助力藥物研發,低成本加速AlphaFold訓練從11天到67小時,11倍推理加速——開源解決方案FastFold

AlphaFold被Science和Nature評選為2021年十大科學突破之首。潞晨科技與華深智藥聯合開源的AlphaFold訓練推理加速方案FastFold,將GPU優化和大模型訓練技術引入AlphaFold的訓練和推理,成功將AlphaFold總體訓練時間從11天減少到67小時,且總成本更低,在長序列推理中也實現9.3 ∼ 11.6倍提升。
FastFold開源地址:http://github.com/hpcaitech/FastFold
蛋白質與AlphaFold
蛋白質是生命的物質基礎,幾乎支援著生命的所有功能。它們是由氨基酸鏈組成的大型複雜分子,而蛋白質的作用主要取決於其獨特的三維結構。弄清楚蛋白質摺疊成什麼形狀被稱為 "蛋白質摺疊問題",在過去的50年裡一直是生物學的一個巨大挑戰。

AlphaFold預測與實驗測量的蛋白質結構對比
實驗和計算方法都可用於預測蛋白質結構。實驗方法可以獲得更準確的蛋白質結構,但需要昂貴的時間和經濟成本。計算方法可以用低成本進行高通量的蛋白質結構預測,所以準確的計算方法一直是學術界和工業界努力的方向。2020年,Google DeepMind 推出了最新一代AlphaFold,成功將Transformer模型引入蛋白質結構預測,並取得了巨大的精度提升。AlphaFold使用端到端的模型架構,可以獲得原子級別精度的結構預測結果。

AlphaFold架構
然而,基於Transformer的AlphaFold模型也帶來了諸多計算方面的挑戰:
1)有限的全域性批處理量,使得訓練無法利用資料並行性擴充套件到更多的節點。據DeepMind官方披露,即便使用128個TPU去訓練AlphaFold,也需要11天以上才能完成;
2)在訓練過程中巨大的記憶體消耗,遠超當前GPU硬體所能提供的視訊記憶體容量。
3)在推理方面,長序列推理對GPU視訊記憶體的需求更大。而且一個長序列的推理時間對於AlphaFold模型來說甚至長達到幾個小時。
FastFold
為了解決上述難題,我們提出了FastFold,這是一個用於蛋白質結構預測的模型訓練推理加速方案。FastFold是世界上首個系統化的針對蛋白質結構預測模型進行訓練和推理的效能優化工作。FastFold成功地引入了大模型訓練技術,極大降低了AlphaFold模型訓練和推理的時間和經濟成本。
FastFold包括了一系列基於針對AlphaFold效能特徵的GPU優化。同時,通過動態軸並行和對偶非同步運算元,FastFold實現了很高的模型並行化擴充套件效率,超越了目前主流的模型並行方法。
動態軸並行。FastFold首次嘗試將模型並行技術引入AlphaFold中,並根據AlphaFold的計算特徵創新性地提出了動態軸並行技術。不同於傳統的張量並行,動態軸並行選擇在AlphaFold的特徵的序列方向上進行資料劃分,並使用All_to_All進行通訊。動態軸並行對比張量並行有幾個優勢:
1)動態軸並行支援Evoformer中的所有計算模組;
2)所需的通訊量比張量並行小得多;
3)動態軸並行視訊記憶體消耗比張量並行低;
4)DAP給通訊優化提供了更多的空間,如計算通訊重疊。

對偶非同步運算元。對偶非同步運算元由一對通訊運算元組成。在模型的前向傳播過程中,前一個通訊運算元觸發非同步通訊,然後在計算流上進行一些沒有依賴性的計算,然後後一個通訊運算元阻塞,直到通訊完成。當模型反向傳播時,後一個運算元將觸發非同步通訊,前一個運算元阻塞通訊。利用對偶非同步運算元可以讓我們在PyTorch這樣的動態圖框架上很方便的實現前向傳播和反向傳播中的計算和通訊遮疊。

卓越效能
FastFold對比目前所有的AlphaFold的實現版本都有顯著的效能優勢:
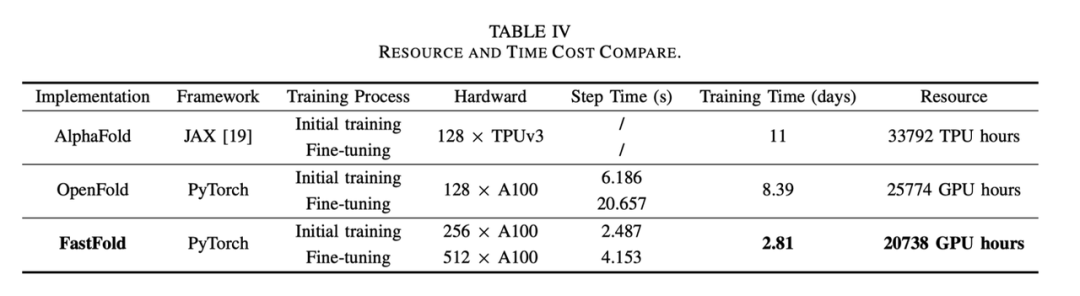
在訓練方面,FastFold可以將訓練時間減少到2.81天。與AlphaFold需要11天的訓練相比,訓練提升3.91倍。與OpenFold(來自劍橋大學的AlphaFold復現版本)相比,訓練提升2.98倍,經濟成本降低20%。我們將FastFold擴充套件到擁有512個A100 GPU的超算叢集上,聚合峰值效能達到了6.02PetaFLOPs,擴充套件效率達到90.1%。
在推理方面,FastFold在短序列,長序列,超長序列均有明顯的效能優勢:
1)在不超過1K的短序列推理的情況下,FastFold與AlphaFold和OpenFold相比,單GPU推理效能分別提升2.01 ∼ 4.05倍和1.25 ∼ 2.11倍。
2)在長度為1K ~ 3K的長序列推理中,FastFold可以使用分散式推理大幅度降低推理時間,對比OpenFold提升7.5 ∼ 9.5倍,對比AlphaFold相提升9.3 ∼ 11.6倍。
3)對於長度超過3K的超長序列推理,OpenFold和AlphaFold都因為爆視訊記憶體而無法推理。FastFold因為支援分散式推理,可以利用多個GPU的計算和視訊記憶體資源完成超長序列推理的任務。

解決蛋白質結構預測模型訓練和推理的在計算上的挑戰,對其在結構生物學的廣泛應用有重要意義。FastFold大幅度降低了AlphaFold模型訓練和推理的時間成本和經濟成本,將極大促進新一代藥物研發,蛋白質設計,抗體設計等應用場景的革命創新和發展。
背後功臣
FastFold專案的成功,得到了開源AI基礎設施Colossal-AI的大力支援。大規模並行AI系統Colossal-AI ,通過高效多維並行、大規模優化庫、自適應任務排程、消除冗餘記憶體等方式,旨在打造一個高效的分散式AI系統,作為深度學習框架的核心,幫助使用者便捷實現最大化提升AI部署效率,同時最小化部署成本。
Colossal-AI開源地址:http://github.com/hpcaitech/ColossalAI
傳送門
FastFold論文地址:http://arxiv.org/abs/2203.00854
FastFold專案地址:http://github.com/hpcaitech/FastFold
Colossal-AI專案地址:http://github.com/hpcaitech/ColossalAI
參考連結
- 開源方案復現ChatGPT流程!1.62GB視訊記憶體即可體驗,單機訓練提速7.73倍
- 硬體預算最高直降46倍!低成本上手AIGC和千億大模型,一行程式碼自動並行,Colossal-AI再升級
- 潞晨科技完成600萬美元種子及天使輪融資,藍馳領投天使輪
- 無縫支援Hugging Face社群,Colossal-AI低成本輕鬆加速大模型
- 推理加速效能超越英偉達FasterTransformer 50%,開源方案打通大模型落地關鍵路徑
- 在個人電腦用單塊GPU帶動180億引數GPT!熱門開源專案再添新特性
- 使用Colossal-AI分散式訓練BERT模型
- 使用Colossal-AI復現Pathways Language Model
- 霸榜GitHub熱門第一多日後,Colossal-AI正式版釋出
- 助力藥物研發,低成本加速AlphaFold訓練從11天到67小時,11倍推理加速——開源解決方案FastFold