【NLP系列】Bert词向量的空间分布
作者:京东零售 彭馨
1. 背景
我们知道Bert 预训练模型针对分词、ner、文本分类等下游任务取得了很好的效果,但在语义相似度任务上,表现相较于 Word2Vec、Glove 等并没有明显的提升。有学者研究发现,这是因为 Bert 词向量存在各向异性(不同方向表现出的特征不一致),高频词分布在狭小的区域,靠近原点,低频词训练不充分,分布相对稀疏,远离原点,词向量整体的空间分布呈现锥形,如下图,导致计算的相似度存在问题。

2. 问题分析
为什么Bert词向量会呈现圆锥形的空间分布且高频词更靠近原点?

查了一些论文发现,除了这篇 ICLR 2019 的论文《Representation Degeneration Problem in Training Natural Language Generation Models》给出了一定的理论解释,几乎所有提及到 Bert 词向量空间分布存在问题的论文,都只是在引用该篇的基础上,直接将词向量压缩到二维平面上进行观测统计(肉眼看的说服力明显不够😂)
图中(b)(c)可以看出原生 Word2Vec 和分类任务的词向量经 SVD 投影,分布在原点周围,而原生 Transformer 则分布在圆锥形区域,且任意两个词向量都正相关,会降低模型性能,这种现象被称为表征退化问题。
-
①造成这种现象的直观解释是:在模型训练过程中,真词的embedding会被推向隐藏状态的方向,而其他词会被推向其负方向,结果是词汇表中大多数单词的嵌入将被推向与大多数隐藏状态负相关的相似方向,因此在嵌入空间的局部区域中聚集在一起。
-
②理论解释则是分析未出现词的嵌入,发现表征退化和隐藏状态的结构有关:当隐藏状态的凸包不包含原点时,退化出现,并且当使用层归一化进行训练时,很可能发生这种情况。并发现低频词很可能在优化过程中被训练为彼此接近,因此位于局部区域。
论文将对理论解释部分给出证明,下面从我的理解,来解读一下😂,最后再简单说一下另外两篇对 Bert 词向量观测统计的论文。
3. 理论解释
在介绍之前,先熟悉几个关于凸优化问题的概念(不知道其实也问题不大😂):
-
凸集:

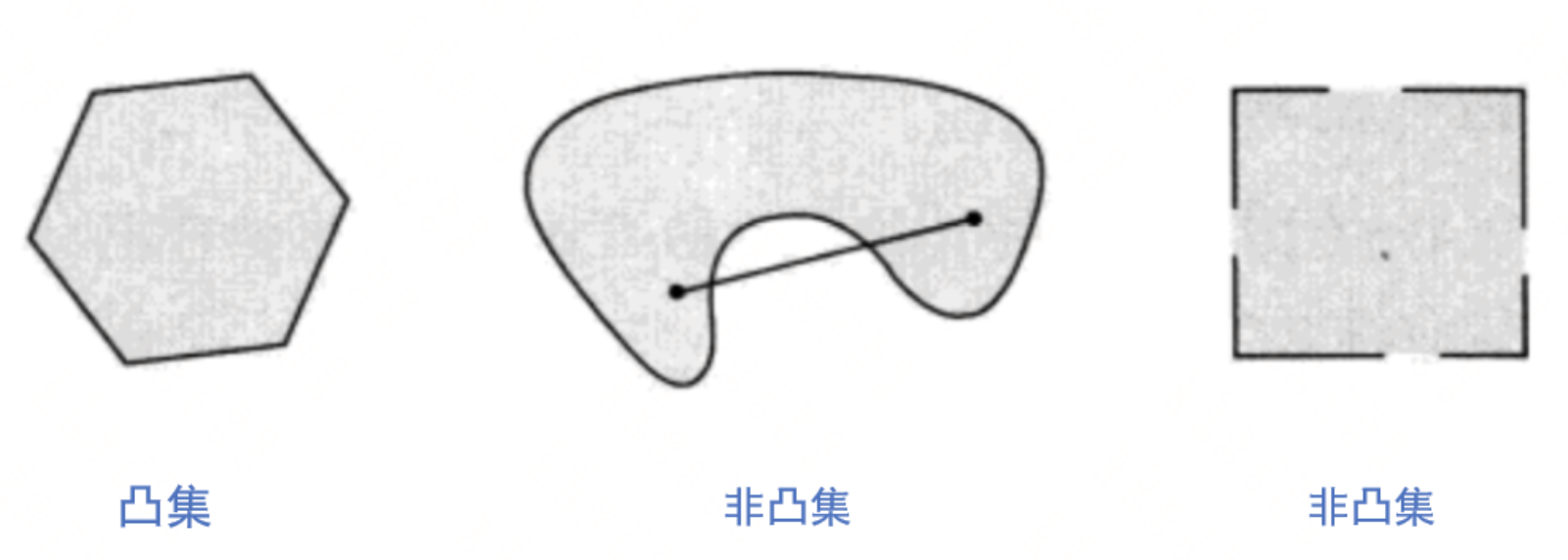
-
凸包:
点集Q的凸包是指一个最小凸多边形,满足Q中的点或者在多边形边上或者在其内。(最小的凸集)
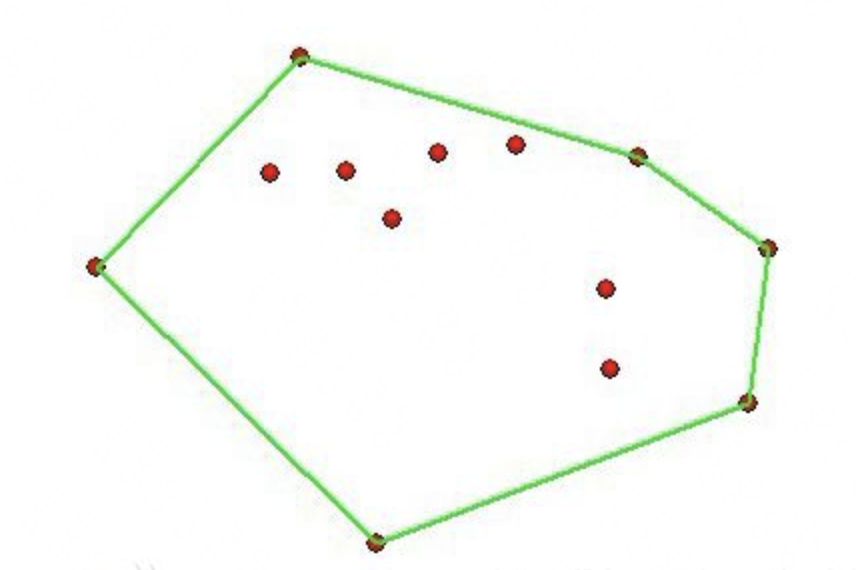
-
锥:

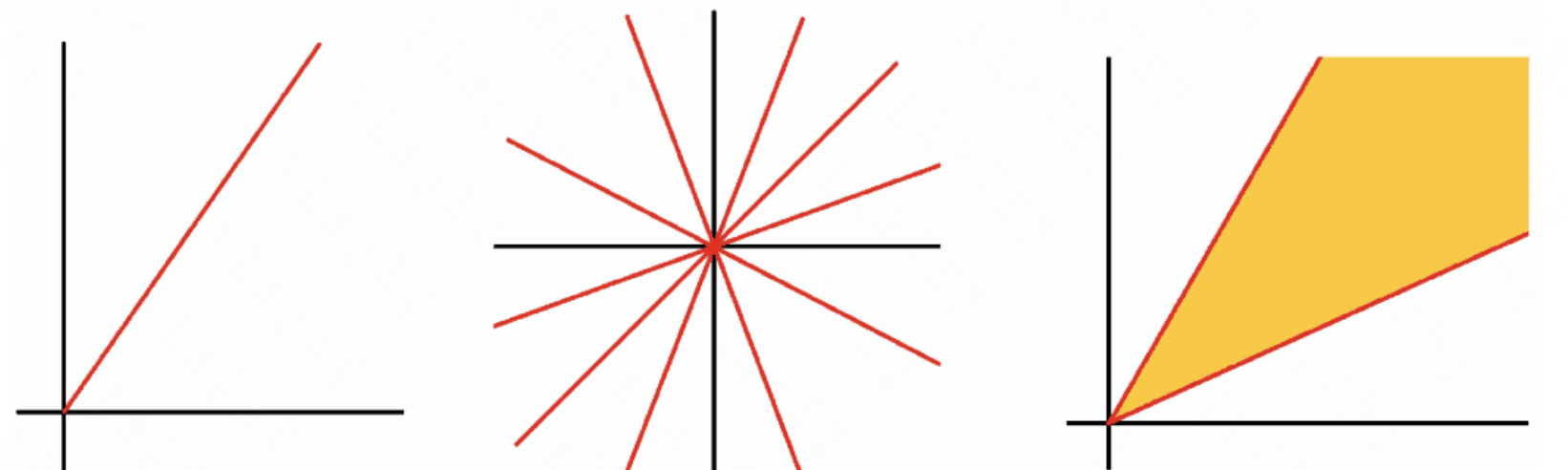
-
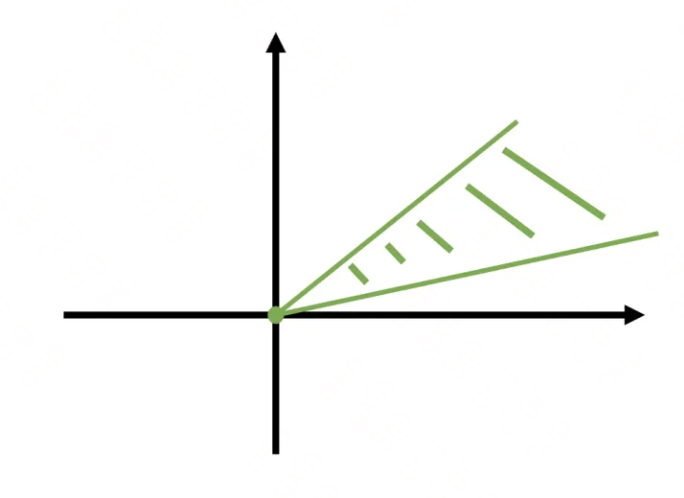
凸锥:
如果一个集合既是锥,又是凸集,则该集合是凸锥。
![]()
1)未出现词
因为不容易直接分析高、低频词,作者另辟蹊径,选择和低频词比较相似的未出现词来分析目标函数。


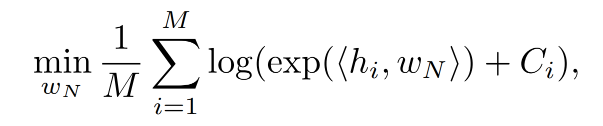

文中说定理1 中的 A 显而易见,那就只能大家自行理解这个凸集了。B 则是对上面最小化公式的求解,下面给出证明
证明:

证明:

以上还是很好理解的,定理1说明未出现词的向量会被优化无穷远,远离原点(模越来越大)。定理2则是说明词向量的分布不包含原点,而是在原点的一侧
2)低频词
低频词的分析则是在未出现词的基础上,因为分析低频词的embedding对损失函数的影响,将损失函数分为了两部分:
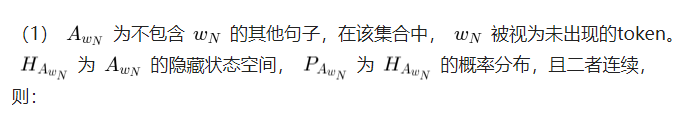
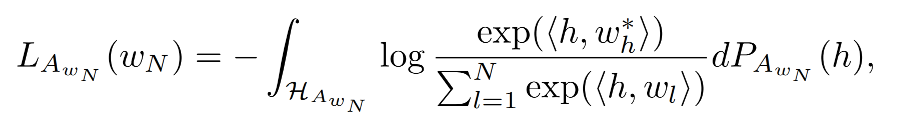

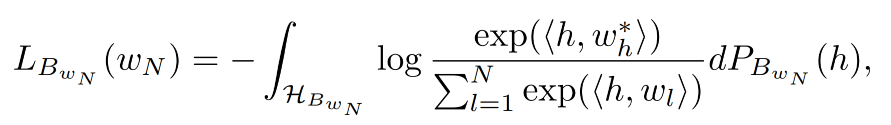
总损失函数为:


原来定理3 才是理解路上的最大绊脚石!

下面简述一下对词向量进行观测统计的论文
论文1《On the Sentence Embeddings from Pre-trained Language Models》
其实这篇论文就是字节的 Bert-flow(不熟悉 Bert-flow 可见《对比学习——文本匹配》)。论文计算了词嵌入与原点的平均l2距离,并根据词频做了排序(词频越高排名越靠前,第0位词频最高),得出高频词靠近原点、低频词远离原点的结论,如下表上半部分:
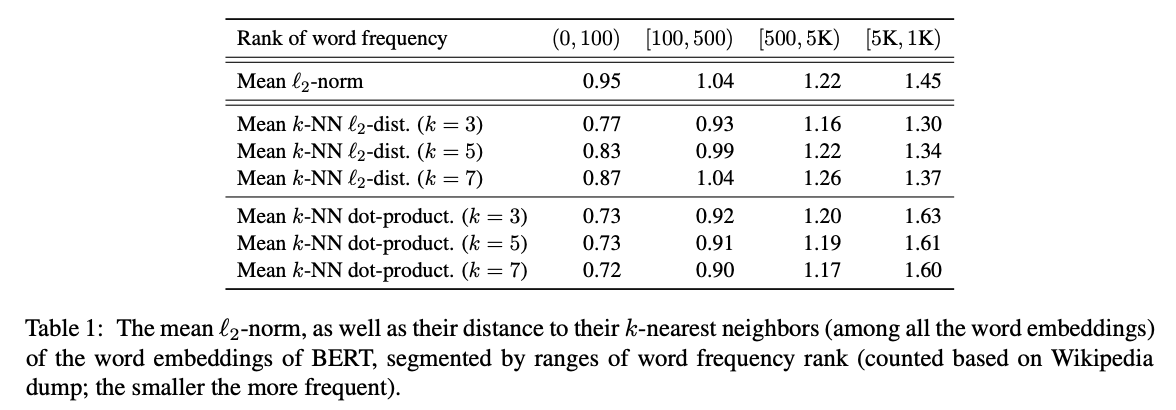
表的下半部分则为词嵌入和它的k个近邻之间的平均l2距离和点积,可以看出低频词相较于高频词,和它们的k近邻距离更远,说明低频词相对高频词分布更稀疏。
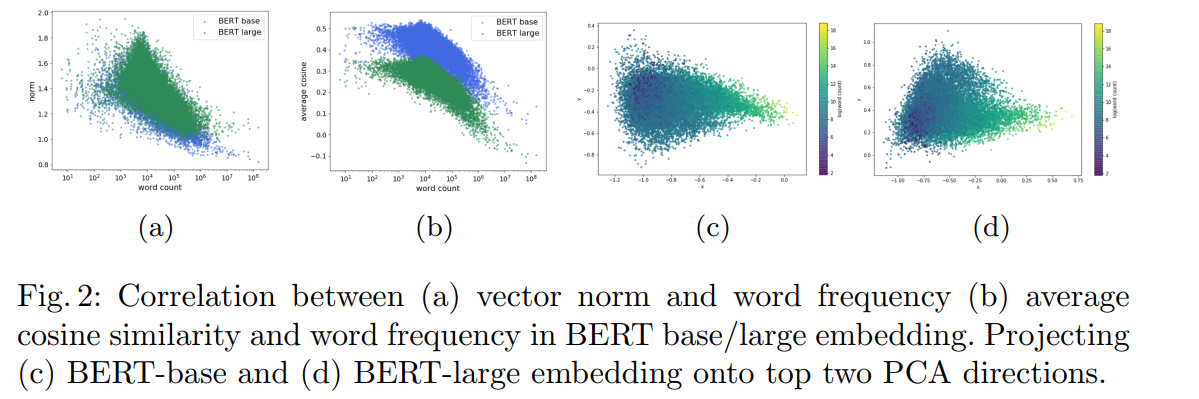
论文2《Learning to Remove: Towards Isotropic Pre-trained BERT Embedding》
该论文则是通过随机计算两个词的相似度,发现都远大于0(说明词向量的方向基本都一致,不一致不会都远大于0),以此说明词向量不是均匀分布在向量空间中,而是分布在一个狭窄的圆锥体中。
4. 总结
都有理论解释了,结论自然就是 Bert 词向量确实存在表征退化问题,词向量存在各向异性,高频词距离原点更近,低频词训练不充分,远离原点,整体分布呈现圆锥形,导致其不适用于语义相似度任务。不过不知道该理论解释有没有说服你😄😄😄,有不同见解或疑问,欢迎前来交流。
针对此类问题,可以采用一下方法对其进行纠正,如论文[1]中加入cos正则,论文[2]中将锥形分布转化为高斯分布。因为词向量有问题,句向量自然跑不了,所以《对比学习——文本匹配》中的算法其实也都是为了解决这个问题。
附:(定理3证明)

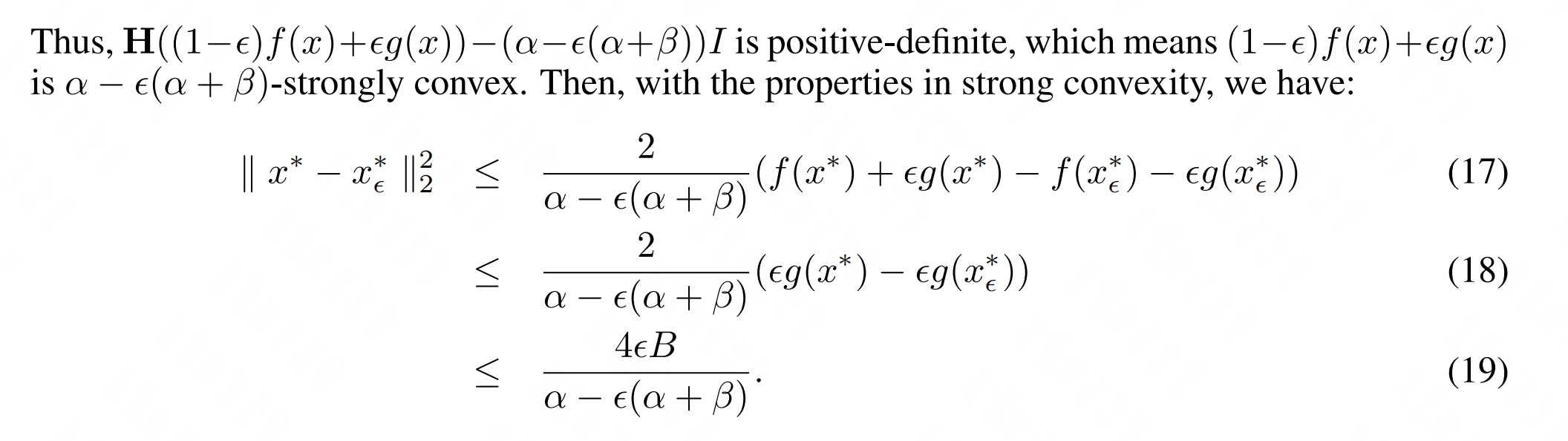
- 应用健康度隐患刨析解决系列之数据库时区设置
- 对于Vue3和Ts的心得和思考
- 一文详解扩散模型:DDPM
- zookeeper的Leader选举源码解析
- 一文带你搞懂如何优化慢SQL
- 京东金融Android瘦身探索与实践
- 微前端框架single-spa子应用加载解析
- cookie时效无限延长方案
- 聊聊前端性能指标那些事儿
- Spring竟然可以创建“重复”名称的bean?—一次项目中存在多个bean名称重复问题的排查
- 京东金融Android瘦身探索与实践
- Spring源码核心剖析
- 深入浅出RPC服务 | 不同层的网络协议
- 安全测试之探索windows游戏扫雷
- 关于数据库分库分表的一点想法
- 对于Vue3和Ts的心得和思考
- Bitmap、RoaringBitmap原理分析
- 京东小程序CI工具实践
- 测试用例设计指南
- 当你对 redis 说你中意的女孩是 Mia