物件儲存篇-SeaweedFS在同程旅行的使用實踐
1. 背景與現狀
Amazon S3 全稱Amazon Simple Storage Service,旨在通過web服務介面提供業界領先的效能、速度、安全性、可伸縮性和資料可用性。該平臺由亞馬遜網路服務(AWS)開發,並於2006年3月14日首次推出,後續S3逐漸演變為物件儲存的標準。
隨著公司的快速發展,公司內對各種圖片、視訊、檔案等這類物件的儲存需求越來越強烈。
目前公司內的接入場景包括,二維碼,景區推薦視訊,圖片,css,js,ML訓練素材等資源,大約10億+檔案數。都是核心的業務場景,如果儲存服務故障,影響的範圍會比較大,比如掃不了入園二維碼,訪問不了圖片等。
由於歷史的原因,現在公司內提供類似儲存的服務有好幾套,包括Ceph s3,FastDfs+Redis(做元資料儲存),公有云 s3代理等,幾套服務都有比較明顯的問題。比如公有云 s3,使用成本相對比較高,而且走外網互動效能得不到保障,比如Ceph,想完全維護好需要投入大量的成本,價效比不是很高,再比如fastdfs+redis,接入不太友好,支援不了主流的S3。所以我們提供了一套新的物件儲存服務來解決以上問題,本文會詳細介紹,我們新的物件儲存服務(OSS)是怎麼做的。
2. 設計目標
整體的設計目標如下:
- 可擴充套件: 至少需要支援到10億+的物件數,並且需要有水平擴充套件的能力
- 高可用: 要做到高可用,至少要有隔離,多租戶,限流,災備/雙活等能力,最核心業務甚至可以做到不同儲存產品的災備。
- 高效能: 需要足夠快,類似ceph rados,後續需要可以作為分散式檔案儲存的儲存底座
- 低成本: 可以用遠低於ceph的成本支撐所有的業務
- 接入簡單: 能夠支援主流物件儲存S3協議的接入
- 無縫升級: 可以在業務無感知的情況下,穩定的、無縫將業務從ceph s3,公有云 s3遷到新oss
3. 系統設計
簡單來說,設計目標可以拆分成2個點:
- 需要一個非常強大的物件儲存oss服務
- 如何在架構層面解決業務無縫切換,儲存無縫升級從而保障業務的穩定性
下面我將從這2點來介紹下我們是怎麼做的
oss技術選型
近些年越來越火的開源+商業化的模式讓每個方向都或多或少出現了一些比較好的開源產品,比如時序儲存方向的TDengine,OLAP方向的ClickHouse等等,在物件儲存選型的時候,我們也優先考慮開源產品,通過開源共建的方式來完成我們的產品,儘量不從0開始造輪子。 整個社群看下來,相對比較熱門的有minio,SeaweedFS,fastdfs,ceph。其中ceph跟fastdfs不在考慮範圍內,所以精力就放在minio跟SeaweedFS上,看是否能滿足要求。
minio
minio應該是目前最火的開源的物件儲存,github 3w4的star數。
minio的優點包括:
- 友好的UI
- 部署比較簡單,很容易上手
- 支援檔案級別的自愈,在節點故障時無需人工干預
- 全EC儲存,成本相對比較低
- 中大檔案效能比較好
- 基於檔案系統設計,無需額外的儲存來儲存元資料
同樣minio的缺點也相對明顯
- 僅支援EC,會存在io放大的問題,特別是在大量小檔案的場景下
- 擴容不太友好,對等擴容時需要全叢集停止服務
- 支援的檔案數量有限,基於本地檔案系統設計,在物件數變多以後,inode的查詢都會變得很耗時
minio是一款有明顯優缺點的產品,在我們的需求背景下,minio不能夠很好的滿足,特別是不能夠支援我們10億+物件儲存需求,而且在現有的架構設計下,也不太好改造,然後通過與社群共建的方式來滿足我們海量小檔案的需求。
SeaweedFS
越來越火的物件儲存開源方案,github star數1w5+,且增長速度比較喜人,社群也比較活躍。
SeaweedFS官方介紹的核心點有2個
- to store billions of files!
- to serve the files fast!
跟我們的部分核心目標比較貼近
核心優點包括:
- 效能比較強大: 核心理論依據是基於 Facebook's Haystack design paper,該paper的目標也是解決facebook內部圖片視訊等資料的儲存查詢問題
- 架構設計比較靈活: 系統設計參照了Facebook’s Tectonic Filesystem,特別是幾個核心元件的設計,抽象的比較好,非常方便擴充套件不同的實現,並且整體架構上可以水平擴容,沒有明顯的瓶頸點
- 功能齊全: 儲存比較關心的冷熱分離,EC儲存,TTL等功能都有支援
- 部署簡單: 部署非常簡單,很容易上手
相比於優點,也會有些不足
- S3的適配不完全: 實現了大部分的常用介面,部分非常用介面未實現,比如Canned ACL等。
- 專案背景: 相比於minio等開源產品後面都是強大的商業化公司,該專案核心的作者只有 chrislusf 大神
從各個維度來看,基於SeaweedFS開源共建的方式來打造我們的物件儲存服務是目前比較合理的方案。
系統架構
架構介紹
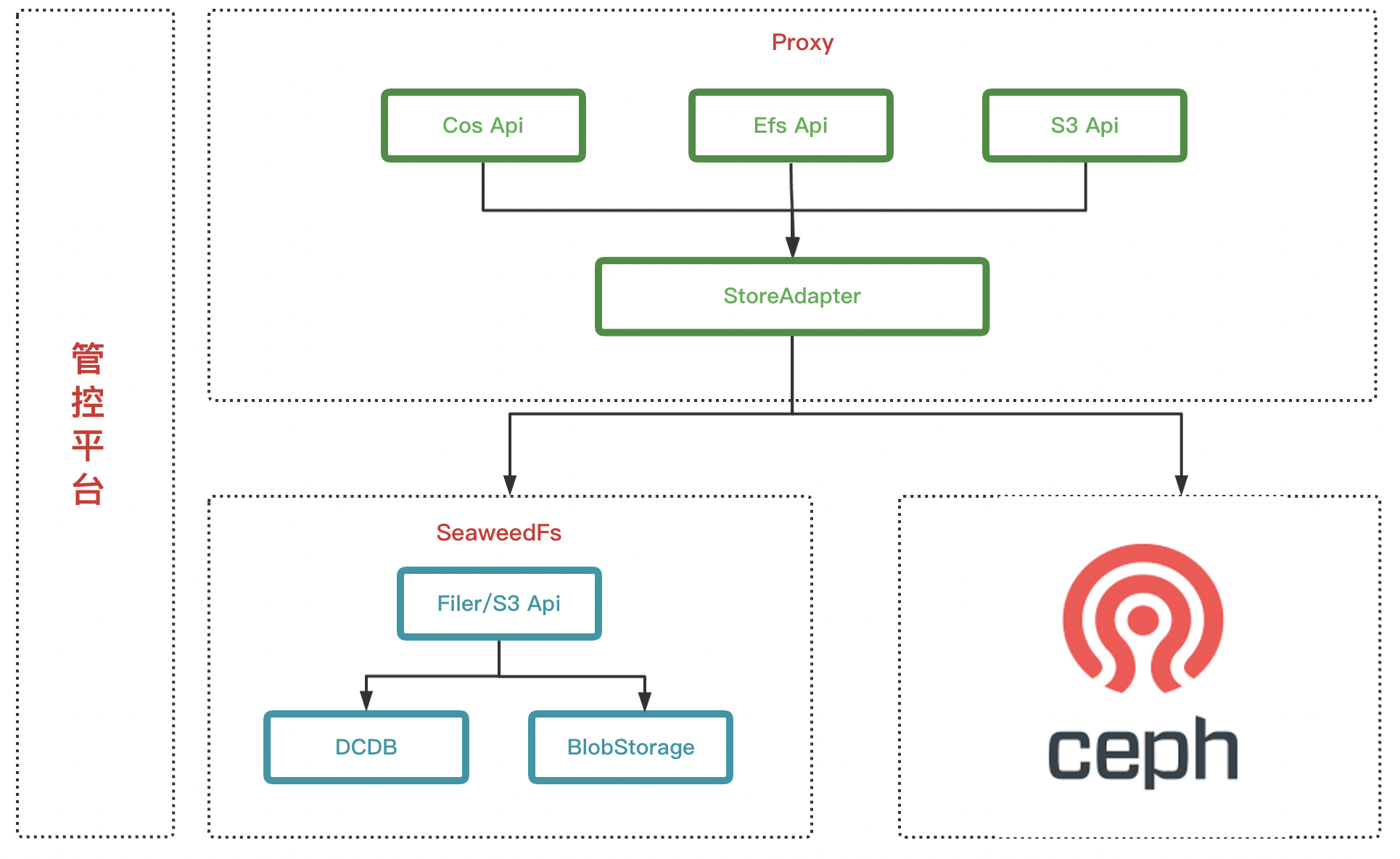
確定選型SeaweedFS後,下一步就是怎麼來設計整體服務來滿足我們的需求,簡易架構如下
 )
)
整體架構其實是一個比較常見的架構,非常簡單
- Proxy層: 來適配不同的Api以及對業務做儲存適配
- 儲存層: 包括SeaweedFS,Ceph s3,公有云 s3. 公有云 s3的操作跟Ceph s3類似,本文就不展開了
- 管控平臺: 視覺化UI,做許可權配置,配額配置,資料列表等
名詞解釋
- 公有云 s3 Api: 公司內部之前封裝的公有云 s3對外的Api
- Efs Api: 公司內部之前封裝的對外的靜態資源相關的Api
- S3 Api: 適配了S3的所有Api
- StoreAdapter: 來根據配置來處理業務的請求,選擇儲存適配
- Filer/s3 Api: SeaweedFS用來對外暴露s3等相關Api的服務
- DCDB: 公司基於BaiKalDB共建的分散式資料庫,下文會詳細介紹
- BlobStorage: SeaweedFS中用來實際做物件儲存的模組
設計目標詳解
可擴充套件
目標: 至少需要支援到10億+的物件數,並且需要有水平擴充套件的能力
proxy是無狀態的,可以做到水平擴充套件,所以只需要SeaweedFS做到可以水平擴充套件就可以滿足我們的需求了。
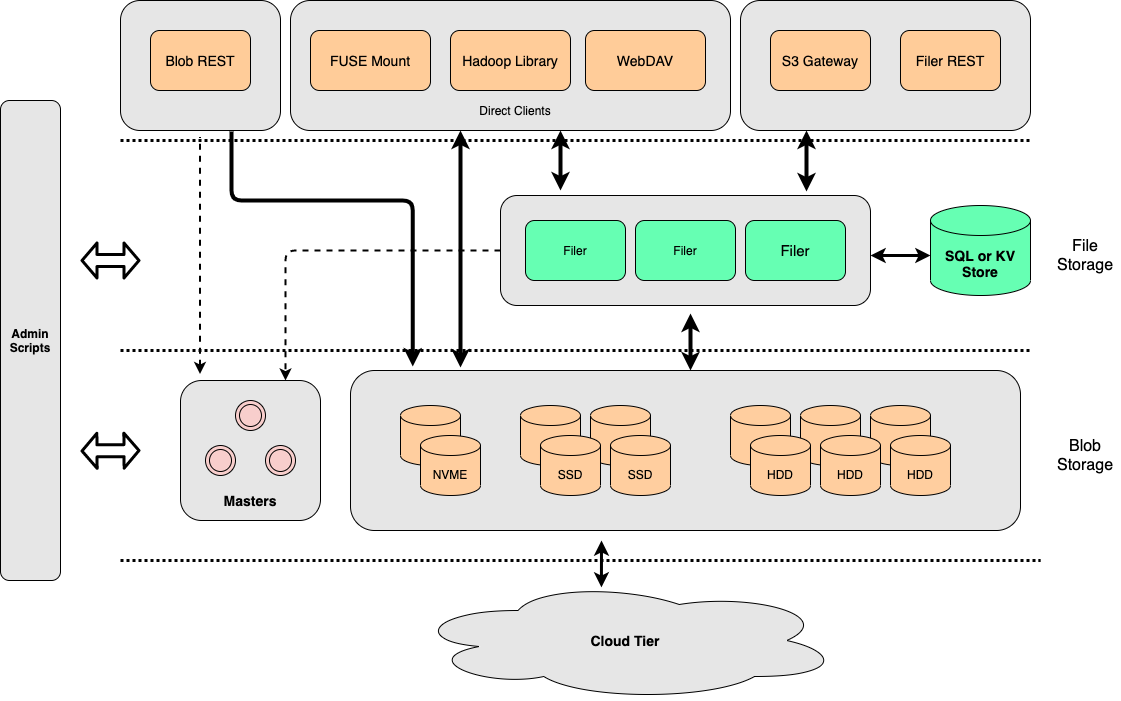
從整體架構上來看,SeaweedFS核心的有2層(S3儲存最核心的基本都是這2塊)
- File Storage: 用來做metadata元資訊的儲存以及做api的適配
- Blob Storage: 物件儲存的底座
metadata的能力是比較核心的一個環節,他至少需要做到:水平擴充套件能力,不丟資料,讀寫效能比較好,高可用。 類似的服務有:Cassandra,Tidb,YDB,toctonics用的ZippyDB等等。基於我們公司現狀,我們選擇了跟BaiKalDB共建的分散式資料庫DCDB. 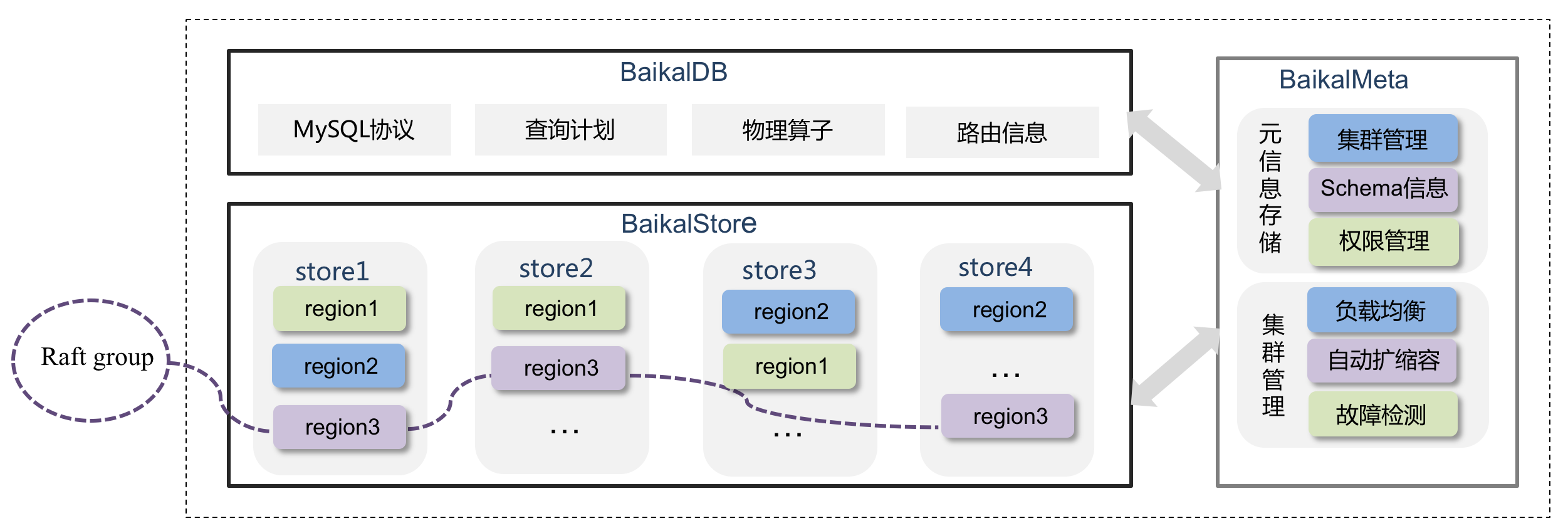
DCDB在我們公司使用的比較多,效能得到了很好的驗證,並且能夠很好的匹配我們的訴求。在引入DCDB做元資料服務後,測試下來讀寫請求的平均耗時在1ms內,能夠滿足我們的需求。 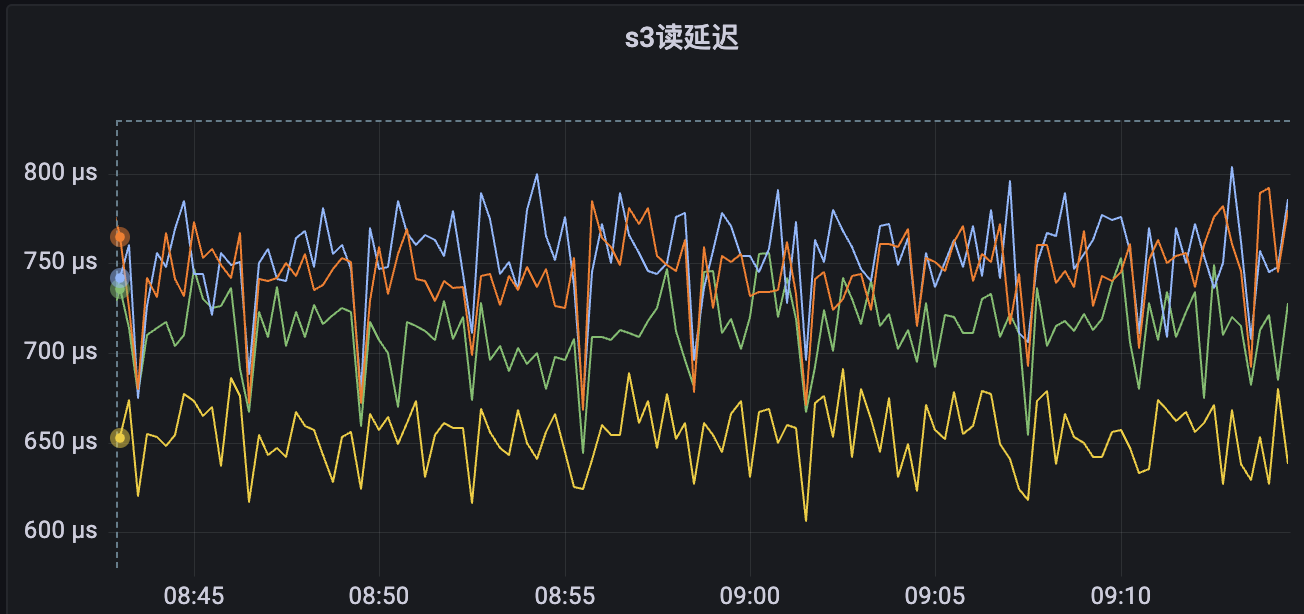
以上是dcdb真實使用下來的監控資料,因為可以水平擴容,我們壓測結果為即使資料量級到了幾十億,也沒有出現效能瓶頸。
有了DCDB的加持,比如整個讀流程就會非常的簡單,從DCDB獲取元資訊,返回資料對應的儲存節點,直接跟儲存節點互動獲取資料,儲存節點之間是沒有直接關係的,可以做到水平擴充套件。 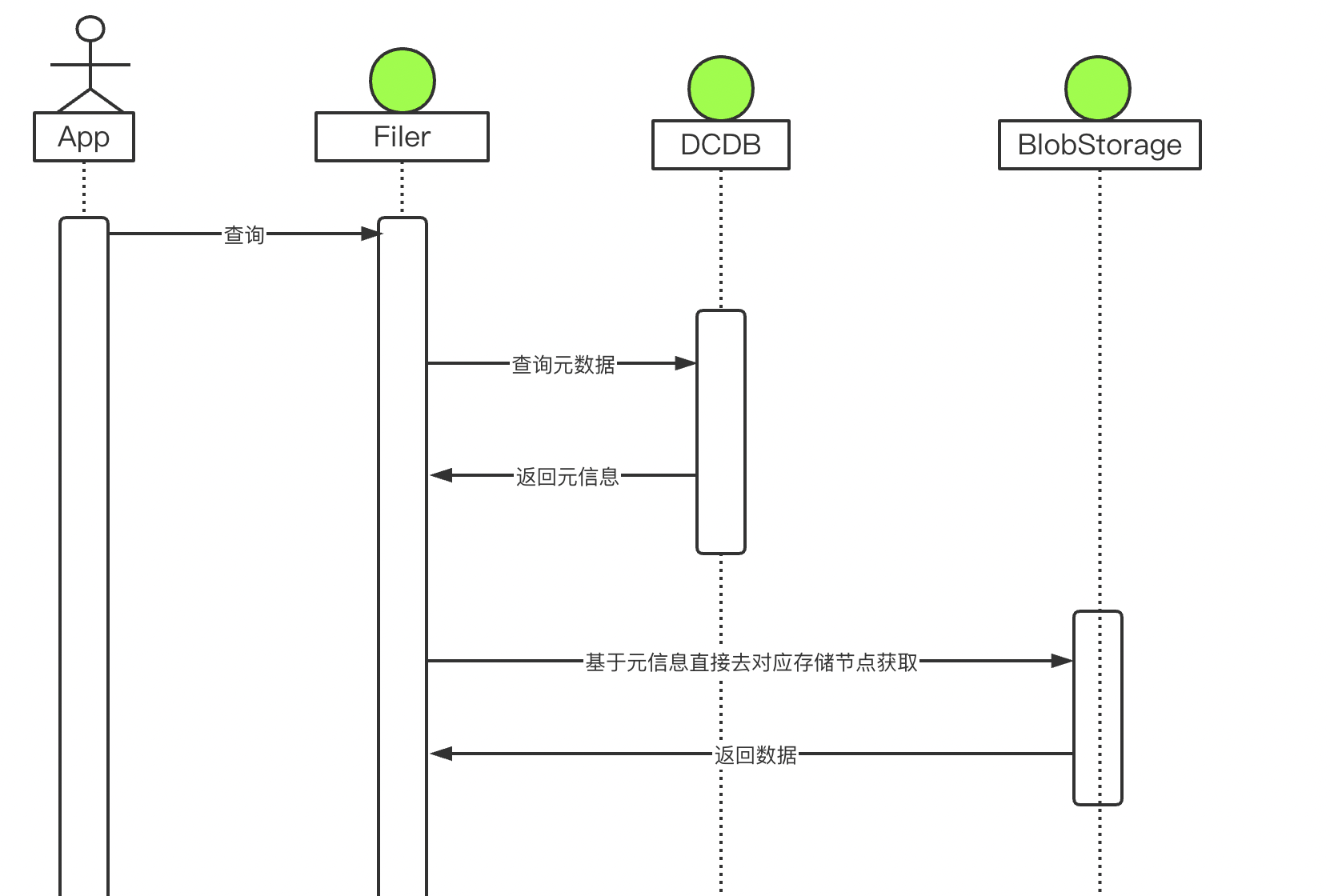
整體看下來,現在整個叢集內沒有明顯的瓶頸點,所有的元件都可以做到水平擴容,可以很好的滿足我們對規模的要求。
高可用
需要做到高可用至少需要保障在單點故障(物理機故障等),預期外流量衝擊,甚至單idc故障時服務要可用,以及要做到多租戶之間相互隔離。下面分別介紹下這幾種場景是怎麼做的
- 隔離
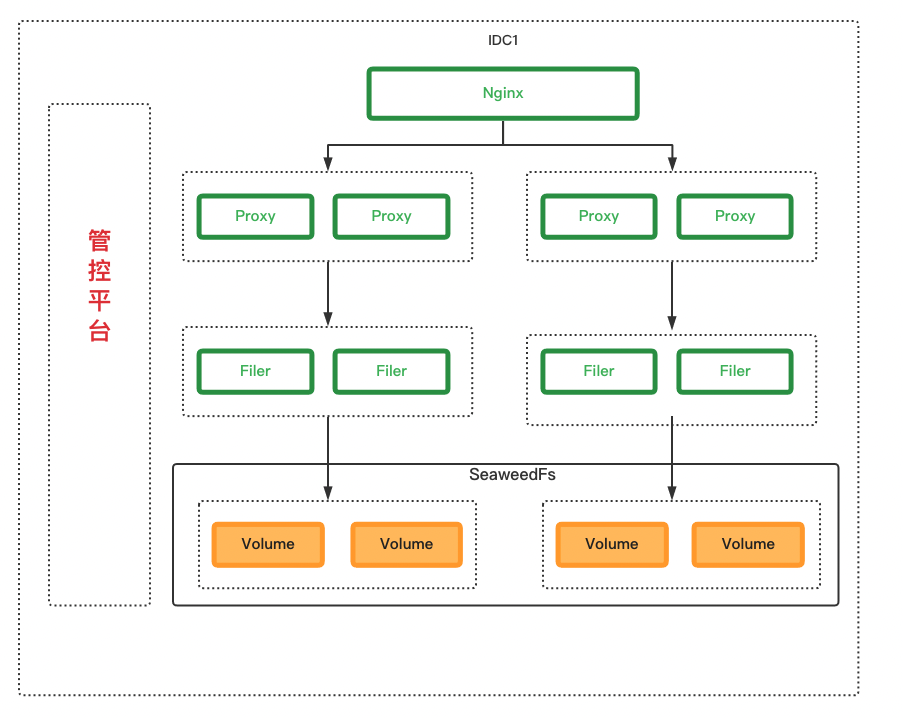
業務隔離,我們做到了在nginx上做分流,不同的業務(bucket)使用不同的proxy,filer,volumeServer。做到了業務與業務之間物理隔離,相互不影響。
- 租戶與限流
除了物理隔離外,還需要至少做到業務級別的限流熔斷功能。物件儲存跟其它的大資料服務有個比較大的區別是流量特別大,比如併發上傳1M的檔案,很輕鬆就可以將流量打到幾十上百GB,會造成網路上面的瓶頸,所以我們要做到可以給業務配置閾值,做到當某個業務有預期外的流量時,可以單獨限制不能影響到整體服務,甚至造成網路故障。
關於租戶的限流我們pr了2個策略,一個是基於bucket級別的全域性流量限制,一種是可以基於 count+單檔案下載限速的流量控制可以比較好的使得整個叢集可控。
- 高可用
proxy,filer,dcdb上文都介紹了,可以做到高可用,現在介紹一下資料是怎麼做高可用的。資料高可用正常會有2種方式:多副本與EC糾刪碼
SeaweedFS支援實時寫資料使用副本方式,後期可以轉換為EC. 都是可以做到資料高可用的。
高效能
SeaweedFS官方介紹的其中一個特點是:to serve the files fast!
核心實現思路是參照Facebook's Haystack design paper,論文裡面介紹的比較詳細。
工程實踐後最終效果做到了,小檔案合併後的順序寫以及O(1)的硬碟讀. 下圖是我們6臺256G,12*8TB SATA盤,壓測的是1M的寫,io優先到了瓶頸點。寫入3000 TPS 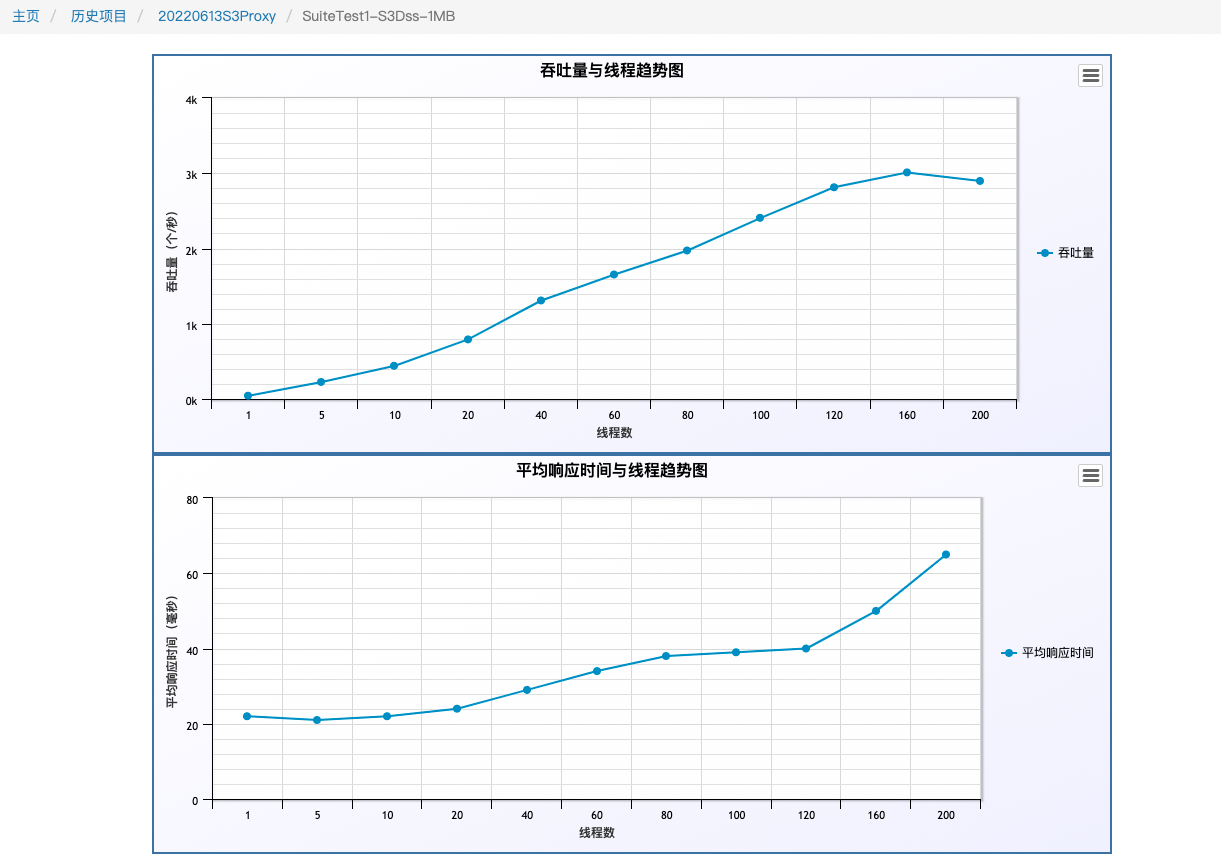
下圖是我們6臺256G,10TB SSD盤,壓測的是1M的寫,因為頻寬限制,沒有繼續壓,各個指標遠沒有到達瓶頸。 寫入4000 TPS 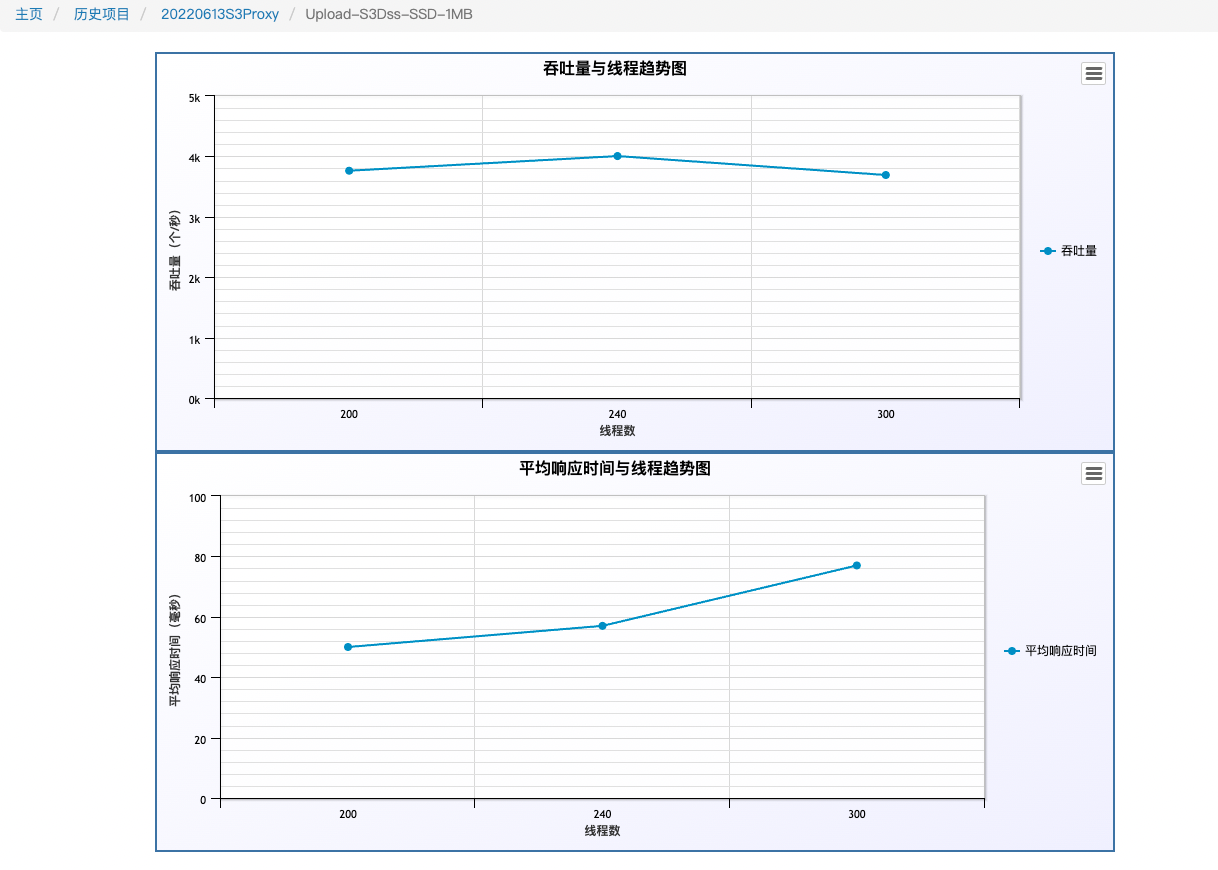
在寫入,查詢,刪除混合場景(6:3:1)壓測下,1M的檔案 3500+ QPS 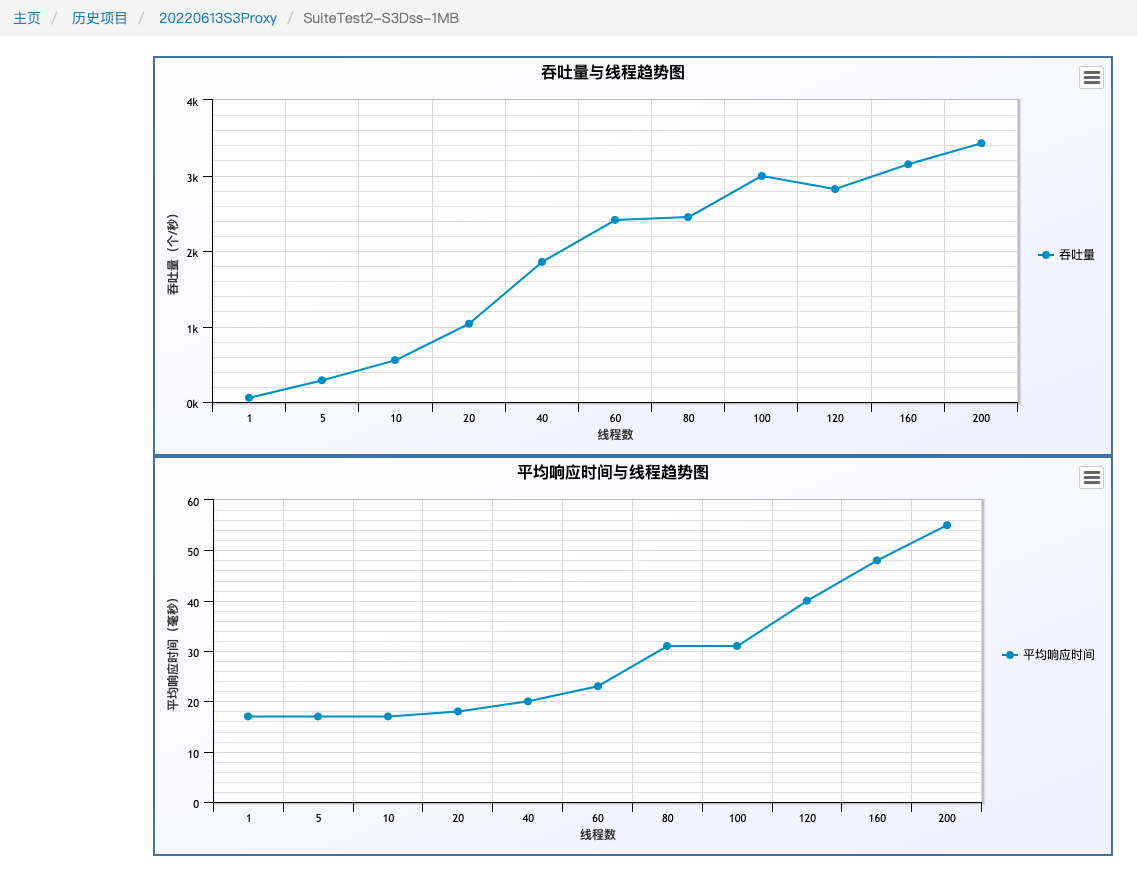
以上結果僅用了6臺機器測試,效能結果達到我們的需求,後期如果有更高的需求,可以做水平擴充套件。
低成本

物件儲存最大的成本會是在儲存上,資料量會非常大,幾百TB,PB甚至EB都是可能的。如上圖,各種雲廠商也提供了不同儲存的不同的計費,簡單來說,就是冷的資料可以犧牲一部分效能來降低儲存的成本。同樣SeaweedFS也做了類似的功能。
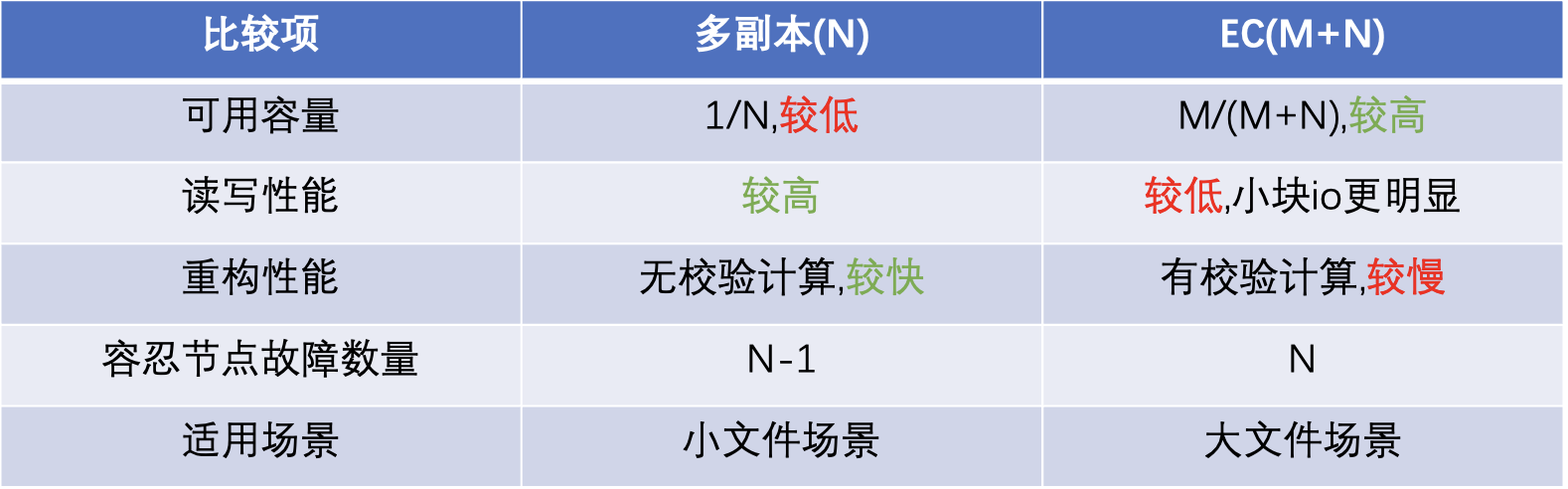
補充個小知識點:多備份與EC的差異,可以清楚的看到成本角度,EC比多副本更有優勢。
現在我們可選的儲存介質包括NVME,SATA SSD,HDD。可選的資料儲存方式有多副本,EC。  如圖,隨著資料越來越冷,我們會慢慢從SSD遷移到HDD,以及從副本方式改為EC儲存。做了效能與成本的取捨。
如圖,隨著資料越來越冷,我們會慢慢從SSD遷移到HDD,以及從副本方式改為EC儲存。做了效能與成本的取捨。
無縫升級
上面介紹了SeaweedFS的一些功能,下面介紹一下我們是如何讓業務無縫從ceph s3,公有云 s3,efs api等儲存切到新的平臺來。 目前場景以ceph為例:
流程適配
業務直接通過S3對ceph進行操作。我們要做的就是偷樑換柱,在業務無感知的情況下,將ceph s3替換為更高可用的SeaweedFS。大概需要做幾個事情
- 全api的適配
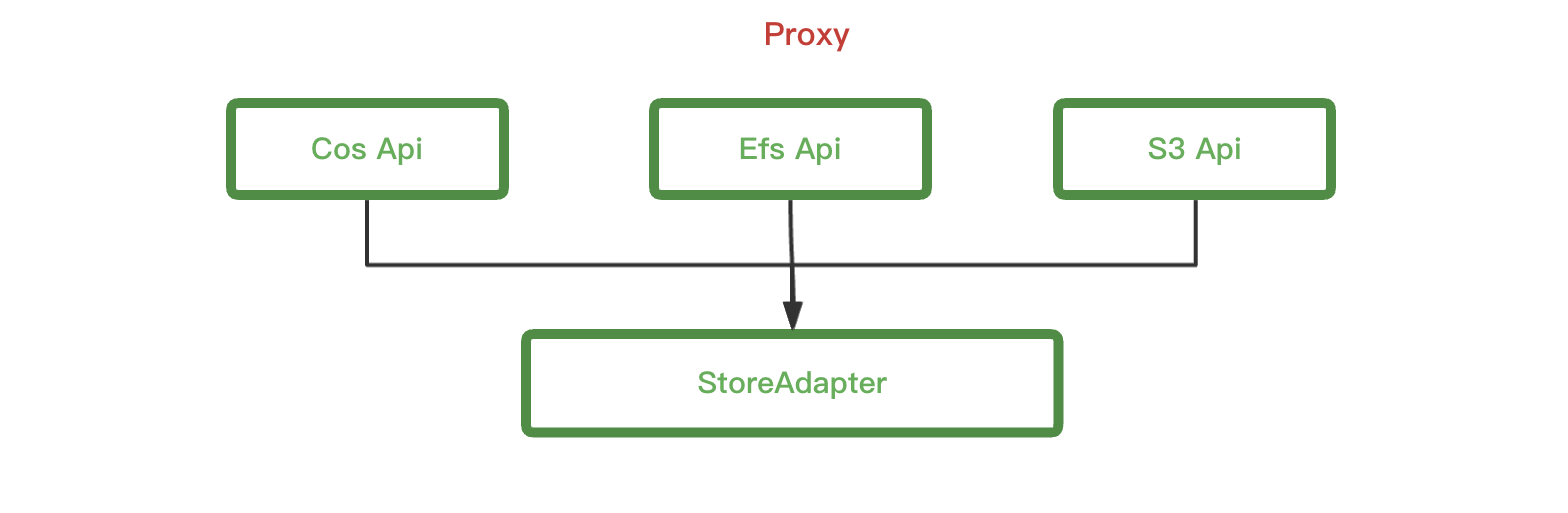 proxy適配了我們原先所有對外的api,包括s3 api,公有云 s3 api,efs api,所有api解析完內部操作完全一致了,這樣可以做到只需要域名解析調整到proxy就可以了。
proxy適配了我們原先所有對外的api,包括s3 api,公有云 s3 api,efs api,所有api解析完內部操作完全一致了,這樣可以做到只需要域名解析調整到proxy就可以了。
- 讀流程的適配
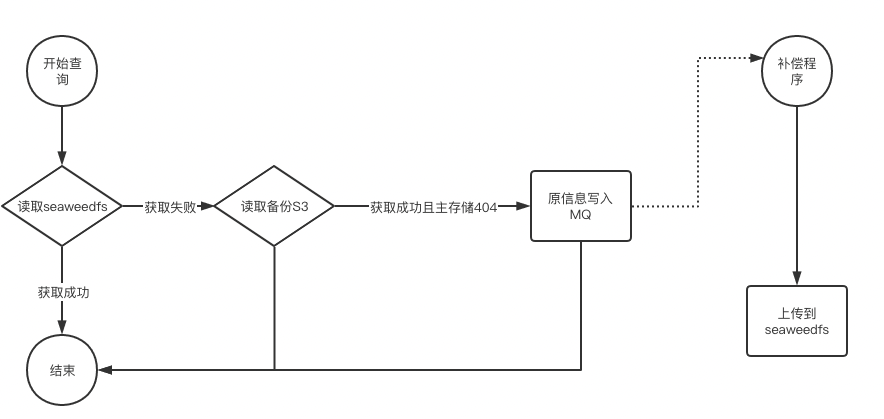
因為歷史的原因,現在ceph s3以及公有云 s3裡面存在了大量的不再使用的資料幾百TB,這些資料是不需要匯入到新儲存的,如上圖,我們proxy支援了一種策略s3 -> S3的策略。主要特點有2個:
- 儲存級別的高可用:新儲存故障自動切到備儲存,做到儲存級別的高可用
- 自動資料補齊:新儲存無資料,備儲存有資料,自動將該資料的元資訊寫入MQ
同時我們還有一個補償的程式來讀取MQ中的資料,自動將被儲存的資料補償到新儲存,這樣可以做到一段時間後,所有熱資料(有訪問的資料)自動備份到新儲存了,ceph s3/公有云 s3可以下線。
注: 寫MQ的時候需要注意,需要按照檔案級別做順序寫入,防止資料有問題
- 寫流程的適配
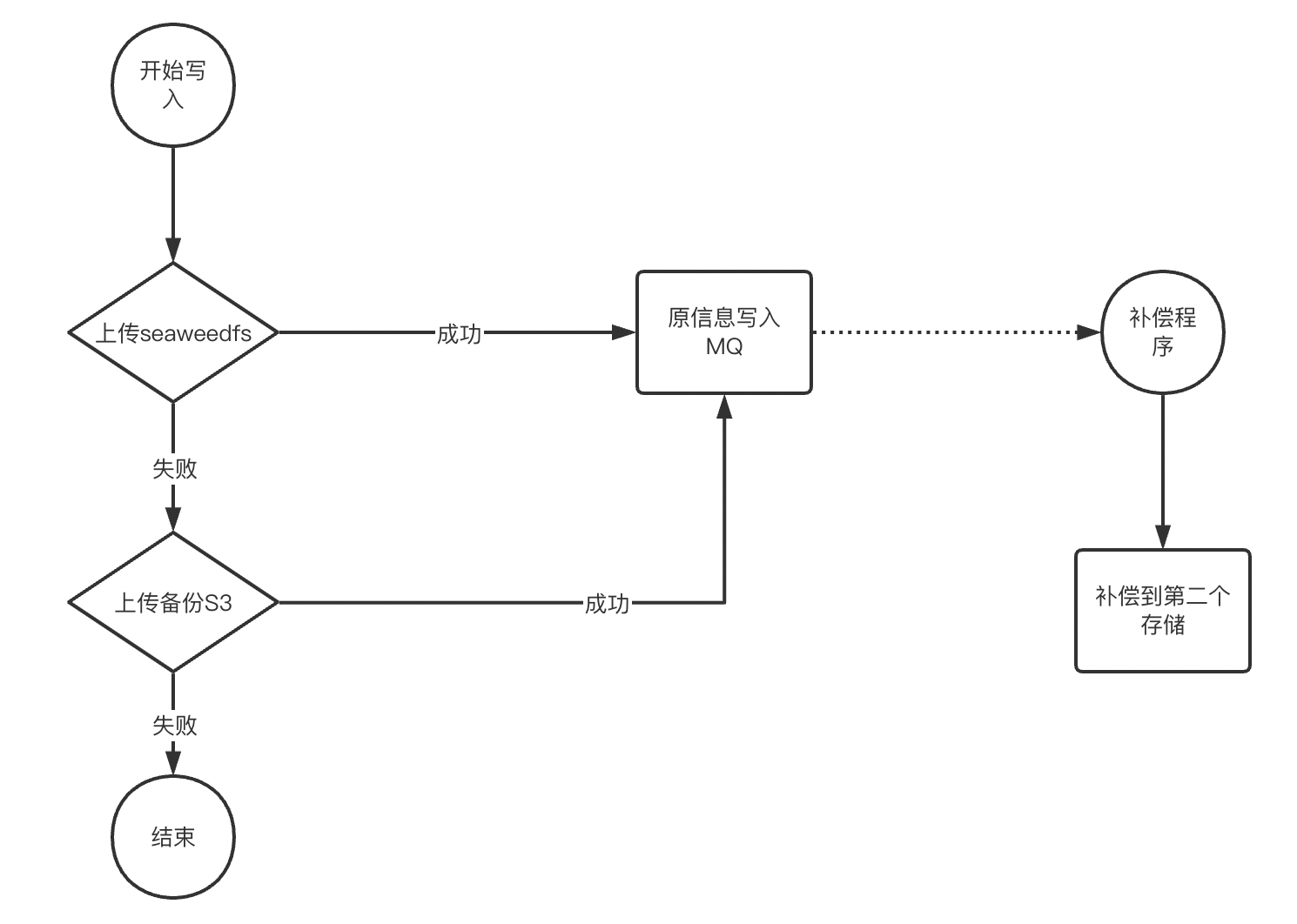
寫入做了取捨,為了提升效能,寫入只需要一個儲存寫成功就響應給業務,第二個儲存的資料由補償程式來完成。該流程可以做到任意儲存故障時,業務都無感知。
proxy中所有操作都是S3的標準介面操作,所以可以輕易做到SeaweedFS與ceph s3,SeaweedFS與公有云 s3,SeaweedFS與SeaweedFS的多種災備方案。比如最核心的業務場景二維碼,景區圖片等,我們會先執行一陣SeaweedFS與公有云 s3的自動災備,防止某種場景下觸發了某個儲存的bug,而造成大面積的影響
寫入MQ的資料還有一個用途,用來做雙儲存的資料校驗,保障2個叢集的資料最終一致性。
注:
- 圖中預設寫入MQ是成功的,實際proxy中有兜底策略,寫MQ失敗有另外的兜底策略,比較複雜,這裡不做闡述
- 以上介紹了2個核心場景流程,還有部分場景稍有區別,如list api等
升級步驟
除了理論上的無縫外,為了穩定的執行上線,上線流程也比較講究,我們大概會分幾步
-
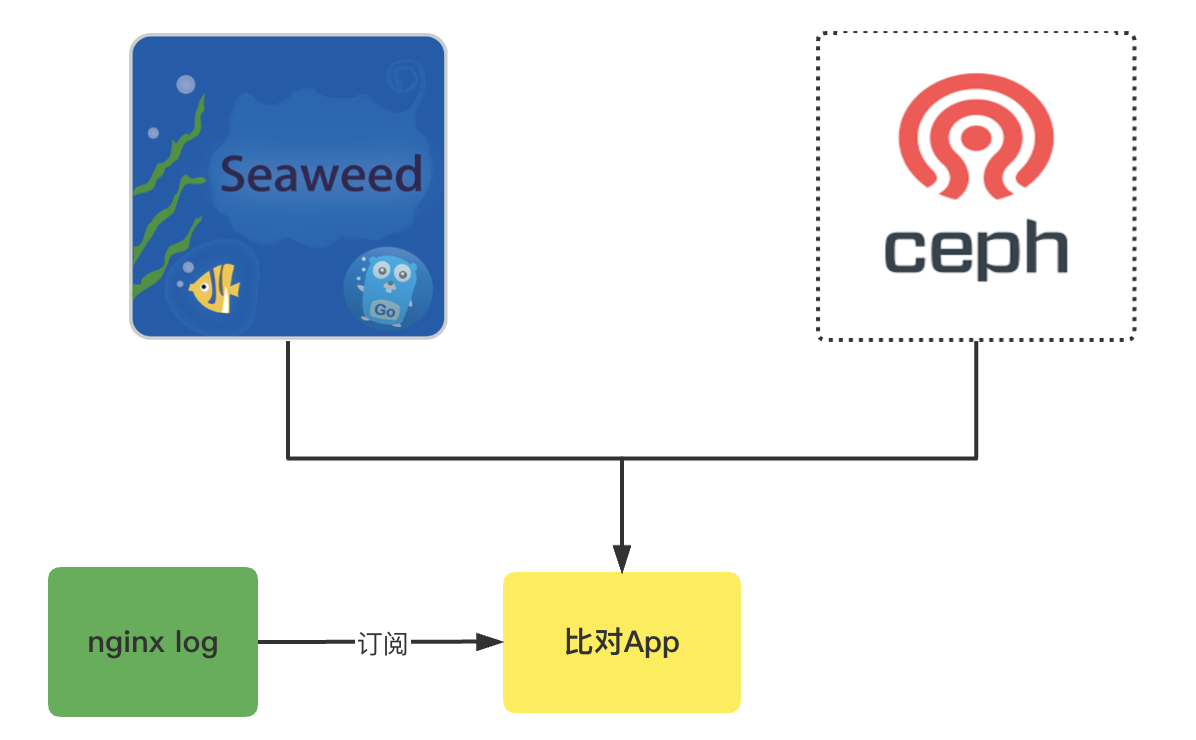
資料比對: 拿s3 api為例,切換之前我們會有個比對程式,訂閱nginx的訪問日誌,來做2個儲存的結果比對,核心比對結果主要包括檔案的MD5,以及響應的header頭
-
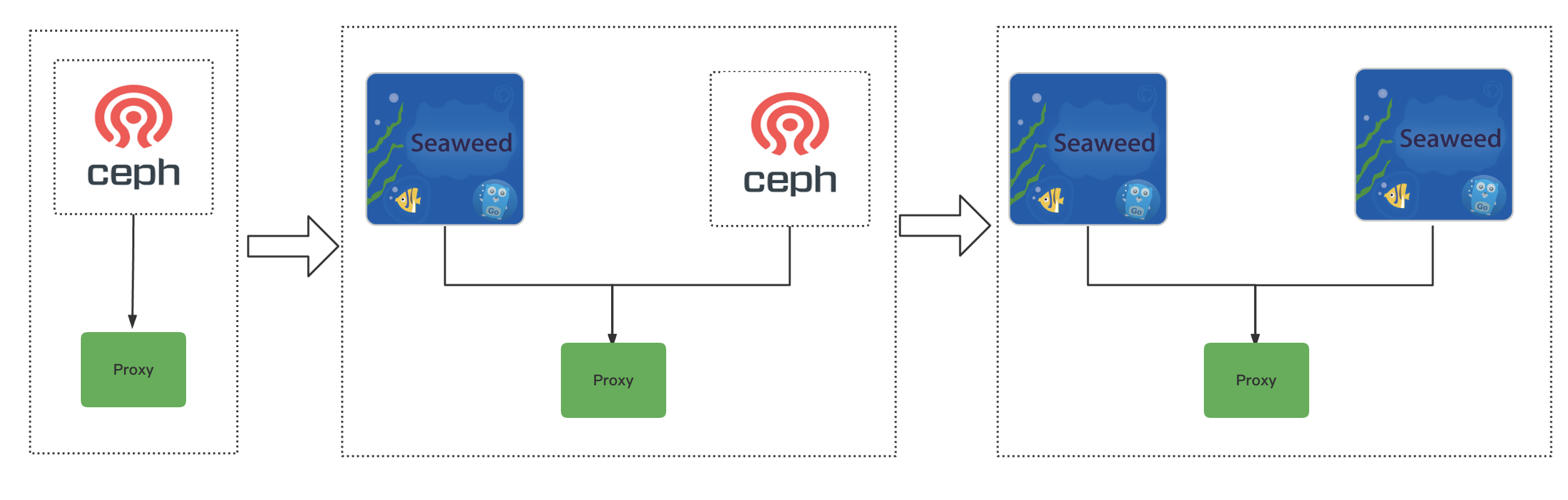
策略調整: 因為業務比較核心,為了穩定的推進,每次只做最小化變更,推進過程分了3步: 1: 引入代理,保障代理功能正常 2: 引入SeaweedFS為主,做成SeaweedFS與ceph的雙叢集備份,這樣可以做到即使SeaweedFS有問題,我們也可以快速的將流量回滾到ceph 3:下線ceph,最終形態,做成SeaweedFS的雙叢集備份
4. 落地收益
得益於開源的好處,我們僅僅投入了2個人力,整個迭代從選型到原始碼、原理研究到開始落地大概持續了3個月,該專案上線已經運行了接近3個月,執行良好,達到了預期的期望效果。 目前已接入 接近2000w物件,60TB的資料量,還在快速流量切換中。 
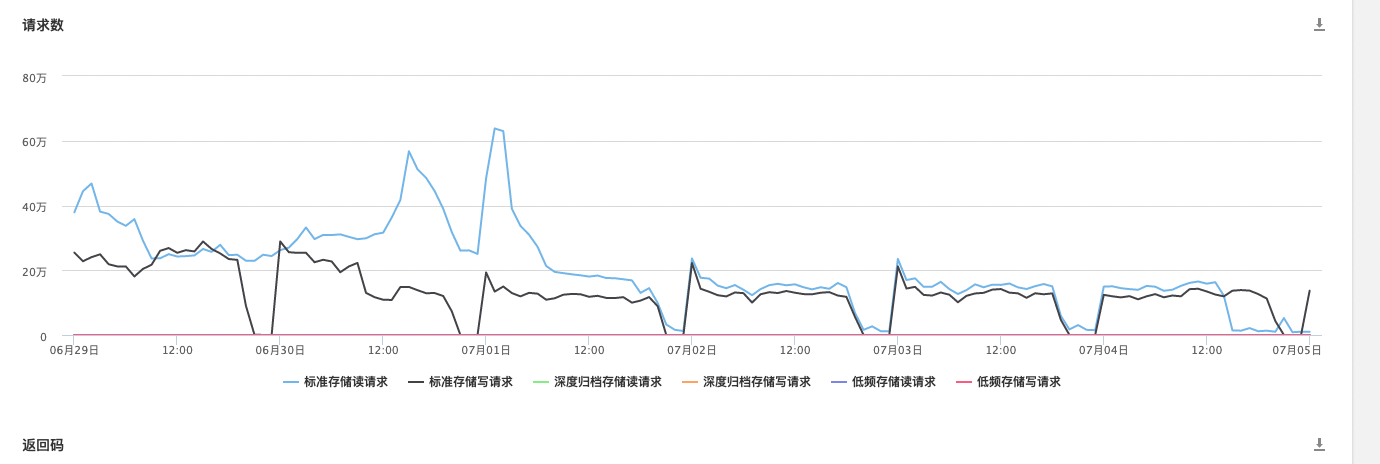
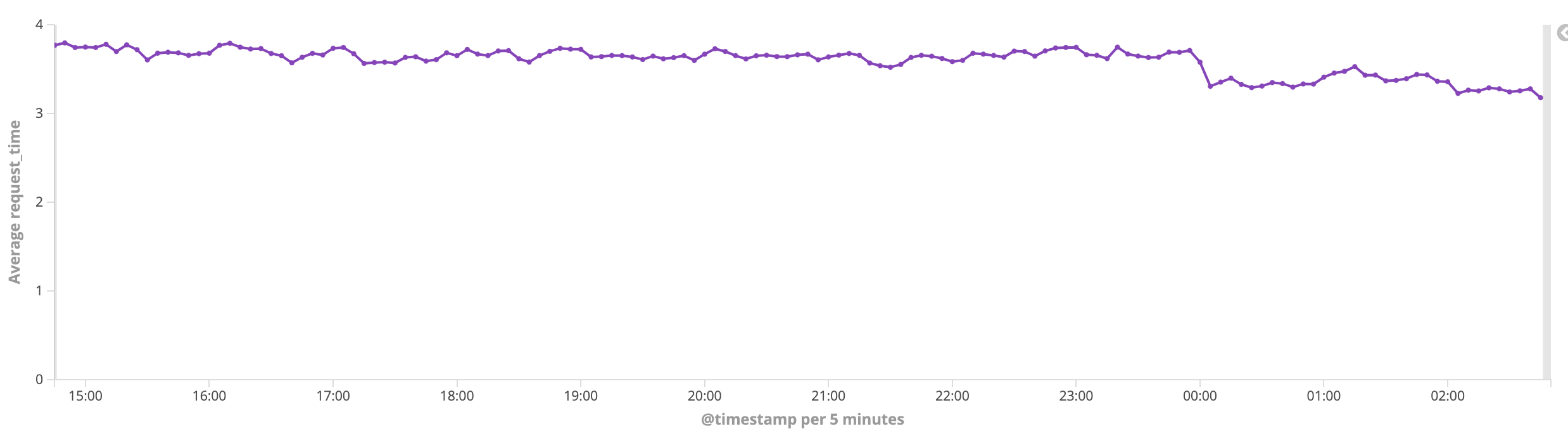 以核心業務efs為例,之前儲存使用的是公有云 s3,現在切換到了第二步(SeaweedFS為主叢集,公有云 s3為備用叢集)。切換後的收益
以核心業務efs為例,之前儲存使用的是公有云 s3,現在切換到了第二步(SeaweedFS為主叢集,公有云 s3為備用叢集)。切換後的收益
- 效能: 響應耗時有了質的提升,從150ms下降到3ms。
- 穩定性: 之前訪問公有云 s3走的是公網,效能波動比較大,切換後耗時變得非常平穩。
- 成本: 目前到了第二步,公有云 s3還剩下了寫入的流量,讀的流量基本清0了,成本也下降了很多
5. 使用tips
- volumeGrowthCount: 這個需要調整,要做到儘量所有volumeServer都有writeable的volume,否則寫入,查詢效能會有影響
- fs.configure: SeaweedFS的設計是每個bucket都對應一個collection,這樣可以方便的做生命週期管理,需要控制bucket數量,否則效能會影響比較大。我們內部先改版了取消這個繫結,做到效能最優,不過犧牲了一些bucket的統計功能,完整功能還在優化中
- filer.sync: 沒有proxy的情況下,可以使用filer.sync的同步工作來做雙叢集災備
6. 未來展望
定期備份: 核心bucket的增量、全量定期備份,做到跟db類似的效果,可以做到萬一誤刪等問題也可以回滾
開源共建: 到目前為止,我們也陸陸續續大大小小提交了20+pr,包括bug fix,效能功能優化,後續會持續的關注社群,跟社群一起成長。
基於S3的存計分離方案: 現在很多主流的儲存產品都適配了S3,比如prometheus,clickhouse等等。因為新oss的強大的效能,我們會在這些適配S3的儲存上面試點儲存與計算分離
分散式檔案儲存: 類似ceph,可以基於物件儲存rados打造分散式檔案儲存,以及現在比較火的juicefs或curvefs也是基於s3構建的。後期也計劃基於該oss實現分散式檔案儲存,一期目標在除了對io latency要求非常高(mysql)的場景外落地,為業務賦能。