理解python非同步程式設計與簡單實現asyncio
非同步程式設計
在開始說明非同步程式設計之前,首先先了解幾個相關的概念。
阻塞
程式未得到所需計算資源時被掛起的狀態。
程式在等待某個操作完成期間,自身無法繼續幹別的事情,則稱該程式在該操作上是阻塞的。
常見的阻塞形式有:網路I/O阻塞、磁碟I/O阻塞、使用者輸入阻塞等。
阻塞是無處不在的,包括CPU切換上下文時,所有的程序都無法真正幹事情,它們也會被阻塞。(如果是多核CPU則正在執行上下文切換操作的核不可被利用。)
簡單的理解的話,阻塞就是 A呼叫B,A會被掛起,一直等待B的結果,什麼都不能幹。
非阻塞
程式在等待某操作過程中,自身不被阻塞,可以繼續執行幹別的事情,則稱該程式在該操作上是非阻塞的。
非阻塞並不是在任何程式級別、任何情況下都可以存在的。
僅當程式封裝的級別可以囊括獨立的子程式單元時,它才可能存在非阻塞狀態。
非阻塞的存在是因為阻塞存在,正因為某個操作阻塞導致的耗時與效率低下,我們才要把它變成非阻塞的。
簡單理解的話,非阻塞就是 A呼叫B,A自己不用被掛起來等待B的結果,A可以去幹其他的事情
同步
不同程式單元為了完成某個任務,在執行過程中需靠某種通訊方式以協調一致,稱這些程式單元是同步執行的。
例如購物系統中更新商品庫存,需要用“行鎖”作為通訊訊號,讓不同的更新請求強制排隊順序執行,那更新庫存的操作是同步的。
簡言之,同步意味著有序。
簡單理解的話,同步就是A呼叫B,此時只有等B有了結果才返回
非同步
為完成某個任務,不同程式單元之間過程中無需通訊協調,也能完成任務的方式。
不相關的程式單元之間可以是非同步的。
例如,爬蟲下載網頁。排程程式呼叫下載程式後,即可排程其他任務,而無需與該下載任務保持通訊以協調行為。不同網頁的下載、儲存等操作都是無關的,也無需相互通知協調。這些非同步操作的完成時刻並不確定。
簡言之,非同步意味著無序。
簡單理解的話,非同步就是A呼叫B,B立即返回,無需等待。等B處理完之後再告訴A結果
併發
併發描述的是程式的組織結構。指程式要被設計成多個可獨立執行的子任務。
以利用有限的計算機資源使多個任務可以被實時或近實時執行為目的。
並行
並行描述的是程式的執行狀態。指多個任務同時被執行。
以利用富餘計算資源(多核CPU)加速完成多個任務為目的。
併發提供了一種程式組織結構方式,讓問題的解決方案可以並行執行,但並行執行不是必須的。
總的來說,並行是為了利用多核加速多工的完成;併發是為了讓獨立的子任務能夠儘快完成;非阻塞是為了提高程式的整體執行效率,而非同步是組織非阻塞任務的方式。
併發
是指的程式的組織結構,把程式設計成多個可以獨立執行的子任務。目的是使用有限的計算機資源使得多個任務可以被實時或者接近實時執行為目的。
並行
指的是程式的執行狀態,多個任務同時執行。這樣做的目的是為了利用富餘的計算資源(多核cpu),加速完成多個任務的目的。
併發提供了一種組織結構方式,讓問題的解決方式可以並行執行,但是這不是必須的。
綜上
並行是為了利用多核計算機的富餘計算資源來加速多工程式完成的進度。
併發是為了讓獨立的子任務有機會被儘快執行,但是不一定會加快整體的進度。
非阻塞是為了提高程式執行的整體效率。
非同步是組織非阻塞任務的方式。
非同步程式設計
以程序、執行緒、協程、函式/方法作為執行任務程式的基本單位,結合回撥、事件迴圈、訊號量等機制,以提高程式整體執行效率和併發能力的程式設計方式。
非同步執行的程式一定是無序的,如果你可以根據已經執行的指令,準確的判斷出,它接下里要去執行的某個具體操作,那麼它就是同步程式。這是有序和無序的區別。
非同步程式設計的困難在於,因為非同步執行的程式,它的執行順序不可預料,所以在並行情況下變得比較複雜和艱難。
所以幾乎所有的非同步框架都將非同步程式設計模型簡化:一次只允許處理一個事件。因此關於非同步的討論基本上都集中在了單執行緒中。
如果某個事件的處理過程過長,那麼其他部分就會被阻塞。
所以非同步程式設計的非同步排程必須要“足夠小”,不能耗時太久。
合理的用非同步程式設計的方式可以提高 cpu 的利用率,提高程式效率。
同步->非同步I/O
以一個爬蟲為例,下載10篇網頁,用幾個例子來展示從同步->非同步。
同步阻塞方式
以同步阻塞方式來寫這個程式也是最容易想到的方式,即依次下載好10篇網頁。
import socket
def blocking_way():
sock = socket.socket()
# 阻塞
sock.connect(('example.com', 80))
request = 'GET / HTTP/1.0\r\nHost: example.com\r\n\r\n'
sock.send(request.encode('ascii'))
response = b''
chunk = sock.rev(4096)
while chunk:
response += chunk
# 阻塞
chunk = sock.rev(4096)
return response
def sync_way():
res = []
for i in range(10):
res.append(blocking_way())
return len(res)
複製程式碼這段程式碼的執行事件大概為4.5秒。(取多次平均值)
上述程式碼中, blocking_way()這個函式的作用主要是建立連線,傳送HTTP請求,然後從socket讀取HTTP響應請求到並返回資料。
sync_way()將blocking_way()執行了10次,也就是說,我們執行了10次訪問下載 example.com
由於網路情況和服務端的處理各不相同,所以服務端什麼時候返回了響應資料並被客戶端接收到可供程式讀取,也是不可預測的。所以 sock.connect() 和 sock.recv() 這兩個呼叫在預設情況下是阻塞的。
注:sock.send()函式並不會阻塞太久,它只負責將請求資料拷貝到TCP/IP協議棧的系統緩衝區中就返回,並不等待服務端返回的應答確認。
如果是說網路環境很差的話,建立網路連線的TCP/IP握手需要1秒,那麼 sock.connect() 就得阻塞1秒。這一秒時間對CPU來說就被浪費了。同理,sock.recv() 也一樣的必須得等到服務端的響應資料已經被客戶端接收,才能進行後續的程式。目前的例子上只有只需要下載一篇網頁,阻塞10次看起來好像沒有什麼問題,可是如果需求是1000w篇的話,這種阻塞的方式就顯得很蠢,效率也很低下。
改進:多程序
在一個程式中,依次執行10次好像有些耗時,那麼我們使用多程序,開10個同樣的程式一起處理的話,也許會好一些?於是第一個改進方式便出來了:多程序程式設計。發展脈絡也是如此。在更早的作業系統(Linux 2.4)及其以前,程序是 OS 排程任務的實體,是面向程序設計的OS。
import socket
from concurrent import futures
def blocking_way():
sock =socket.socket()
# 阻塞
sock.connect(('example.com', 80))
request = 'GET /HTTP/1.0\r\nHost: example.com\r\n\r\n'
sock.send(request.encode('acsii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
return response
def process_way():
workers = 10
with futures.ProcessPoolExecutor(workers) as executor:
futs = {executor.sumbit(blocking_way) for i in range(10)}
return len([fut.result() for fut in futs])
複製程式碼這段程式碼執行時間大概為0.6秒。
按理說,使用10個相同的程序來執行這段程式,其執行時間應該是會縮短到原來的1/10,然而並沒有。這裡面還有一些時間被程序的切換所消耗掉了。
CPU從一個程序切換到另一個程序的時候,需要把舊程序執行時的暫存器狀態,記憶體狀態都儲存好,然後再將另一個程序之前儲存的資料恢復。當程序數量大於CPU核心數的時候,程序切換是必須的。
一般來說,伺服器在能夠穩定執行的前提下,可以同時處理的程序數在數十個到數百個規模。如果程序數量規模更大,系統執行將不穩定,而且可用記憶體資源往往也會不足。除了切換開銷大,以及可支援的任務規模小之外,多程序還有其他缺點,如狀態共享等問題。
改進:多執行緒
執行緒的資料結構比程序更加的輕量級,同一個程序可以容納好幾個執行緒。
後來的OS也把排程單位由程序轉為執行緒,程序只作為執行緒的容器,用於管理程序所需的資源。而且OS級別的執行緒是可以被分配到不同的CPU核心同時執行的。
import socket
from concurrent import futures
def blocking_way():
sock = socket.socket()
# 阻塞
sock.connect(('example.com', 80))
request = 'GET / HTTP/1.0\r\nHost: example.com\r\n\r\n'
sock.send(request.encode('acsii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
# 阻塞
chunk = sock.recv(4096)
return response
def thread_way():
wokers = 10
with futures.ThreadPoolExecutor(workers) as executor:
futs = {executor.sumbit(blocking_way) for i in range(10)}
return len([fut.result(fut.result() for fut in futs)])
複製程式碼總執行時間大概為0.43秒。
從執行時間上來看,多執行緒好像已經解決了程序切換開銷大的問題,而且可支援的任務數量規模,也變成了數百個到數千個。
但是由於CPython中的多執行緒因為GIL的存在,它們並不能利用CPU多核優勢,一個Python程序中,只允許有一個執行緒處於執行狀態。
在做阻塞的系統呼叫時,例如sock.connect(),sock.recv()時,當前執行緒會釋放GIL,讓別的執行緒有執行機會。但是單個執行緒內,在阻塞呼叫上還是阻塞的。
Python中 time.sleep 是阻塞的,都知道使用它要謹慎,但在多執行緒程式設計中,time.sleep 並不會阻塞其他執行緒。
除了GIL之外,所有的多執行緒還有通病。它們是被OS排程,排程策略是搶佔式的,以保證同等優先順序的執行緒都有均等的執行機會,那帶來的問題是:並不知道下一時刻是哪個執行緒被執行,也不知道它正要執行的程式碼是什麼。所以就可能存在競態條件。如果在一個複雜的爬蟲系統中,要抓取的URL由多個爬蟲執行緒來拿,那麼URL如何分配,這就需要用到“鎖”或“同步佇列”來保證下載任務不會被重複執行。多執行緒最主要的問題還是競態條件。
非阻塞方式
千呼萬喚使出來,下例是最原始的非阻塞。
import socket
def noblock_way():
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('example.com', 80))
except BlockingIOError:
# 非阻塞過程也會丟擲異常
pass
request = 'GET / HTTP /1.0\r\nHost: example.com\r\n\r\n'
data = request.encode('ascii')
# 不斷重複嘗試傳送
while True:
try:
sock.send(data)
# send不出現異常,停止
break
except OSError:
pass
response = b''
while True:
try:
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
break
except OSError:
pass
return response
def sync_way():
res = []
for i in range(10):
res.append(noblock_way())
return len(res)
複製程式碼程式總耗時約4.3秒。
執行完這段程式碼的時候,感覺好像是被騙了,程式碼的執行時間和非阻塞方式差不多,而且程式更復雜了。要非阻塞何用?
程式碼sock.setblocking(False)告訴OS,讓socket上阻塞呼叫都改為非阻塞的方式。非阻塞就是在做一件事的時候,不阻礙呼叫它的程式做別的事情。上述程式碼在執行完 sock.connect() 和 sock.recv() 後的確不再阻塞,可以繼續往下執行請求準備的程式碼或者是執行下一次讀取。第8行要放在try語句內,是因為socket在傳送非阻塞連線請求過程中,系統底層也會丟擲異常。connect()被呼叫之後,立即可以往下執行第12和13行的程式碼。
雖然 connect() 和 recv() 不再阻塞主程式,空出來的時間段CPU沒有空閒著,但並沒有利用好這空閒去做其他有意義的事情,而是在迴圈嘗試讀寫 socket (不停判斷非阻塞呼叫的狀態是否就緒)。還得處理來自底層的可忽略的異常。也不能同時處理多個 socket。 所以總體執行時間和同步阻塞相當。
非阻塞改進
epoll
其實判斷非阻塞呼叫是否就緒可以交給OS來做,不用應用程式自己去等待和判斷,可以用這個空閒時間去做其他的事情。
OS將O/I的變化都封裝成了事件,比如可讀事件、可寫事件。而且提供了相應的系統模組以供呼叫來接收事件通知。這個模組就是select,讓應用程式可以通過select註冊檔案描述符和回撥函式。當檔案描述符的狀態發生變化時,select 就呼叫事先註冊的回撥函式。
select因其演算法效率比較低,後來改進成了poll,再後來又有進一步改進,BSD核心改進成了kqueue模組,而Linux核心改進成了epoll模組。這四個模組的作用都相同,暴露給程式設計師使用的API也幾乎一致,區別在於kqueue 和 epoll 在處理大量檔案描述符時效率更高。一般的Linux伺服器是使用的 epoll。
回撥(callback)
將I/O事件的監聽交給OS來處理,那麼OS在知道I/O狀態發生改變之後應該如何處理呢,這裡一般都是通過回撥的方式。
把傳送資料和讀取資料封裝成獨立的函式,用epoll代替應用程式監聽socket狀態,而且需要告知epoll “如果socket狀態變為可以往裡寫資料(連線建立成功了),請呼叫HTTP請求傳送函式。如果socket 變為可以讀資料了(客戶端已收到響應),請呼叫響應處理函式。”
import socket
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
# selectors模組是對底層select/poll/epoll/kqueue的封裝
# DefaultSelector類會根據 OS 環境自動選擇最佳的模組
"""
建立Crawler 例項;
呼叫fetch方法,會建立socket連線和在selector上註冊可寫事件;
fetch內並無阻塞操作,該方法立即返回;
重複上述3個步驟,將10個不同的下載任務都加入事件迴圈;
啟動事件迴圈,進入第1輪迴圈,阻塞在事件監聽上;
當某個下載任務EVENT_WRITE被觸發,回撥其connected方法,第一輪事件迴圈結束;
進入第2輪事件迴圈,當某個下載任務有事件觸發,執行其回撥函式;此時已經不能推測是哪個事件發生,因為有可能是上次connected裡的EVENT_READ先被觸發,也可能是其他某個任務的EVENT_WRITE被觸發;(此時,原來在一個下載任務上會阻塞的那段時間被利用起來執行另一個下載任務了)
迴圈往復,直至所有下載任務被處理完成
退出事件迴圈,結束整個下載程式
"""
selector = DefaultSelector()
stopped = False
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
class Crawler:
"""
如果用這種方法抓去,需要建立10個Crawler例項,這樣就會有20個事件發生
"""
def __init__(self, url):
self.url = url
self.sock = None
self.response = b''
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('example.com', 80))
except BlockingIOError:
pass
selector.register(self.sock.fileno(), EVENT_WRITE, self.connected)
def connected(self, key, mask):
selector.unregister(key.fd)
get = 'GET {0} HTTP/1.0\r\nHost: example.com\r\n\r\n'.format(self.url)
self.sock.send(get.encode('ascii'))
selector.register(key.fd, EVENT_READ, self.read_response)
def read_response(self, key, mask):
global stopped
# 如果響應大於4kb,下次迴圈繼續
chunk = self.sock.recv(4096)
if chunk:
self.response += chunk
else:
selector.unregister(key.fd)
urls_todo.remove(self.url)
if not urls_todo:
stopped =True
def loop():
while not stopped:
# 阻塞,直到一個事件發生
events = selector.select() # 這是一個阻塞呼叫
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
if __name__ == "__main__":
import time
start = time.time()
for url in urls_todo:
crawler = Crawler(url)
crawler.fetch()
loop()
print(time.time() - start)
複製程式碼總體耗時約0.45秒。
與之前函式不太一眼的地方是,我們將下載10個不同的URL介面,然後將URL的相對路徑儲存在 urls_todo 中。具體的改進如下。
首先是不斷嘗試 send() 和 recv() 這兩個迴圈被取消掉了。
其次,匯入了selectors模組,並建立了一個DefaultSelector 例項。Python標準庫提供的selectors模組是對底層select/poll/epoll/kqueue的封裝。DefaultSelector類會根據 OS 環境自動選擇最佳的模組,那在 Linux 2.5.44 及更新的版本上都是epoll了。
然後分別註冊了socket可寫事件(EVENT_WRITE)以及可讀事件(EVENT_READ)發生後應該採取的回撥函式。
但是這裡有一個問題,我們如何才能知道這10個Crawler例項建立的20個事件,哪個是當前正在發生的事件,從selector中拿出來,並且得到對應的回撥函式去執行呢?
事件迴圈
所以我們在程式碼結尾加入了事件迴圈,寫一個函式,迴圈地去訪問selector模組,等待它告訴我們當前是哪個事件發生了,對應的應該是哪個回撥函式。
在 loop() 這個事件迴圈的函式中,採用了stopped全域性變數來控制事件迴圈的停止,當urls_todo消耗完畢之後,會標記stopped為True。
在事件迴圈裡面有一個阻塞呼叫,selector.select() 。如果事件不發生,那麼應用程式就沒事件可處理,所以就乾脆阻塞在這裡等待事件發生。那可以推斷,如果只下載一篇網頁,一定要connect()之後才能send()繼而recv(),那它的效率和阻塞的方式是一樣的。因為不在connect()/recv()上阻塞,也得在select()上阻塞。
所以,selector機制(後文以此稱呼代指epoll/kqueue)是設計用來解決大量併發連線的。當系統中有大量非阻塞呼叫,能隨時產生事件的時候,selector機制才能發揮最大的威力。
在單執行緒內用 事件迴圈+回撥 搞定了10篇網頁同時下載的問題。這,已經是非同步程式設計了。雖然有一個for 迴圈順序地建立Crawler 例項並呼叫 fetch 方法,但是fetch 內僅有connect()和註冊可寫事件,而且從執行時間明顯可以推斷,多個下載任務確實在同時進行!
上述程式碼非同步執行的過程:
-
建立Crawler 例項;
-
呼叫fetch方法,會建立socket連線和在selector上註冊可寫事件;
-
fetch內並無阻塞操作,該方法立即返回;
-
重複上述3個步驟,將10個不同的下載任務都加入事件迴圈;
-
啟動事件迴圈,進入第1輪迴圈,阻塞在事件監聽上;
-
當某個下載任務EVENT_WRITE被觸發,回撥其connected方法,第一輪事件迴圈結束;
-
進入第2輪事件迴圈,當某個下載任務有事件觸發,執行其回撥函式;此時已經不能推測是哪個事件發生,因為有可能是上次connected裡的EVENT_READ先被觸發,也可能是其他某個任務的EVENT_WRITE被觸發;(此時,原來在一個下載任務上會阻塞的那段時間被利用起來執行另一個下載任務了)
-
迴圈往復,直至所有下載任務被處理完成
-
退出事件迴圈,結束整個下載程式
做非同步程式設計,上述的“事件迴圈+回撥”這種模式是逃不掉的,儘管它可能用的不是epoll,也可能不是while迴圈。
但是在某些非同步程式設計中並沒有看到 CallBack 模式呢?比如Python的非同步程式設計中,其主角是協程。
協程與asyncio
協程
協程(Co-routine),即是協作式的例程
它是非搶佔式的多工子例程的概括,可以允許有多個入口點在例程中確定的位置來控制程式的暫停與恢復執行。
例程是什麼?程式語言定義的可被呼叫的程式碼段,為了完成某個特定功能而封裝在一起的一系列指令。一般的程式語言都用稱為函式或方法的程式碼結構來體現。
首先,要知道的是,無論是多程序,多執行緒還是協程,都是為了解決多工同時進行的問題。而多工系統實現的關鍵在於如何暫停當前任務,儲存當前任務的上下文,選擇下一個任務,恢復下一個任務的上下文 ,執行下一個任務。
對計算機的不同層次來說,上下文的含義也不一樣。
- 對CPU來說,上下文就是運算元暫存器、棧暫存器、狀態暫存器等各類暫存器。
- 對於程序來說,上下文就是,暫存器、訊號、分配的記憶體空間,檔案描述符等各類由 cpu 抽象的出來的硬體資源
- 對於執行緒來說,上下文就是,暫存器,執行緒堆疊···
- 對於一個函式來說,上下文就是當前的名稱空間。
程序的切換 需要 切換系統資源和指令,消耗時間最長。
執行緒的切換,不需要切換系統資源,只需要切換指令、執行緒堆疊。但這個過程也需要系統呼叫。
協程的切換都在使用者空間內進行,不需要進行系統呼叫。
在Python中執行緒切換,是由 python 虛擬機器控制,通過一個系統呼叫,來進行執行緒切換。協程的切換過程完全由程式自身控制。
協程優於執行緒的主要在於
- python 執行緒排程方式是,Python2.x中每執行 100 個位元組碼或者遇到阻塞就停止當前執行緒,在Python3中則是使用固定時間了,而不再是ticks計數達到100釋放GIL,然後進行一個系統呼叫,讓 os 核心選出下一個執行緒。但是協程 只會在 阻塞的時候,切換到下一個協程。100個位元組碼,說多不多,說少不少,可能呼叫兩個庫函式說不定就沒了,因此執行緒的切換存在很多是無效的切換,當執行緒數量越大,這種因為排程策略的先天不足帶來的效能損耗就越大。
- 執行緒需要進行系統呼叫,協程不需要。系統呼叫需要進入核心態,無效的排程會讓這部分開銷顯得更大
- 協程可以自主排程,而執行緒只能決定合適退出,但是下一個執行緒是誰則依賴於作業系統。
Python中,協程有兩種,一種無棧協程,python 中以 asyncio 為代表,一種有棧協程,python 中以 gevent 為代表。
yield 和 yield from
yield
目前最新的Python已經沒有采用基於 yield 的協程了。但是為了更好的理解協程,先來一個簡單的 yield 的小例子。
def fun_e():
print('yield 1')
yield 1
print('yield 2')
yield 2
gen = fun_e()
print('start')
a = gen.send(None)
print('生成器的第一個值', a)
b = gen.next(None)
print('生成器的第二個值', b)
複製程式碼上面程式碼的輸出結果是
start
yield 1
生成器的第一個值 1
yield 2
生成器的第二個值 2
複製程式碼這裡程式執行到第一個 yield 的時候,儲存了函式的上下文之後便退出了,然後又通過 next 方法進入了這個函式,將剛剛儲存的函式上下文恢復並繼續執行。
一個協程程式的所有就是:儲存上下文 切換執行程式 恢復上下文 重新進入程式。
Cpython中的上下文,被封裝成了一個PyFrameObject的結構,也可以叫它棧幀。
原始碼:
typedef struct _frame {
PyObject_VAR_HEAD
struct _frame *f_back; /* previous frame, or NULL */
PyCodeObject *f_code; /* code segment */
PyObject *f_builtins; /* builtin symbol table (PyDictObject) */
PyObject *f_globals; /* global symbol table (PyDictObject) */
PyObject *f_locals; /* local symbol table (any mapping) */
PyObject **f_valuestack; /* points after the last local */
/* Next free slot in f_valuestack. Frame creation sets to f_valuestack.
Frame evaluation usually NULLs it, but a frame that yields sets it
to the current stack top. */
PyObject **f_stacktop;
PyObject *f_trace; /* Trace function */
char f_trace_lines; /* Emit per-line trace events? */
char f_trace_opcodes; /* Emit per-opcode trace events? */
/* Borrowed reference to a generator, or NULL */
/* 生成器的指標 */
PyObject *f_gen;
int f_lasti; /* 上一個執行的位元組碼位置 */
/* Call PyFrame_GetLineNumber() instead of reading this field
directly. As of 2.3 f_lineno is only valid when tracing is
active (i.e. when f_trace is set). At other times we use
PyCode_Addr2Line to calculate the line from the current
bytecode index. */
int f_lineno; /* 對應的Python原始碼行數 */
int f_iblock; /* index in f_blockstack */
char f_executing; /* whether the frame is still executing */
PyTryBlock f_blockstack[CO_MAXBLOCKS]; /* for try and loop blocks */
PyObject *f_localsplus[1]; /* locals+stack, dynamically sized */
} PyFrameObject;
複製程式碼在Python的實際執行中,會產生很多的PyFrameObject物件,然後這些物件都被連結起來,形成一條連結串列。
在Python中的生成器的結構體定義是一個巨集,它指向一個PyFrameObject物件,表示這個生成器的上下文。
在生成器這個結構體中,有3個重要的東西:
- 指向生成器上下文的指標
- 一個指示生成器狀態的字串 未啟動,停止,執行,結束
- 生成器的位元組碼
即 上下文 + 指令序列 + 狀態
在生成器中,next 和 send 的作用相同,但是 send 可以傳入一個引數。
yield from
在生成器中,可以使用return返回值,但如果 send 走到 return 語句的時候會報一個StopIteration。 return 返回值的 就在 exception 的 value 中。
如下例:
def test_fun1():
yield 1
return 2
gen = test_fun1()
try:
gen.send(None)
gen.send(None)
except StopIteration as e:
print(e.value)
複製程式碼執行以上程式碼的輸出結果是 2
yield from 有兩重性質,一方面,它是一個表示式,表示式自然是有值的,他的值,就是yield from 後面生成器 return 的返回值。非常關鍵的一點,生成器的 yield 語句會向外產出值,但是 return 的值並不會向外產出。想要獲得 return 的返回值,要麼用 try 語句捕獲異常要麼用 yield from 表示式獲取值。
可以看一下下面這例子
def test_fun1():
yield 1
return 2
def test_fun2():
a = yield from test_fun1()
print(f"yield from 表示式的值為 {a}")
yield None
gen = test_fun2()
gen.send(None)
gen.send(None)
複製程式碼輸出結果:
yield from 表示式的值為 2
yield from 還有一個特點就是可以將內層的生成器的返回值,傳到外層。
就像下面這個例子:
def test_gen1():
yield 1
yield 2
return 3
def test_gen2():
a = yield from test_gen1()
print(f"yield from {a}")
for i in test_gen2():
print(i)
複製程式碼輸出結果為:
1
2
yield from 3
複製程式碼內層生成器 test_gen1() 可以通過 yield from 在最外層將值取出來。
這樣我們使用 yield from 可以將多個生成器連線起來。
簡單理解 yield
一開始接觸 yield 的時候很不好理解這個 yield的用法,不明白什麼叫做生成器,什麼引數傳遞。其實可以直接把 yield 先簡單看成 return,程式執行到 yield 的時候就停止了。
先看一個簡單的例子
def example():
print("開始...")
while True:
res = yield 4
print("res:",res)
g = example()
print(next(g))
print("*"*20)
print(next(g))
複製程式碼輸出結果:
開始...
4
********************
res: None
4
複製程式碼上述程式碼的執行順序為:
- 程式開始執行以後,因為foo函式中有yield關鍵字,所以foo函式並不會真的執行,而是先得到一個生成器g(相當於一個物件)
- 直到呼叫next方法,foo函式正式開始執行,先執行foo函式中的print方法,然後進入while迴圈
- 程式遇到yield關鍵字,然後把yield想想成return,return了一個4之後,程式停止,並沒有執行賦值給res操作,此時next(g)語句執行完成,所以輸出的前兩行(第一個是while上面的print的結果,第二個是return出的結果)是執行print(next(g))的結果,
- 程式執行print("*"20),輸出20個
- 又開始執行下面的print(next(g)),這個時候和上面那個差不多,不過不同的是,這個時候是從剛才那個next程式停止的地方開始執行的,也就是要執行res的賦值操作,這時候要注意,這個時候賦值操作的右邊是沒有值的(因為剛才那個是return出去了,並沒有給賦值操作的左邊傳引數),所以這個時候res賦值是None,所以接著下面的輸出就是res:None,
- 程式會繼續在while裡執行,又一次碰到yield,這個時候同樣return 出4,然後程式停止,print函式輸出的4就是這次return出的4
yield和return的關係和區別了,帶yield的函式是一個生成器,而不是一個函數了,這個生成器有一個函式就是next函式,next就相當於“下一步”生成哪個數,這一次的next開始的地方是接著上一次的next停止的地方執行的,所以呼叫next的時候,生成器並不會從 example 函式的開始執行,只是接著上一步停止的地方開始,然後遇到yield後,return出要生成的數,此步就結束。
再來一個 send 的例子:
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(g.send(7))
複製程式碼輸出結果
starting...
4
********************
res: 7
4
複製程式碼先大致說一下send函式的概念:此時你應該注意到上面那個的紫色的字,還有上面那個res的值為什麼是None,這個變成了7,到底為什麼,這是因為,send是傳送一個引數給res的,因為上面講到,return的時候,並沒有把4賦值給res,下次執行的時候只好繼續執行賦值操作,只好賦值為None了,而如果用send的話,開始執行的時候,先接著上一次(return 4之後)執行,先把7賦值給了res,然後執行next的作用,遇見下一回的yield,return出結果後結束。
接上之前的步驟:
- 程式執行g.send(7),程式會從yield關鍵字那一行繼續向下執行,send會把7這個值賦值給res變數
- 由於send方法中包含next()方法,所以程式會繼續向下執行執行print方法,然後再次進入while迴圈
- 程式執行再次遇到yield關鍵字,yield會返回後面的值後,程式再次暫停,直到再次呼叫next方法或send方法。
基於生成器的協程
前面說了這麼多,在Python裡面為什麼要使用協程來解決非同步的問題呢。我們先來看看前面講到的“事件迴圈+回撥”這種方式的問題。
“事件迴圈+回撥”的問題
在單執行緒內使用前面爬蟲例子中的非同步程式設計,也確實能夠大大提高程式執行效率。但是在生產專案中,要應對的複雜度會大大增加。考慮如下問題:
- 如果回撥函式執行不正常該如何?
- 如果回撥裡面還要巢狀回撥怎麼辦?要巢狀很多層怎麼辦?
- 如果嵌套了多層,其中某個環節出錯了會造成什麼後果?
- 如果有個資料需要被每個回撥都處理怎麼辦?
- ......
在實際程式設計中,上述問題不好避免,也確實存在這麼些的缺陷。
-
回撥層次過多時程式碼可讀性差
def callback_1(): # processing ... def callback_2(): # processing..... def callback_3(): # processing .... def callback_4(): #processing ..... def callback_5(): # processing ...... async_function(callback_5) async_function(callback_4) async_function(callback_3) async_function(callback_2) async_function(callback_1) 複製程式碼 -
破壞程式碼結構
在寫同步的程式的時候,程式碼一般是自上而下執行的。
fun_1() fun_2(params) 複製程式碼在上面的程式碼中,如果 fun_2 函式的處理依賴 fun_1 函式處理的結果,但是 fun_1 函式是非同步呼叫的,那麼就不知道 fun_1 什麼時候返回值,需要將後續處理的結果以 callback 的形式返回給 fun_1,讓 fun_1 執行完之後去執行 fun_2,那麼程式碼變成如下:
fun_1(fun_2()) 複製程式碼如果整個流程都是非同步處理,然後流程比較長的話:
fun_1(fun_2(fun_3(fun_4(......)))) 複製程式碼
如果是同步執行的程式,程式中的每一步都是執行緒的指令指標控制著的流程,而在回撥版本中,流程就是程式設計的人需要注意和安排的。
-
共享狀態管理困難 回顧之前的爬蟲程式碼,同步阻塞版的sock物件從頭使用到尾,而在回撥的版本中,我們必須在Crawler例項化後的物件self裡儲存它自己的sock物件。如果不是採用OOP的程式設計風格,那需要把要共享的狀態接力似的傳遞給每一個回撥。多個非同步呼叫之間,到底要共享哪些狀態,事先就得考慮清楚,精心設計。
-
錯誤處理困難 一連串的回撥構成一個完整的呼叫鏈。例如上述的 a 到 f。假如 d 拋了異常怎麼辦?整個呼叫鏈斷掉,接力傳遞的狀態也會丟失,這種現象稱為呼叫棧撕裂。 c 不知道該幹嘛,繼續異常,然後是 b 異常,接著 a 異常。好嘛,報錯日誌就告訴你,a 調用出錯了,但實際是 d 出錯。所以,為了防止棧撕裂,異常必須以資料的形式返回,而不是直接丟擲異常,然後每個回撥中需要檢查上次呼叫的返回值,以防錯誤吞沒。
程式碼風格難看是小事,但棧撕裂和狀態管理困難這兩個缺點會讓基於回撥的非同步程式設計很艱難。
Python在事件迴圈+回撥的基礎上衍生出了基於協程的解決方案,代表作有 Tornado、Twisted、asyncio 等。
未來物件
Python 中有種特殊的物件——生成器(Generator),它的特點和協程很像。每一次迭代之間,會暫停執行,繼續下一次迭代的時候還不會丟失先前的狀態。
為了支援用生成器做簡單的協程,Python 2.5 對生成器進行了增強(PEP 342),該增強提案的標題是 “Coroutines via Enhanced Generators”。有了PEP 342的加持,生成器可以通過yield 暫停執行和向外返回資料,也可以通過send()向生成器內傳送資料,還可以通過throw()向生成器內丟擲異常以便隨時終止生成器的執行。
這裡我們不用回撥的方式了,怎麼知道非同步呼叫的結果呢?先設計一個物件,非同步呼叫執行完的時候,就把結果放在它裡面。這種物件稱之為未來物件。
class Future:
"""
未來物件
非同步呼叫執行完的時候,就把結果放在它裡面。
"""
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
複製程式碼未來物件有一個result屬性,用於存放未來的執行結果。還有個set_result()方法,是用於設定result的,並且會在給result繫結值以後執行事先給future新增的回撥。回撥是通過未來物件的add_done_callback()方法新增的。
雖然這個地方還是有 callback,但是這個 callback 和之前的不太一樣。
重構Crawler爬蟲
因為有了未來物件,我們先用Future來重構一下爬蟲。
class Crawler:
def __init__(self, url):
self.url = url
self.response = b''
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('example.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connect():
f.set_result(None)
selector.register(sock.fileno(), EVENT_WRITE, on_connect)
yield f
selector.unregister(sock.fileno())
get = 'GET {0} HTTP/1.0 \r\nHost: example.com\r\n\r\n'.format(self.url)
sock.send(get.encode('ascii'))
global stopped
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
break
複製程式碼這裡的 fetch方法內有了yield表示式,所以它成為生成器。生成器需要先呼叫next()迭代一次或者是先send(None)啟動,遇到yield之後便暫停。那這fetch生成器如何再次恢復執行呢?但是目前還有生成器的啟動程式碼。這裡我們需要新增一個任務物件(Task)來啟動它。
任務物件(Task)
遵循一個程式設計規則:單一職責,每種角色各司其職。目前還沒有一個角色來負責生成器的執行和管理生成器的狀態,那麼我們就建立一個。
class Task:
"""任務物件"""
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
# send放到coro執行,即fetch,直到下次yield
# next_future為yield返回物件
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
複製程式碼上述程式碼中Task封裝了coro物件,即初始化時傳遞給他的物件,被管理的任務是待執行的協程,故而這裡的coro就是fetch()生成器。它還有個step()方法,在初始化的時候就會執行一遍。step()內會呼叫生成器的send()方法,初始化第一次傳送的是None就驅動了coro即fetch()的第一次執行。
send()完成之後,得到下一次的future,然後給下一次的future新增step()回撥。add_done_callback()其實不是給寫爬蟲業務邏輯用的。
再看一下fetch()生成器,其內部寫完了所有的業務邏輯,包括如何傳送請求,如何讀取響應。而且註冊給 selector 的回撥相當簡單,就是給對應的 future 物件繫結結果值。兩個 yield 表示式都是返回對應的 future 物件,然後返回 Task.step() 之內,這樣 Task, Future, Coroutine三者就串聯在了一起。
初始化Task物件以後,把fetch()給驅動到了第 yied f 就完事了,接下來應該怎麼繼續。
事件迴圈(Event Loop)驅動協程執行
接下來,只需等待已經註冊的EVENT_WRITE事件發生。事件迴圈就像心臟一般,只要它開始跳動,整個程式就會持續執行。
def loop():
"""事件迴圈驅動協程"""
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
複製程式碼整個重構之後的爬蟲
完整的程式如下:
import socket
from selectors import EVENT_READ, EVENT_WRITE, DefaultSelector
from socket import create_connection
selector = DefaultSelector()
stopped = False
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
class Future:
"""
未來物件
非同步呼叫執行完的時候,就把結果放在它裡面。
"""
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
class Crawler:
def __init__(self, url):
self.url = url
self.response = b''
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('example.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connect():
f.set_result(None)
selector.register(sock.fileno(), EVENT_WRITE, on_connect)
yield f
selector.unregister(sock.fileno())
get = 'GET {0} HTTP/1.0 \r\nHost: example.com\r\n\r\n'.format(self.url)
sock.send(get.encode('ascii'))
global stopped
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
break
class Task:
"""任務物件"""
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
# send放到coro執行,即fetch,直到下次yield
# next_future為yield返回物件
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
def loop():
"""事件迴圈驅動協程"""
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
if __name__ == "__main__":
import time
start = time.time()
for url in urls_todo:
crawler = Crawler(url)
Task(crawler.fetch())
loop()
print(time.time() - start)
"""
現在loop有了些許變化,callback()不再傳遞event_key和event_mask引數。也就是說,
這裡的回撥根本不關心是誰觸發了這個事件,
結合fetch()可以知道,它只需完成對future設定結果值即可f.set_result()。
"""
複製程式碼生成器風格和回撥風格總結
在回撥風格中:
-
存在鏈式回撥(雖然示例中巢狀回撥只有一層)
-
請求和響應也不得不分為兩個回撥以至於破壞了同步程式碼那種結構
-
程式設計師必須在回撥之間維護必須的狀態。
而基於生成器協程的風格:
-
無鏈式呼叫
-
selector的回撥裡只管給future設定值,不再關心業務邏輯
-
loop 內回撥callback()不再關注是誰觸發了事件
-
已趨近於同步程式碼的結構
-
無需程式設計師在多個協程之間維護狀態,例如哪個才是自己的sock
yield from 改進生成器協程
如果說fetch的容錯能力要更強,業務功能也需要更完善,怎麼辦?而且技術處理的部分(socket相關的)和業務處理的部分(請求與返回資料的處理)混在一起。
-
建立socket連線可以抽象複用吧?
-
迴圈讀取整個response可以抽象複用吧?
-
迴圈內處理socket.recv()的可以抽象複用吧?
但是這些關鍵節點的地方都有yield,抽離出來的程式碼也需要是生成器。而且fetch()自己也得是生成器。生成器裡搗鼓生成器,好像有些麻煩。
好在有 yield from 來解決這個問題。
yield from 語法
yield from 是Python 3.3 新引入的語法(PEP 380)。它主要解決的就是在生成器里弄生成器不方便的問題。它有兩大主要功能。
第一個功能是:讓巢狀生成器不必通過迴圈迭代yield,而是直接yield from。以下兩種方式是等價的。
def gen_one():
subgen = range(10)
yield from subgen
def gen_two():
subgen = range(10)
for item in subgen:
yield item
複製程式碼第二個功能就是在子生成器和原生成器的呼叫者之間開啟雙向通道,兩者可以直接通訊。
def gen():
yield from subgen()def subgen():
while True:
x = yield
yield x+1def main():
g = gen()
next(g) # 驅動生成器g開始執行到第一個 yield
retval = g.send(1) # 看似向生成器 gen() 傳送資料
print(retval) # 返回2
g.throw(StopIteration) # 看似向gen()拋入異常
複製程式碼通過上述程式碼清晰地理解了yield from的雙向通道功能。關鍵字yield from在gen()內部為subgen()和main()開闢了通訊通道。main()裡可以直接將資料1傳送給subgen(),subgen()也可以將計算後的資料2返回到main()裡,main()裡也可以直接向subgen()拋入異常以終止subgen()。
重構程式碼
首先我們需要將 Future 物件變成一個 iter 物件:
class Future:
"""
未來物件
非同步呼叫執行完的時候,就把結果放在它裡面。
"""
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
def __iter__(self):
# 將Future變成一個iter物件
yield self
return self.result
複製程式碼之後
抽象socket連線的功能:
def connect(sock, address):
f = Future()
sock.setblocking(False)
try:
sock.connect(address)
except BlockingIOError:
pass
def on_connected():
f.set_result(None)
selector.register(sock.fileno(), EVENT_WRITE, on_connected)
yield from f
selector.unregister(sock.fileno())
複製程式碼抽象單次recv()和讀取完整的response功能
def read(sock):
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield from f
selector.unregister(sock.fileno())
return chunk
def read_all(sock):
response = []
chunk = yield from read(sock)
while chunk:
response.append(chunk)
chunk = yield from read(sock)
return b''.join(response)
複製程式碼現在重構Crawler類
class Crawler:
def __init__(self, url):
self.url = url
self.response = b''
def fetch(self):
global stopped
sock = socket.socket()
yield from connect(sock, ('example.com', 80))
get = f'GET {self.url} HTTP/1.0\r\nHost: example.com\r\n\r\n'
sock.send(get.encode('ascii'))
self.response = yield from read_all(sock)
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
複製程式碼在Python 3.3 引入yield from新語法之後,就不再推薦用yield去做協程。全都使用yield from由於其雙向通道的功能,可以讓我們在協程間隨心所欲地傳遞資料。
有了 yield from 這個工具,我們便可以將多個生成器串聯起來。yield from 的意義在於,將這些生成器串聯起來形成一顆樹,並且提供了一種便捷的方法,將這顆樹的葉子節點依次返回。yield from 將多個生成器連線起來的方式,我們可以使用很簡單的方式就可以將所有的 yield 返回值一一提取出來。不斷的對根節點的生成器 進行send 操作即可。
上面的例子介紹了 yield 和 yield from,但是它們和 asyncio 之間有什麼區別和聯絡呢,來看一下 asyncio。
asyncio
asyncio 簡介
asyncio是Python 3.4 試驗性引入的非同步I/O框架(PEP 3156),提供了基於協程做非同步I/O編寫單執行緒併發程式碼的基礎設施。其核心元件有事件迴圈(Event Loop)、協程(Coroutine)、任務(Task)、未來物件(Future)以及其他一些擴充和輔助性質的模組。
在引入asyncio的時候,還提供了一個裝飾器@asyncio.coroutine用於裝飾使用了yield from的函式,以標記其為協程。但並不強制使用這個裝飾器。
雖然發展到 Python 3.4 時有了yield from的加持讓協程更容易了,但是由於協程在Python中發展的歷史包袱所致,很多人仍然弄不明白生成器和協程的聯絡與區別,也弄不明白yield 和 yield from 的區別。這種混亂的狀態也違背Python之禪的一些準則。
於是Python設計者們又快馬加鞭地在 3.5 中新增了async/await語法(PEP 492),對協程有了明確而顯式的支援,稱之為原生協程。async/await 和 yield from這兩種風格的協程底層複用共同的實現,而且相互相容。
在Python 3.6 中asyncio庫“轉正”,不再是實驗性質的,成為標準庫的正式一員。
asyncio重寫爬蟲
用 asyncio 重寫一下之前寫的例子:
import asyncio
import aiohttp
host = 'http://example.com'
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
async def fetch(url):
async with aiohttp.ClientSession(loop=loop) as session:
async with session.get(url) as response:
response = await response.read()
return response
if __name__ == '__main__':
import time
start = time.time()
loop = asyncio.get_event_loop()
tasks = [fetch(host + url) for url in urls_todo]
loop.run_until_complete(asyncio.gather(*tasks))
print(time.time() - start)
複製程式碼上述程式碼執行時間大概為0.36s
對比起之前的,變化很大:
- 沒有了yield 或 yield from,而是async/await
- 沒有了自造的loop(),取而代之的是asyncio.get_event_loop()
- 無需自己在socket上做非同步操作,不用顯式地註冊和登出事件,aiohttp庫已經代勞
- 沒有了顯式的 Future 和 Task,asyncio已封裝
- 更少量的程式碼,更優雅的設計
和同步阻塞版的程式碼對比:
- 非同步化
- 程式碼量相當(引入aiohttp框架後更少)
- 程式碼邏輯同樣簡單,跟同步程式碼一樣的結構、一樣的邏輯
- 接近10倍的效能提升
簡單實現 asyncio
asyncio邏輯梳理
我們將之前的實現非同步的程式碼抽取出來,主要就有 Future, Task, event_loop這三個東西。
from selectors import EVENT_READ, EVENT_WRITE, DefaultSelector
stopped = False
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
def __iter__(self):
yield self
return self.result
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f) #啟用 Task 包裹的生成器
def step(self, future):
try:
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
selector = DefaultSelector()
def loop():
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
複製程式碼這個程式碼當然是不能直接使用的,我們需要改造一下。
asyncio庫裡面的核心也是這三個東西,Future, Task 還有事件迴圈。
在開始之前,我們先使用 asyncio來寫個小demo,根據這個demo來梳理一下asyncio的邏輯。
import asyncio
async def get_html(url):
print("開始獲取HTML")
await asyncio.sleep(2)
print("結束獲取HTML")
if __name__ == "__main__":
loop = asyncio.get_event_loop()
func = get_html("http://www.baidu.com")
task = loop.create_task(func)
loop.run_until_complete(task)
複製程式碼在上述程式碼中,我們構建了一個非同步函式 get_html 來模擬訪問網頁的過程。
在這個程式碼段中,首先執行的就是 get_event_loop 這個函式,這個函式的作用就是獲取一個事件迴圈,不停的迴圈檢測是否有事件準備好,如果檢查到準備好的,就呼叫註冊在事件上的回撥函式,直到 stopped 置位時退出迴圈。 get_event_loop() 會返回一個事件迴圈類的例項,這個類繼承於 BaseEventLoop。
之後執行了 create_task() 這個函式,來看看它都幹嘛了。
在asyncio/base_events.py中找到BaseEventLoop定義,在BaseEventLoop類中有個create_task方法。
這個方法的核心程式碼就只有這倆。
def create_task(self, coro):
task = tasks.Task(coro, loop=self)
return task
複製程式碼就是建立了一個Task的例項,然後將傳入的協程 coro 通過 Task 這個類中的邏輯進行一步一步驅動。
每個 Task 類例項都會包裹一個協程(coro),然後通過函式 step 中的 send 來驅動協程。這個協程經過 future 一步一步驅動起來。
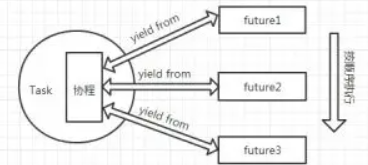
在 Task 類中,初始化例項的時候將協程儲存,然後通過 step 函式來啟動協程。但是這裡的 step 函式和上面我們抽取出來的不太一樣,它多了很多引數檢查和異常處理,然後就是,我們上面抽取出來的 Task 類在 init 的時候,就將整個協程驅動起來,但是在 asyncio 中,它不會馬上呼叫 step 函式,而是在下一幀(下一次迴圈)中呼叫(_loop.call_soon 函式)。
這裡呼叫 call_soon 函式就是將 Task 例項的 _step 函式新增到待執行的佇列中去,這個函式也是定義在 asyncio/base_events.py 的 BaseEventLoop 類中的。
def _call_soon(self, callback, args):
handle = events.Handle(callback, args, self)
if handle._source_traceback:
del handle._source_traceback[-1]
self._ready.append(handle) # 事件新增到佇列
return handle
複製程式碼它返回了一個 Handle 類的例項。這裡的 Handle 類就是包裹了就緒事件的回撥函式的,其中定義了一個run方法,就是直接執行回撥函式,self._ready 儲存著 Handle 類的例項,在 asyncio 中 loop 死迴圈不斷檢測是否有事件就緒,即檢測 self._ready是否有為空,不為空就從其中彈出 Handle 例項,然後呼叫handle例項的run方法,其實就是執行註冊在就緒事件上的回撥函式。一旦有就緒事件,就呼叫其回撥函式。
現在在我們寫的那個小 demo 中,已經通過 task = loop.create_task(func) 建立了一個 task 例項,該 task 例項包裹了我們自己定義的協程 func ,並且 在task 初始化的時候在 __init__ 函式中通過 call_soon 通知下一次迴圈立即執行 task 的_step函式來啟用cora協程。接下來就是run_until_complete函數了。
run_until_complete函式同樣定義在asyncio/base_events.py的BaseEventLoop類中。這個函式中就有 loop 的死迴圈。(節選的程式碼,刪除了部分程式碼)
def run_until_complete(self, future):
future = tasks.ensure_future(future, loop=self) # ensure_future,即,確保是future。返回的是future(task也是future)
future.add_done_callback(_run_until_complete_cb) # 用來結束迴圈
try:
self.run_forever()
except:
if new_task and future.done() and not future.cancelled():
future.exception()
raise
finally:
future.remove_done_callback(_run_until_complete_cb)
if not future.done():
raise RuntimeError('Event loop stopped before Future completed.')
return future.result()
複製程式碼函式首先確保傳遞進來的引數是future,Task 是繼承 Future的,所以 task 也是 future。我們外面傳進來的引數是個task例項,所以這個函式呼叫返回的其實就是本身(傳進去是啥返回就是啥),然後給我們傳進來的task例項通過呼叫add_done_callback新增_run_until_complete_cb回撥函式,這個回撥函式比較關鍵,run_until_complete的做的最重要的事就是給傳進來的task例項新增這個回撥,點進_run_until_complete_cb,可以看到就是呼叫了loop的stop函式,這個的意義就是,當我們傳進來的task包裹的協程執行結束後,就呼叫這個回撥,跳出迴圈(就是相當於我們抽取出來的程式碼中的stopped變數的作用),否則死迴圈就真的是死迴圈了,永遠跳不出。
之後就是真的死迴圈,run forever。
關鍵程式碼
def run_forever(self):try:
events._set_running_loop(self)
while True:
self._run_once()
if self._stopping:
break
finally:
...
複製程式碼這個函式不斷的呼叫_run_once(),就像我們抽取出來的loop函式中不斷地呼叫下面這段程式碼:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
複製程式碼而在 _run_once()中:
else:
event_list = self._selector.select(timeout) # 篩選就緒事件,將其回撥新增到self._ready中
self._process_events(event_list) # 該函式具體實現在selector_events.py中
複製程式碼這裡也就是選出就緒事件,然後新增到self._ready佇列中,隨後執行。在_run_once()的尾部,我們看到如下程式碼:
ntodo = len(self._ready)
for i in range(ntodo):
handle = self._ready.popleft()
if handle._cancelled:
continue
if self._debug:
try:
self._current_handle = handle
t0 = self.time()
handle._run()
dt = self.time() - t0
if dt >= self.slow_callback_duration:
logger.warning('Executing %s took %.3f seconds',
_format_handle(handle), dt)
finally:
self._current_handle = None
else:
handle._run()
handle = None # Needed to break cycles when an exception occurs.
複製程式碼這裡就是呼叫就緒事件的回撥函式的執行。先看_ready佇列中是否有待處理的Handle例項,如果有,那就一個一個執行,handle中的_run()方法就是執行就緒事件的回撥函式。至此,就把我們抽取出來的中的loop()函式的邏輯對應到了asyncio原始碼的迴圈之中。
最後來看看Future
正如我們上面抽取的程式碼中的Future:
def __iter__(self):
yield self
return self.result # 在Task.step中send(result)的時候再次呼叫這個生成器,但是此時會丟擲stopInteration異常,並且把self.result返回
複製程式碼yield的出現使得__iter__函式變成一個生成器,生成器本身就有next方法,所以不需要額外實現。yield from x語句首先呼叫iter(x)獲取一個迭代器(生成器也是迭代器)。
這裡的future和asyncio中的future,結構是一樣的,功能也類似。最後執行起來的時候就是生成器一層巢狀一層。
總結
以上介紹了Python非同步程式設計和自己簡單實現一個asyncio。如果還有不太理解,或者是覺得文章在某些地方還有需要提升的地方,以及有不同觀點的地方,歡迎在下面留言交流,幫助我一起把這篇文章變得更好。
最後
如果你覺得此文對你有一丁點幫助,點個贊。或者可以加入我的開發交流群:1025263163相互學習,我們會有專業的技術答疑解惑
如果你覺得這篇文章對你有點用的話,麻煩請給我們的開源專案點點star:http://github.crmeb.net/u/defu不勝感激 !
PHP學習手冊:http://doc.crmeb.com
技術交流論壇:http://q.crmeb.com
- 遵循Promises/A 規範,深入分析Promise實現細節 | 通過872測試樣例
- 80 行程式碼實現簡易 RxJS
- 前後端分離專案,如何解決跨域問題?
- springboot中攔截並替換token來簡化身份驗證
- 15 行程式碼在 wangEditor v5 使用數學公式
- Java執行緒池必知必會
- EdgeDB 架構簡析
- TS 型別體操:圖解一個複雜高階型別
- 基於babel的埋點工具簡單實現及思考
- 使用craco對cra專案進行構建優化
- Netty核心概念之ChannelHandler&Pipeline&ChannelHandlerContext
- 理解python非同步程式設計與簡單實現asyncio
- Mycat 作為代理服務端的小知識點
- 一文吃透 React Expiration Time
- 前端模組化詳解
- Java必備主流技術流程圖
- 【建議使用】告別if,Java超好用引數校驗工具類
- MySQL模糊查詢再也不用like %了
- Java 8 的Stream流那麼強大,你知道它的原理嗎
- Vue SEO的四種方案