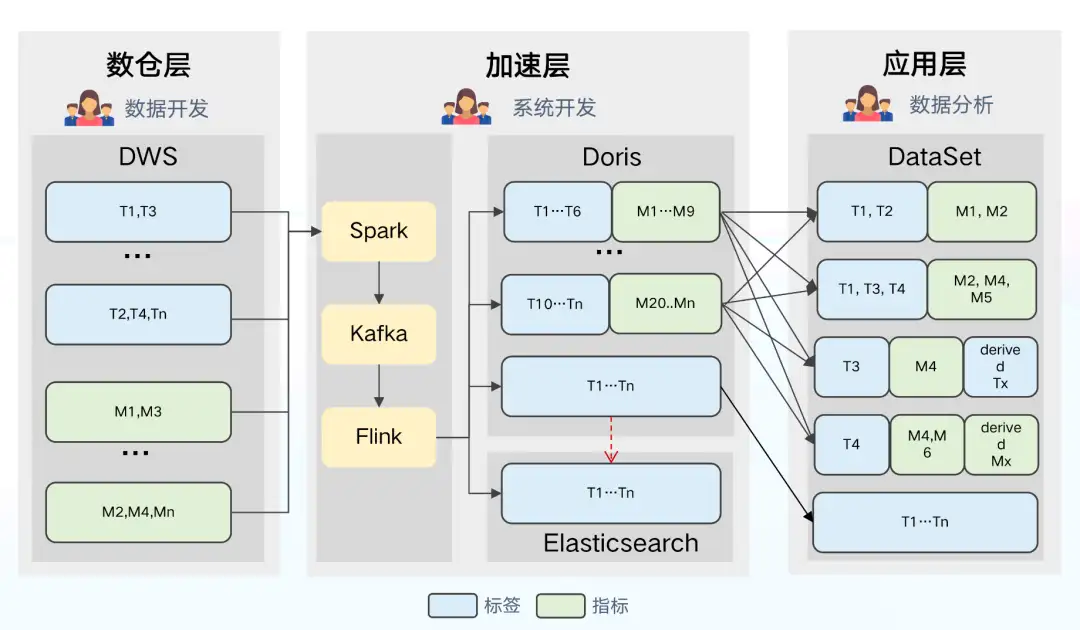
資料架構 2.0
圖片
基於架構 1.0 存在的問題和 ClickHouse 的侷限性,我們嘗試對架構進行優化升級,將分析引擎 ClickHouse 切換為 Doris,Doris 具有以下的優勢:
Apache Doris 的優勢:
- Doris 架構極簡易用,部署只需兩個程序,不依賴其他系統,運維簡單;相容 MySQL 協議,並且使用標準 SQL。
- 支援豐富的資料模型,可滿足多種資料更新方式,支援部分列更新。
- 支援對 Hive、Iceberg、Hudi 等資料湖和 MySQL、Elasticsearch 等資料庫的聯邦查詢分析。
- 匯入方式多樣,支援從 HDFS/S3 等遠端儲存批量匯入,也支援讀取 MySQL Binlog 以及訂閱訊息佇列 Kafka 中的資料,還可以通過 Flink Connector 實時/批次同步資料來源(MySQL,Oracle,PostgreSQL 等)到 Doris。
- 社群目前 Apache Doris 社群活躍、技術交流更多,SelectDB 針對社群有專職的技術支援團隊,在使用過程中遇到問題均能快速得到響應解決。
同時我們也利用 Doris 的特性,解決了架構 1.0 中較為突出的問題。
- 數倉層:Apache Doris 的 Aggregate 資料模型可支援部分列實時更新,因此我們去掉了 DWM 集市層的構建,直接增量到 Doris / ES 中構建寬表,解決了架構 1.0 中上游資料更新延遲導致整個寬表延遲的問題,進而提升了資料的時效性。資料(指標、標籤等)通過 Spark 統一離線載入到 Kafka 中,使用 Flink 將資料增量更新到 Doris 和 ES 中(利用 Flink 實現進一步的聚合,減輕了 Doris 和 ES 的更新壓力)。
- 加速層:該層主要將大寬表拆為小寬表,根據更新頻率配置不同的分割槽策略,減小資料冗餘帶來的儲存壓力,提高查詢吞吐量。Doris 具備多表查詢和聯邦查詢效能特性,可以利用多表關聯特性實現組合查詢。
- 應用層:DataSet 統一指向 Doris,Doris 支援外表查詢,利用該特性可對 ES 引擎直接查詢。
架構 2.0 存在的問題:
- DataSet 靈活度較高,資料分析師可對指標和標籤自由組合和定義,但是不同的分析師對同一資料的定義不盡相同、定義口徑不一致,導致指標和標籤缺乏統一管理,這使得資料管理和使用的難度都變高。
- Dataset 與物理位置繫結,應用層無法進行透明優化,如果 Doris 引擎出現負載較高的情況,無法通過降低使用者查詢避免叢集負載過高報錯的問題。
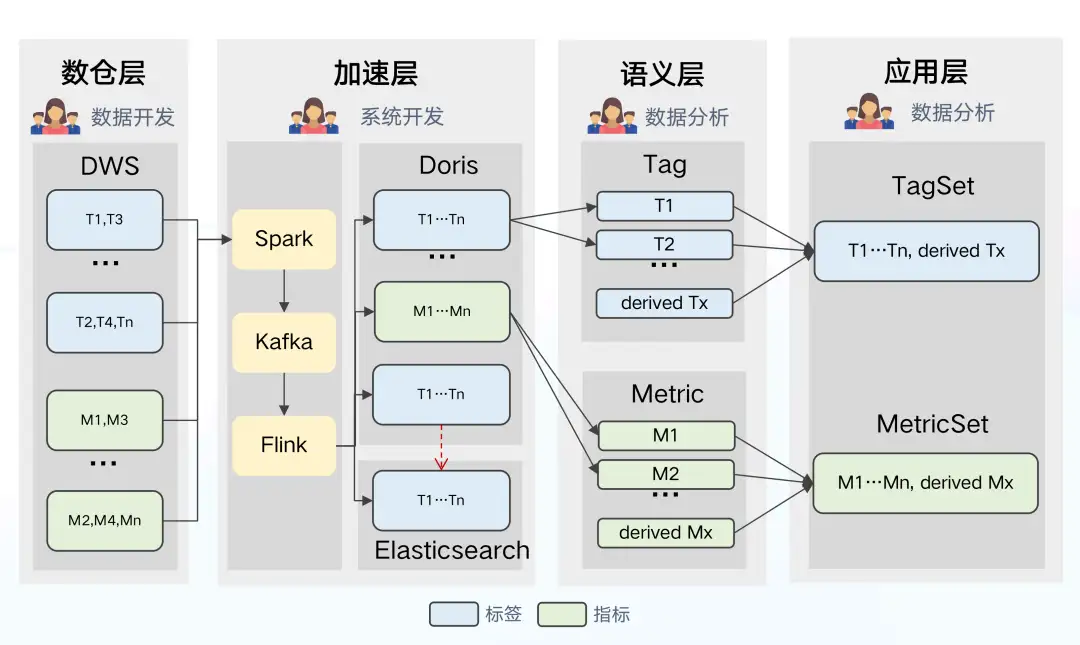
資料架構 3.0
針對指標和標籤定義口徑不統一,資料使用和管理難度較高的問題,我們繼續對架構進行升級。資料架構 3.0 主要的變化是引入了專門的語義層,語義層的主要作用是將技術語言轉換為業務部門更容易理解的概念,目的是將標籤 (tag)與指標(metric)變為“一等公民”,作為資料定義與管理的基本物件。
圖片
引入語義層的優勢有:
- 對於技術來說,應用層不再需要建立 DataSet,從語義層可直接獲取特定內容物件的標籤集 (tagset)和指標集(metricset) 來發起查詢。
- 對於資料分析師來說,可統一在語義層定義和建立衍生的指標和標籤,解決了定義口徑不一致、管理和使用難度較高的問題。
- 對於業務來說,無需耗費過長時間考慮什麼場景應選擇哪個資料集使用,語義層對標籤和指標透明統一的定義提升了工作效率、降低了使用成本。
存在的問題:
從架構圖可知,標籤和指標等資料均處於下游位置,雖然標籤與指標在語義層被顯式定義,但仍然無法影響上游鏈路,數倉層有自己的語義邏輯,加速層有自己的匯入配置,這樣就造成了資料管理機制的割裂。
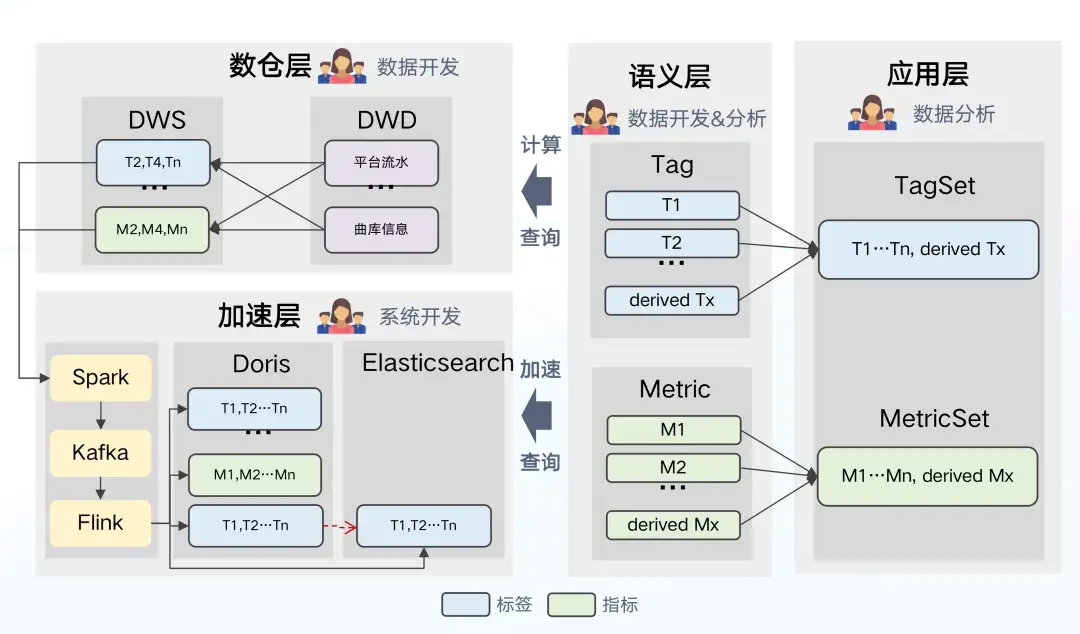
資料架構 4.0
在資料架構 3.0 的基礎上,我們對語義層進行更深層次的應用,在資料架構 4.0 中,我們將語義層變為架構的中樞節點,目標是對所有的指標和標籤統一定義,從計算-加速-查詢實現中心化、標準化管理,解決資料管理機制割裂的問題。
圖片
語義層作為架構中樞節點所帶來的變化:
- 數倉層:語義層接收 SQL 觸發計算或查詢任務。數倉從 DWD 到 DWS 的計算邏輯將在語義層中進行定義,且以單個指標和標籤的形式進行定義,之後由語義層來發送命令,生成 SQL 命令給數倉層執行計算。
- 加速層:從語義層接收配置、觸發匯入任務,比如加速哪些指標與標籤均由語義層指導。
- 應用層:向語義層發起邏輯查詢,由語義層選擇引擎,生成物理 SQL。
架構優勢:
- 可以形成統一檢視,對於核心指標和標籤的定義進行統一檢視及管理。
- 應用層與物理引擎完成解耦,可進一步對更加靈活易用的架構進行探索:如何對相關指標和標籤進行加速,如何在時效性和叢集的穩定性之間平衡等。
存在的問題:
因為當前架構是對單個標籤和指標進行了定義,因此如何在查詢計算時自動生成一個準確有效的 SQL 語句是非常有難度的。如果你有相關的經驗,期待有機會可以一起探索交流。
優化經驗
從上文已知,為更好地實現業務需求,資料架構演進到 4.0 版本,其中 Apache Doris 作為分析加速場景的解決方案在整個系統中發揮著重要的作用。接下來將從場景需求、資料匯入、查詢優化以及成本優化四個方面出發,分享基於 Doris 的讀寫優化經驗,希望給讀者帶來一些參考。
場景需求
圖片
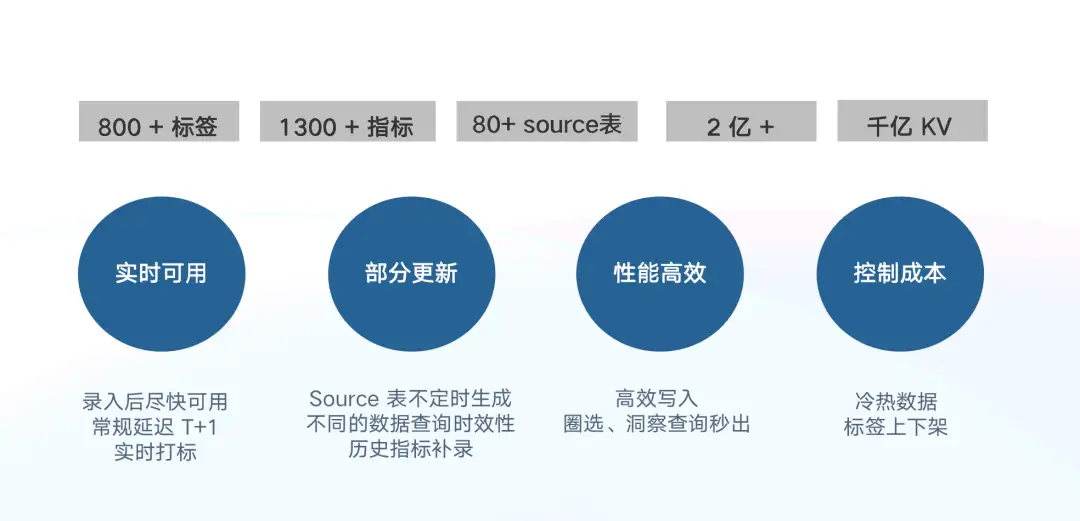
目前我們有 800+ 標籤, 1300+ 指標,對應 TDW 中有 80 + Source 表,單個標籤、指標的最大基數達到了 2 億+。我們希望將這些資料從 TDW 加速到 Doris 中完成標籤畫像和指標的分析。從業務的角度,需要滿足以下要求:
- 實時可用:標籤/指標匯入以後,需實現資料儘快可用。不僅要支援常規離線匯入 T+1 ,同時也要支援實時打標場景。
- 部分更新:因每個 Source 表由各自 ETL 任務產出對應的資料,其產出時間不一致,並且每個表只涉及部分指標或標籤,不同資料查詢對時效性要求也不同,因此架構需要支援部分列更新。
- 效能高效:具備高效的寫入能力,且在圈選、洞察、報表等場景可以實現秒級響應。
- 控制成本:在滿足業務需求的前提下,最大程度地降低成本;支援冷熱資料精細化管理,支援標籤靈活上下架。
資料匯入方案
圖片
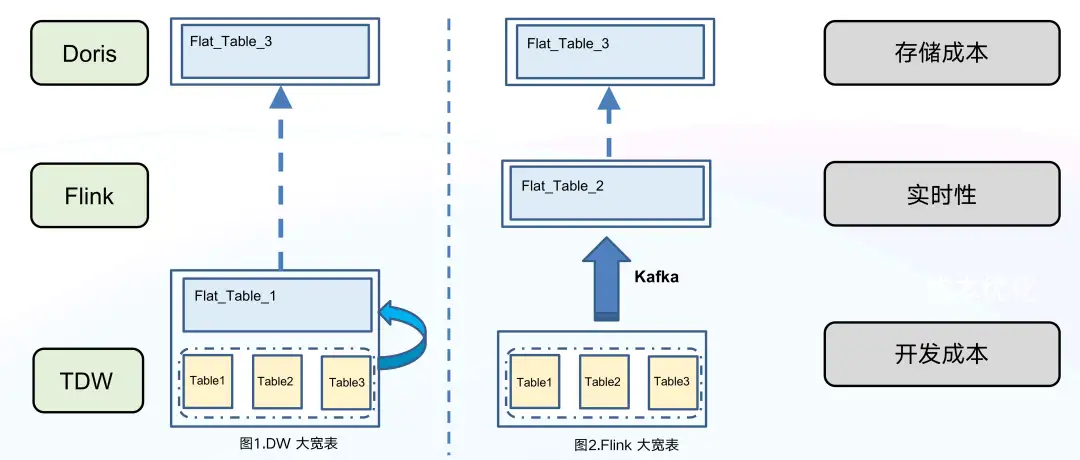
為了減輕 Doris 寫入壓力,我們考慮在資料寫入 Doris 之前,儘量將資料生成寬表,再寫入到 Doris 中。針對寬表的生成,我們有兩個實現思路:第一個是在 TDW 數倉中生成寬表;第二個是 Flink 中生成寬表。我們對這兩個實現思路進行了實踐對比,最終決定選擇第二個實現思路,原因如下:
在 TDW 中生成寬表,雖然鏈路簡單,但是弊端也比較明顯。
- 儲存成本較高, TDW 除了要維護離散的 80 +個 Source 表外,還需維護 1 個大寬表、2 份冗餘的資料。
- 實時性比較差,由於每個 Source 表產出的時間不一樣,往往會因為某些延遲比較大的 Source 表導致整個資料鏈路延遲增大。
- 開發成本較高,該方案只能作為離線方式,若想實現實時方式則需要投入開發資源進行額外的開發。
而在 Flink 中生成寬表,鏈路簡單、成本低也容易實現,主要流程是:首先用 Spark 將相關 Source 表最新資料離線匯入到 Kafka 中, 接著使用 Flink 來消費 Kafka,並通過主鍵 ID 構建出一張大寬表,最後將大寬表匯入到 Doris 中。如下圖所示,來自數倉 N 個表中 ID=1 的 5 條資料,經過 Flink 處理以後,只有一條 ID=1 的資料寫入 Doris 中,大大減少 Doris 寫入壓力。

圖片
通過以上匯入優化方案,極大地降低了儲存成本, TDW 無需維護兩份冗餘的資料,Kafka 也只需儲存最新待匯入的資料。同時該方案整體實時性更好且可控,並且大寬表聚合在 Flink 中執行,可靈活加入各種 ETL 邏輯,離線和實時可對多個開發邏輯進行復用,靈活度較高。
資料模型選擇
目前我們生產環境所使用的版本為 Apache Doris 1.1.3,我們對其所支援的 Unique 主鍵模型、Aggregate 聚合模型和 Duplicate 明細模型進行了對比 ,相較於 Unique 模型和 Duplicate 模型,Aggregate 聚合模型滿足我們部分列更新的場景需求:
Aggregate 聚合模型可以支援多種預聚合模式,可以通過REPLACE_IF_NOT_NULL的方式實現部分列更新。資料寫入過程中,Doris 會將多次寫入的資料進行聚合,終端使用者查詢時,返回一份聚合後的完整且正確的資料。
另外兩種資料模型適用的場景,這裡也進行簡單的介紹:
- Unique 模型適用於需要保證 Key 唯一性場景,同一個主鍵 ID 多次匯入之後,會以 append 的方式進行行級資料更新,僅保留最後一次匯入的資料。在與社群進行溝通後,確定後續版本 Unique 模型也將支援部分列更新。
- Duplicate 模型區別於 Aggregate 和 Unique 模型,資料完全按照匯入的明細資料進行儲存,不會有任何預聚合或去重操作,即使兩行資料完全相同也都會保留,因此 Duplicate 模型適用於既沒有聚合需求,又沒有主鍵唯一性約束的原始資料儲存。
確定資料模型之後,我們在建表時如何對列進行命名呢?可以直接使用指標或者是標籤的名稱嗎?
在使用場景中通常會有以下幾個需求:
- 為了更好地表達資料的意義,業務方會有少量修改標籤、指標名稱的需求。
- 隨著業務需求的變動,標籤經常存在上架、下架的情況。
- 實時新增的標籤和指標,使用者希望資料儘快可用。
Doris 1.1.3 是不支援對列名進行修改的,如果直接使用指標/標籤名稱作為列名,則無法滿足上述標籤或指標更名的需求。而對於上下架標籤的需求,如果直接以 drop/add column 的方式實現,則會涉及資料檔案的更改,該操作耗時耗力,甚至會影響線上查詢的效能。
那麼,有沒有更輕量級的方式來滿足需求呢?接下來將為大家分享相關解決方案及收益:****
- 為了實現少量標籤、指標名稱修改,我們用 MySQL 表儲存相應的元資料,包括名稱、全域性唯一的 ID 和上下架狀態等資訊,比如標籤歌曲名稱
song_name的 ID 為 4,在 Doris 中儲存命名為 a4,使用者使用更具有業務含義song_name進行查詢。在查詢 Doris 前,我們會在查詢層將 SQL 改寫成具體的列名 a4。這樣名稱的修改只是修改其元資料,底層 Doris 的表結構可以保持不變。 - 為了實現標籤靈活上下架,我們通過統計標籤的使用情況來分析標籤的價值,將低價值的標籤進入下架流程。下架指的是對元資訊進行狀態標註,在下架標籤重新上架之前,不會繼續匯入其資料,元資訊中資料可用時間也不會發生變化。
- 對於實時新增標籤/指標,我們基於名稱 ID 的對映在 Doris 表中預先建立適量 ID 列,當標籤/指標完成元資訊錄入後,直接將預留的 ID 分配給新錄入的標籤/指標,避免在查詢高峰期因新增標籤/指標所引起的 Schema Change 開銷對叢集產生的影響。經測試,使用者在元資訊錄入後 10 分鐘內就可以使用相應的資料。
值得關注的是,在社群近期釋出的 1.2.0 版本中,增加了 Light Schema Change 功能, 對於增減列的操作不需要修改資料檔案,只需要修改 FE 中的元資料,從而可以實現毫秒級的 Schame Change 操作。同時開啟 Light Schema Change 功能的資料表也可以支援列名的修改,這與我們的需求十分匹配,後續我們也會及時升級到最新版本。
寫入優化
接著我們在資料寫入方面也進行了調整優化,這裡幾點小經驗與大家分享:
- Flink 預聚合:通過主鍵 ID 預聚合,減少寫入壓力。(前文已說明,此處不再贅述)
- 寫入 Batch 大小自適應變更:為了不佔用過多 Flink 資源,我們實現了從同一個 Kafka Topic 中消費資料寫入到不同 Doris 表中的功能,並且可以根據資料的大小自動調整寫入的批次,儘量做到攢批低頻寫入。
- Doris 寫入調優:針對- 235 報錯進行相關引數的調優。比如設定合理的分割槽和分桶(Tablet 建議1-10G),同時結合場景對 Compaction 引數調優:
max_XXXX_compaction_thread
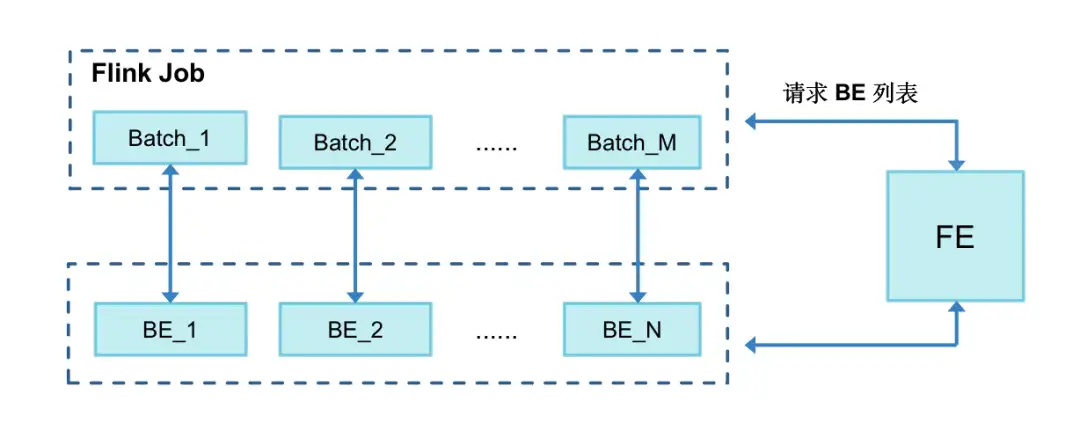
max_cumulative_compaction_num_singleton_deltas- 優化 BE 提交邏輯:定期快取 BE 列表,按批次隨機提交到 BE 節點,細化負載均衡粒度。
優化背景:在寫入時發現某一個 BE負載會遠遠高於其他的 BE,甚至出現 OOM。結合原始碼發現:作業啟動後會獲取一次 BE 地址列表,從中隨機選出一個 BE 作為 Coordinator 協調者,該節點主要負責接收資料、並分發到其他的 BE 節點,除非作業異常報錯,否則該節點不會發生切換。
對於少量 Flink 作業大資料場景會導致選中的 BE 節點負載較高,因此我們嘗試對 BE 提交邏輯進行優化,設定每 1 小時快取一次 BE 列表,每寫入一個批次都隨機從 BE 快取列表中獲取一個進行提交,這樣負載均衡的粒度就從 job 級別細化到每次提交的批次,使得 BE 間負載更加的均衡,這部分實現我們已經貢獻到社群,歡迎大家一起使用並反饋。
- http://github.com/apache/doris-spark-connector/pull/59
- http://github.com/apache/doris-spark-connector/pull/60
- http://github.com/apache/doris-spark-connector/pull/61
圖片
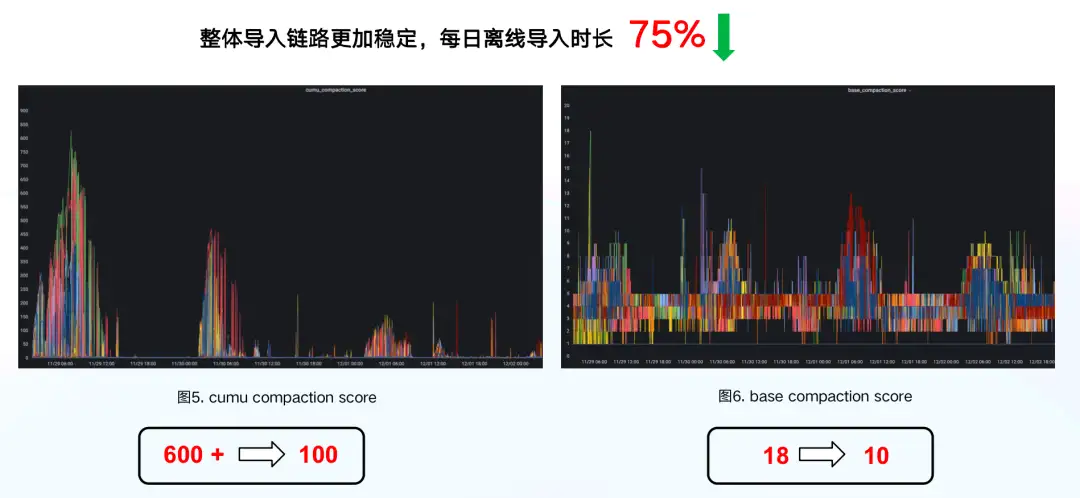
通過以上資料匯入的優化措施,使得整體匯入鏈路更加穩定,每日離線匯入時長下降了 75% ,資料版本累積情況也有所改善,其中 cumu compaction 的合併分數更是從 600+直降到 100 左右,優化效果十分明顯。
圖片
查詢優化
目前我們的場景指標資料是以分割槽表的形式儲存在 Doris 中, ES 保留一份全量的標籤資料。在我們的使用場景中,標籤圈選的使用率很高,大約有 60% 的使用場景中用到了標籤圈選,在標籤圈選場景中,通常需要滿足以下幾個要求:
- 使用者圈選邏輯比較複雜,資料架構需要支援同時有上百個標籤做圈選過濾條件。
- 大部分圈選場景只需要最新標籤資料,但是在指標查詢時需要支援歷史的資料的查詢。
- 基於圈選結果,需要進行指標資料的聚合分析。
- 基於圈選結果,需要支援標籤和指標的明細查詢。
經過調研,我們最終採用了 Doris on ES 的解決方案來實現以上要求,將 Doris 的分散式查詢規劃能力和 ES 的全文檢索能力相結合。Doris on ES 主要查詢模式如下所示:
SELECT tag, agg(metric)
FROM Doris
WHERE id in (select id from Es where tagFilter)
GROUP BY tag在 ES 中圈選查詢出的 ID 資料,以子查詢方式在 Doris 中進行指標分析。
我們在實踐中發現,查詢時長跟圈選的群體大小相關。如果從 ES 中圈選的群體規模超過 100 萬時,查詢時長會達到 60 秒,圈選群體再次增大甚至會出現超時報錯。經排查分析,主要的耗時包括兩方面:
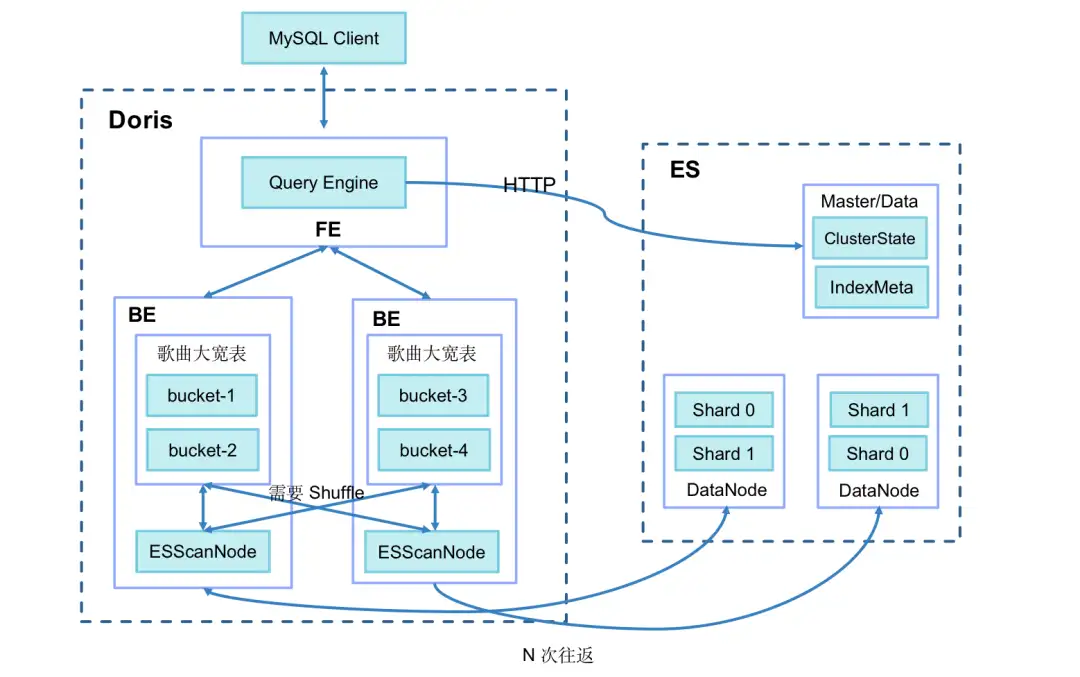
圖片
- BE 從 ES 中拉取資料(預設一次拉取 1024 行),對於 100 萬以上的群體,網路 IO 開銷會很大。
- BE 資料拉取完成以後,需要和本地的指標表做 Join,一般以 SHUFFLE/BROADCAST 的方式,成本較高。
針對這兩點,我們進行了以下優化:
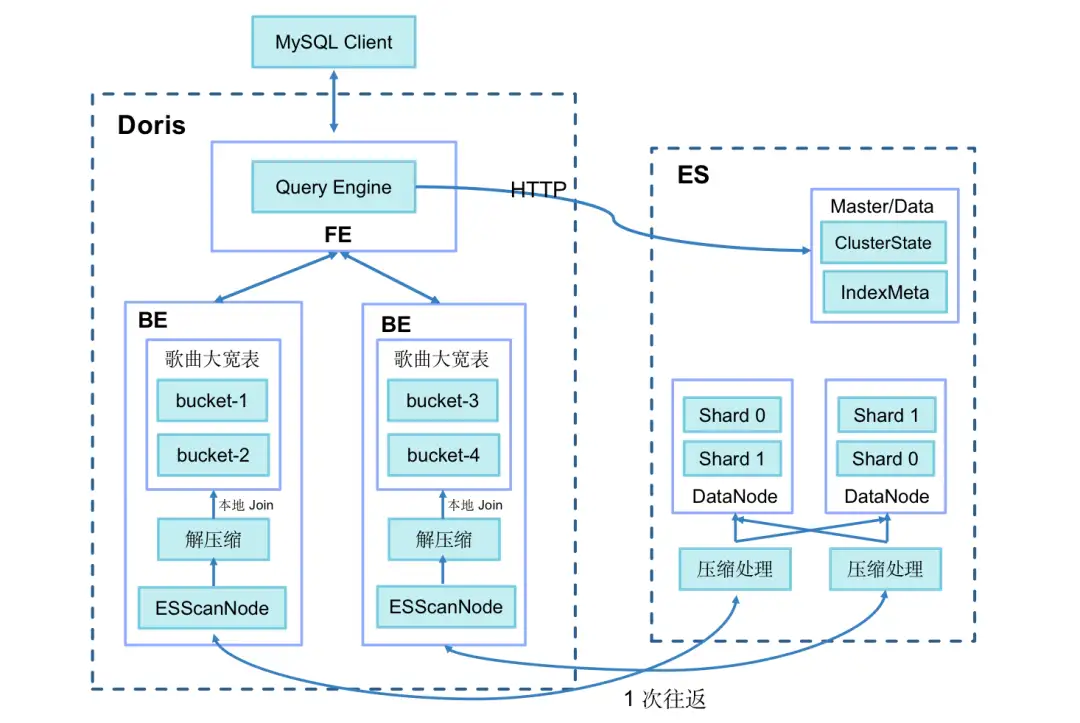
圖片
- 增加了查詢會話變數
es_optimize,以開啟優化開關; - 資料寫入 ES 時,新增 BK 列用來儲存主鍵 ID Hash 後的分桶序號,演算法和 Doris 的分桶演算法相同(CRC32);
- BE 生成 Bucket Join 執行計劃,將分桶序號下發到 BE ScanNode 節點,並下推到 ES;
- ES 對查詢出的資料進行 Bitmap 壓縮,並將資料的多批次獲取優化為一次獲取,減少網路 IO 開銷;
- Doris BE 只拉取和本地 Doris 指標表相關 Bucket 的資料,直接進行本地 Join,避免 Doris BE 間資料再 Shuffle 的過程。
通過以上優化措施,百萬分群圈選洞察查詢時間從最初的 60 秒縮短到 3.7 秒,效能顯著提升!
經過與社群溝通交流,Apache Doris 從 2.0.0 版本開始,將支援倒排索引。可進行文字型別的全文檢索;支援中文、英文分詞;支援文字、數值日期型別的等值和範圍過濾;倒排索引對陣列型別也提供了支援,多個過濾條件可以任意進行 AND OR NOT 邏輯組合。由於高效能的向量化實現和麵向 AP 資料庫的精簡優化,Doris 的倒排索引相較於 ES 會有 3~5 倍價效比提升,即將在 2 月底釋出的 2.0 preview 版本中可用於功能評估和效能測試,相信在這個場景使用後會有進一步的效能提升。
成本優化
在當前大環境下,降本提效成為了企業的熱門話題,如何在保證服務質量的同時降低成本開銷,是我們一直在思考的問題。在我們的場景中,成本優化主要得益於 Doris 自身優秀的能力,這裡為大家分享兩點:
1、冷熱資料進行精細化管理。
- 利用 Doris TTL 機制,在 Doris 中只儲存近一年的資料,更早的資料放到儲存代價更低的 TDW 中;
- 支援分割槽級副本設定,3 個月以內的資料高頻使用,分割槽設定為 3 副本 ;3-6 個月資料分割槽調整為 2 副本;6 個月之前的資料分割槽調整為1 副本;
- 支援資料轉冷, 在 SSD 中僅儲存最近 7 天的資料,並將 7 天之前的資料轉存到到 HDD 中,以降低儲存成本;
- 標籤上下線,將低價值標籤和指標下線處理後,後續資料不再寫入,減少寫入和儲存代價。
2、降低資料鏈路成本。
Doris 架構非常簡單,只有FE 和 BE 兩類程序,不依賴其他元件,並通過一致性協議來保證服務的高可用和資料的高可靠,自動故障修復,運維起來比較容易;
- 高度相容 MySQL 語法,支援標準 SQL,極大降低開發人員接入使用成本;
- 支援多種聯邦查詢方式,支援對 Hive、MySQL、Elasticsearch 、Iceberg 等元件的聯邦查詢分析,降低多資料來源查詢複雜度。
通過以上的方式,使得儲存成本降低 42%,開發與時間成本降低了 40% ,成功實現降本提效,後續我們將繼續探索!
未來規劃
未來我們還將繼續進行迭代和優化,我們計劃在以下幾個方向進行探索:
- 實現自動識別冷熱資料,用 Apache Doris 儲存熱資料,Iceberg 儲存冷資料,利用 Doris 湖倉一體化能力簡化查詢。
- 對高頻出現的標籤/指標組合,通過 Doris 的物化檢視進行預計算,提升查詢的效能。
- 探索 Doris 應用於數倉計算任務,利用物化檢視簡化程式碼邏輯,並提升核心資料的時效性。
最後,感謝 Apache Doris 社群和 SelectDB 的同學,感謝其快速響應和積極支援,未來我們也會持續將相關成果貢獻到社群,希望 Apache Doris 飛速發展,越來越好!
- 從 ClickHouse 到 Apache Doris,騰訊音樂內容庫資料平臺架構演進實踐
- Doris Connector 結合 Flink CDC 實現 MySQL 分庫分表 Exactly Once精準接入
- 應用實踐 | 10 億資料秒級關聯,貨拉拉基於 Apache Doris 的 OLAP 體系演進
- 深度解析|Apache Doris 索引機制解析
- Apache Doris常見問題答疑(一)
- 如何構建公司的資料指標體系
- Apache doris 排序鍵及ShortKey Index原理及使用
- 兩年來參與開源的感受
- Apache doris架構及元件介紹
- 基於Apache doris怎麼構建資料中臺(四)-資料接入系統
- 基於Apache doris怎麼構建資料中臺(二)-資料中臺建設內容
- 自己寫的一個BI視覺化系統(支援Apache Doris)
- Apache doris 使用過程中常見問題彙總
- Apache Doris物化檢視介紹
- Apache doris ODBC外表使用方式
- Apache doris Stream load用法
- Flink doris connector 整合Flink mysql CDC 實現實時資料入庫
- Apache doris物化檢視
- Tomcat 307 臨時重定向的坑
- Apache Doris在蜀海供應鏈資料倉庫建設中的實踐