字節一面:Redis主節點宕機,如何處理?
今天跟大家聊下,如果Redis某個節點宕機了,要怎麼處理?
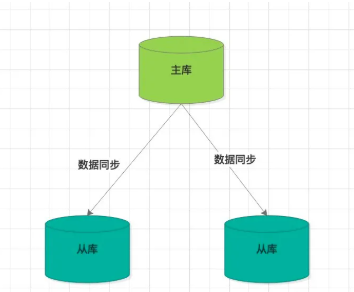
我們知道,Redis集羣一般採用主從模式,主節點負責寫,從節點負責讀。
從節點故障
從節點主要提供讀服務,為了分攤主服務器壓力,一般會有多個從節點。
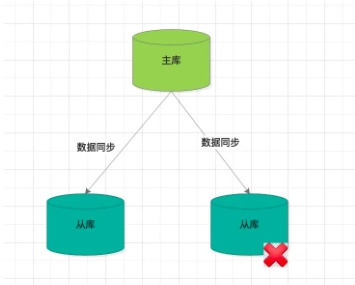
如果是從節點故障,不算什麼大問題,客户端把該故障節點屏蔽即可,仍可訪問其他的主、從節點滿足正常的業務功能。
主節點故障
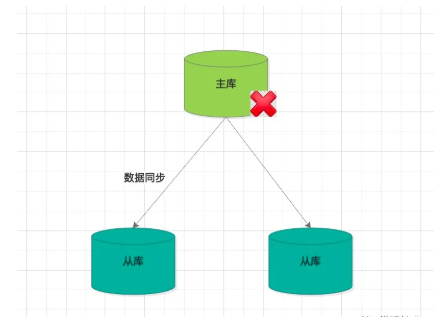
如果是主節點宕機了,那就有點麻煩了,畢竟寫操作是在主節點上,無法替代。
這時候,我們要幹一件事,從所有的從庫節點中挑選一台做為主節點。這裏要介紹下Sentienl 哨兵機制了。
哨兵機制分為三個階段:
1、監控。哨兵進程會週期給所有的主庫、從庫發送 PING 命令,檢測機器是否處於服務狀態。如果沒有在設置時間內收到回覆,則判定為下線。
2、選主。主要是看各個節點的打分情況,打分規則分為 從庫優先級、從庫複製進度、從庫ID號。只要有一輪,某個從庫得分最高,則選舉它為主庫。
從庫優先級,主要是考慮到不同的機器可能配置不一樣,配置高的機器,優先級高一些,通過slave-priority 來配置
從庫複製進度,主要是看slave_repl_offset 的值大小,值越大表示已經同步的數據越多,得分越高。
從庫ID號,每個Redis 實例啟動時,都會生成一個 ID,在優先級和複製進度相同的條件下,ID號最小的從庫分數最高,會被選為新主庫。
3、通知。把選舉後的新主庫發送給所有節點,讓所有的從庫執行 replicaof 命令,和新 master建立主從關係、數據同步複製。另外,也會把最新的主庫信息同步給客户端。這樣後續的寫請求會打到新的 主節點上。
我們知道網絡存在不穩定性,所以會不會有什麼特殊問題?我們繼續往下看
網絡抖動,引發誤判
問題描述:
哨兵節點監控到主節點超時未響應,主節點不一定是真的宕機。可能是之間的網絡擁堵,或者主庫自身壓力過大,導致響應超時。
如何避免這種情況?
引入哨兵集羣,多個哨兵實例一起判斷,降低誤判率。判斷標準就是,假如 n 個哨兵實例,至少有 n/2+1 個判定一致,才可以定論。
注意:
上面的誤判只會用在主庫,從庫只是負責讀,如果監測到未響應,直接標記為 ”下線“,並不需要集羣投票驗證其真實性。
如果是主庫超時未響應,則不能這麼草率決定,畢竟後面的選主和通知都是一筆不小的開銷,所以,標記主庫”下線“,一定要慎之又慎。
那麼,哨兵集羣集如何投票,確認主節點是否真的下線呢?在深入這個問題之前,我們先來了解下哨兵集羣
哨兵集羣如何構建?
首先,在redis-sentinel 的conf文件裏添加兩個配置項:
sentinel monitor
master-name:對某個master+slave 組合的一個區分標識(一套sentinel是可以監聽多套master+slave這樣的組合)
ip 和 port:就是master節點的 ip 和 端口號。
quorum:進行客觀下線的一個依據,意思是至少有 quorum 個sentinel主觀的認為這個master有故障,才會對這個master下線或故障轉移。
sentinel down-after-milliseconds
timeout:毫秒值,如果這台sentinel超過timeout時間無法連通master或slave(slave不需要客觀下線,因為不需要故障轉移),就會主觀認為該master已經下線(實際下線需要客觀下線的判斷通過才會真正下線)
藉助發佈/訂閲組建哨兵集羣
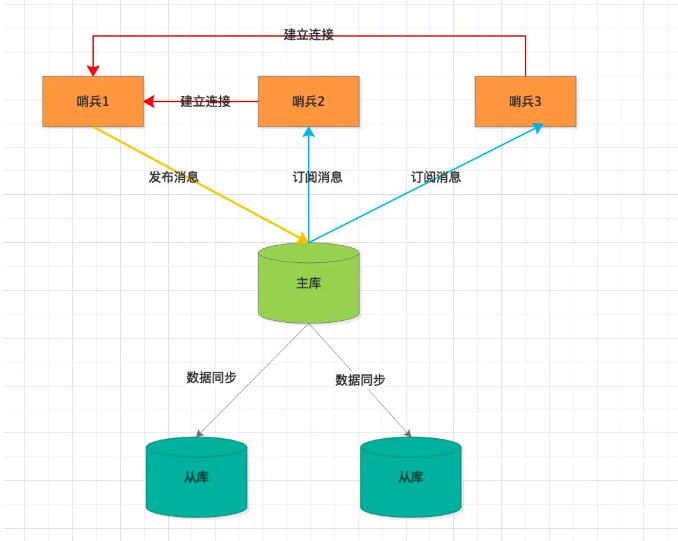
我們知道Redis 有pub/sub 機制,當一個哨兵與主庫建立連接,可以在主庫上發佈自己的消息(ip、port),當然也可以在主庫上訂閲其他哨兵發佈的消息。
有點類似MQ的topic味道,大家基於同一個topic完成數據交換。
當所有的哨兵都完成上述動作,哨兵集羣也就組建完成。
為什麼要組建哨兵集羣呢?因為後面的選主需要有一個leader帶頭操作。
哨兵如何知道所有從庫地址呢?
我們知道每個哨兵實例的配置參數裏有配置主庫的ip和port,而每個主庫要同步數據給從庫,自然有掛載的所有從庫信息。
所以,哨兵實例只需向主庫發送INFO命令即可獲取到所需要的信息,然後哨兵實例在依次與從庫建立連接。
至此,一個哨兵實例便可以收集到整個Redis 集羣的數據,包含三塊:
所有的哨兵節點ip、port
主節點ip、port
主節點掛載的所有從節點的 ip、port
其他哨兵實例也是一樣道理,這裏就不在贅述了。
哨兵是個集羣,選主需要有個帶頭大哥
當一個哨兵實例監控到主庫”主觀下線“後,給其他實例發送 is-master-down-by-addr 命令,其他哨兵實例根據自己與主庫的連接情況,做出 Y 或 N的回覆。
當這個哨兵收集到了超過 quorum 配置項的 Y 回覆後,就會標記主庫”客觀下線“。
下面,就要進入選主階段了。正所謂”一山不容二虎“,那麼由哪個哨兵實例來執行選主操作呢?
還是公平點,採用民主投票。先在 哨兵集羣中選出一個帶頭大哥,由它代表大家執行後續操作。
如何選哨兵Leader?

上圖畫了個流程實例,三個哨兵節點在 t1~t6 不同時刻點的投票情況。
當一個哨兵實例收到超過 設置的quorum 票Y後,它會成為新的Leader。然後由它(哨兵S3)負責後面的從庫選主,通知從庫與新主庫建立關係並同步數據,通知客户端訪問新主庫。
如果本輪沒有選出Leader節點,等哨兵故障轉移超時時間的 2 倍時間後,重新發起新一輪選舉。
為了保證哨兵Leader選舉的順利進行,除了對網絡質量有要求外,最好配置奇數個哨兵節點且最好三個以上。
哨兵也是實例,如果掛了怎麼辦?
哨兵主要是用來監控Redis集羣的健康狀況,本身並不提供服務。
當一個哨兵實例掛掉後,會影響到集羣的監測。為了降低影響,我們引入哨兵集羣,降低單點風險,由哨兵集羣保障Redis主從集羣的健康。
舉個例子:
哨兵集羣配置了三個實例,quorum 配置值為2。當一個哨兵實例宕機後,其餘兩個哨兵實例依然可以完成選舉,只是可能存在一定風險而已。
哨兵集羣完成了主從切換,客户端如何感知?
我們知道Redis有pub/sub機制,為了便於外部知道當前的切換進度,哨兵提供了多個訂閲頻道。
其中就有一個新主庫切換頻道,(switch-master)
SUBSCRIBE +switch-master
訂閲對應頻道,可以獲得切換後的新主庫ip、port,並與之建立連接,繼續享受Redis服務。
- 5 分鐘,快速入門 Python JWT 接口認證
- 5 分鐘,教你用 Docker 部署一個 Python 應用!
- uni-app關閉系統側邊滑動返回的方法總彙
- C 中不一樣的重載
- 字節一面:Redis主節點宕機,如何處理?
- 如何使用 Redis 實現 “附近的人” 這個功能?
- 介紹一款能取代 Scrapy 的爬蟲框架 - feapder
- 直觀講解一下 RPC 調用和 HTTP 調用的區別!
- MySQL 億級數據分頁的優化
- Python 多線程小技巧:比 time.sleep 更好用的暫停寫法!
- Python面試官:請説説併發場景鎖怎麼用?
- Python如何異步發送日誌到遠程服務器?
- Python 中的數字到底是什麼?
- 如何建立一個完美的 Python 項目?
- 詳解 Python 的二元算術運算,為什麼説減法只是語法糖?
- Python 為什麼沒有 main 函數?為什麼我不推薦寫 main 函數?
- Bug分析,假刪除導致文章發佈成功卻打不開的問題
- Python 進階:queue 隊列源碼分析
- Python實例篇:自動操作Excel文件(既簡單又特別實用)
- 誰説程序員不懂浪漫,當代碼遇到文學..