大語言模型: 新的摩爾定律?
譯者按: 最近一段時間,ChatGPT 作為一個現象級應用迅速躥紅,也帶動了對其背後的大語言模型 (LLM) 的討論,這些討論甚至出了 AI 技術圈,頗有些到了街談巷議的程度。在 AI 技術圈,關於 LLM 和小模型的討論在此之前已經持續了不短的時間,處於不同生態位置和產業環節的人都有表達自己的觀點,其中不少是有衝突的。
大模型的研究者和大公司出於不同的動機站位 LLM,研究者出於對 LLM 的突現能力 (emergent ability) 的好奇和對 LLM 對 NLP 領域能力邊界的拓展、而大公司可能更多出自於商業利益考量;而社群和中小公司猶猶豫豫在小模型的站位上徘徊,一方面是由於對 LLM 最終訓練、推理和資料成本的望而卻步,一方面也是對大模型可能加強大公司資料霸權的隱隱擔憂。但討論,尤其是公開透明的討論,總是好事,讓大家能夠聽到不同的聲音,才有可能最終收斂至更合理的方案。
我們選譯的這篇文章來自於 2021 年 10 月的 Hugging Face 部落格,作者在那個時間點站位的是小模型,一年多以後的 2023 年作者的觀點有沒有改變我們不得而知,但開卷有益,瞭解作者當時考慮的那些點,把那些合理的點納入自己的思考體系,並結合新的進展最終作出自己的判斷可能才是最終目的。
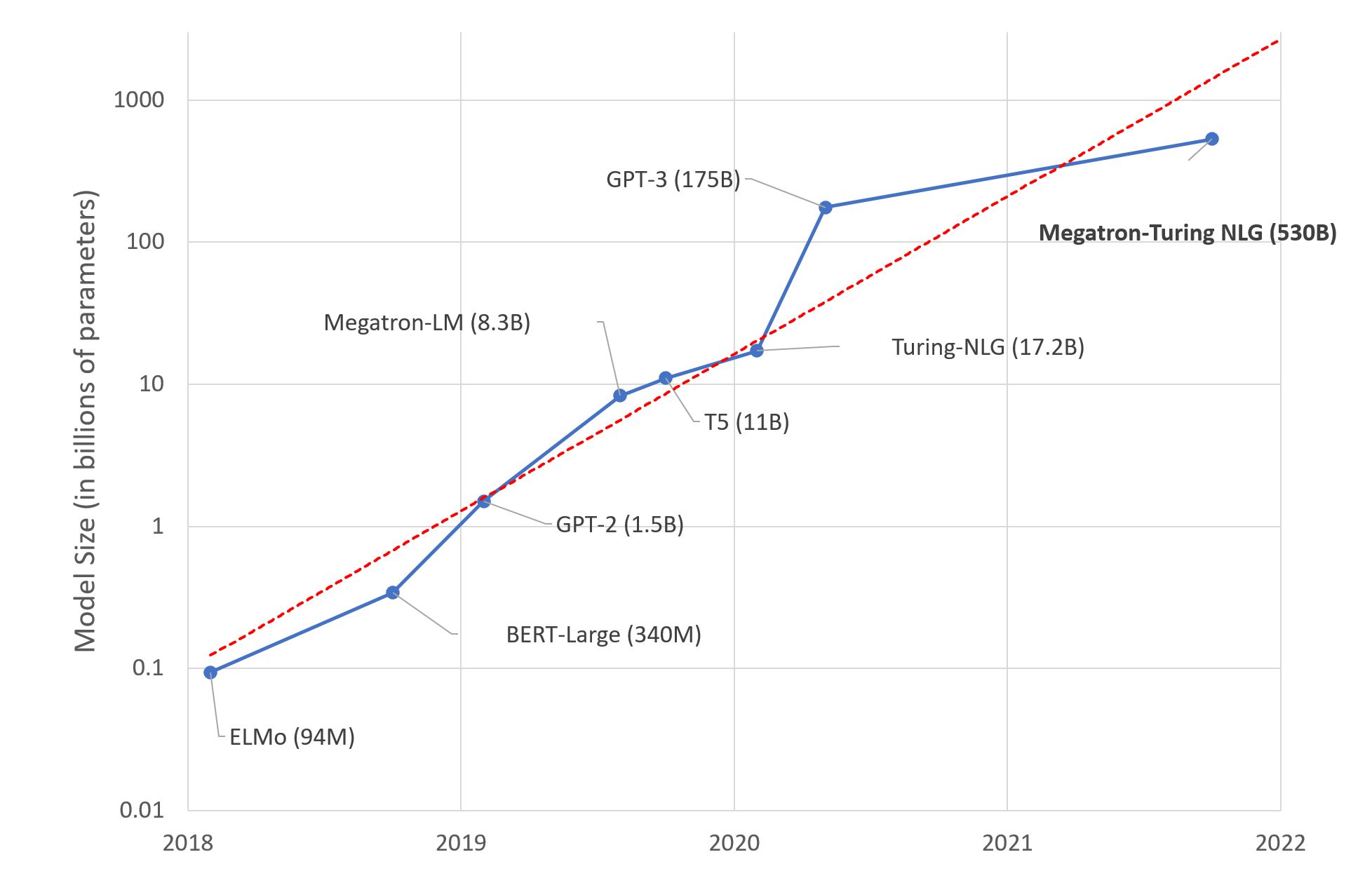
不久前,微軟和 Nvidia 推出 了 Megatron-Turing NLG 530B,一種基於 Transformer 的模型,被譽為是 “世界上最大且最強的生成語言模型”。
毫無疑問,此項成果對於機器學習工程來講是一場令人印象深刻的能力展示,表明我們的工程能力已經能夠訓練如此巨大的模型。然而,我們應該為這種超級模型的趨勢感到興奮嗎?我個人傾向於否定的回答。我將在通過本文闡述我的理由。
這是你的深度學習大腦
研究人員估計,人腦平均包含 860 億個神經元和 100 萬億個突觸。可以肯定的是,這裡面並非所有的神經元和突觸都用於語言。有趣的是,GPT-4 預計 有大約 100 萬億個引數...... 雖然這個類比很粗略,但難道我們不應該懷疑一下構建與人腦大小相當的語言模型長期來講是否是最佳方案?
當然,我們的大腦是一個了不起的器官,它經過數百萬年的進化而產生,而深度學習模型僅有幾十年的歷史。不過,我們的直覺告訴我們: 有些東西無法計算 (這是個雙關語,:)) 。
深度學習,深度銷金窟?
如你所料,在龐大的文字資料集上訓練一個 5300 億引數的模型需要相當多的基礎設施。事實上,Microsoft 和 Nvidia 使用了數百臺 DGX A100 GPU 伺服器,每臺 19 萬 9 千美元。如果再把網路裝置、託管成本等因素考慮進去的話,任何想要重現該實驗的組織或個人都必須花費近 1 億美元。來根薯條壓壓驚?
說真的,有哪些組織有那種值得花費 1 億美元來構建深度學習基礎設施的業務?再少點,又有哪些組織有那種可以值得花費 1000 萬美元基礎設施的業務?很少。既然很少,那麼請問,這些模型為誰而生呢?
GPU 叢集的熱
儘管訓練大模型需要傑出的工程能力,但在 GPU 上訓練深度學習模型本身卻是一種蠻力技術。根據規格表,每臺 DGX 伺服器可消耗高達 6.5 千瓦的功率。同時,資料中心 (或伺服器機櫃) 至少需要同樣多的冷卻能力。除非你是史塔克家族的人 (Starks) ,需要在冬天讓臨冬城 (Winterfell) 保持溫暖,否則你必須處理散熱問題。
此外,隨著公眾對氣候和社會責任問題意識的增強,還需要考慮碳足跡問題。根據馬薩諸塞大學 2019 年的一項 研究,“在 GPU 上訓練一次 BERT 產生的碳足跡大致與一次跨美飛行相當”。
BERT-Large 有 3.4 億個引數。我們可以通過此推斷 Megatron-Turing 的碳足跡大致如何……認識我的人都知道,我並不是一個熱血環保主義者。儘管如此,這些數字也不容忽視。
所以呢?
我對 Megatron-Turing NLG 530B 和接下來可能會出現的模型巨獸感到興奮嗎?不。我認為值得增加成本、複雜性以及碳足跡去換取 (相對較小的) 測試基準上的改進嗎?不。我認為構建和推廣這些龐大的模型能幫助組織理解和應用機器學習嗎?不。
我想知道這一切有什麼意義。為了科學而科學?好的老營銷策略?技術至上?可能每個都有一點。如果是這些意義的話,我就不奉陪了。
相反,我更專注於實用且可操作的技術,大家都可以使用這些技術來構建高質量的機器學習解決方案。
使用預訓練模型
在絕大多數情況下,你不需要自定義模型架構。也許你會 想要 自己定製一個模型架構 (這是另一回事),但請注意此處猛獸出沒,僅限資深玩家!
一個好的起點是尋找已經針對你要解決的任務預訓練過的 模型 (例如,英文文字摘要) 。
然後,你應該快速嘗試一些模型,用它們來預測你自己的資料。如果指標效果不錯,那麼打完收工!如果還需要更高一點的準確率,你應該考慮對模型進行微調 (稍後會詳細介紹) 。
使用較小的模型
在評估模型時,你應該從那些精度滿足要求的模型中選擇尺寸最小的那個。它預測得更快,並且需要更少的硬體資源來進行訓練和推理。節儉需要從一開始就做起。
這其實也不算什麼新招。計算機視覺從業者會記得 SqueezeNet 2017 年問世時,與 AlexNet 相比,模型尺寸減少了 50 倍,而準確率卻與 AlexNet 相當甚至更高。多聰明!
自然語言處理社群也在致力於使用遷移學習技術縮減模型尺寸,如使用知識蒸餾技術。 DistilBERT 也許是其中最廣為人知的工作。與原始 BERT 模型相比,它保留了 97% 的語言理解能力,同時尺寸縮小了 40%,速度提高了 60%。你可以 Hugging Face 嘗試一下 DistilBERT。同樣的方法也已經應用於其他模型,例如 Facebook 的 BART,你可以在 Hugging Face 嘗試 DistilBART。
Big Science 專案的最新模型也令人印象深刻。下面這張來自於 論文 的圖表明,他們的 T0 模型在許多工上都優於 GPT-3,同時尺寸小 16 倍。你可以 Hugging Face 嘗試 T0。

我們需要更多的此類研究!
微調模型
如果你需要特化一個模型,你不應該從頭開始訓練它。相反,你應該對其進行微調,也就是說,僅針對你自己的資料訓練幾個回合。如果你缺少資料,也許這些 資料集 中的某個可以幫助你入門。
猜對了,這是進行遷移學習的另一種方式,它會幫助你節省一切!
- 收集、儲存、清理和標註的資料更少,
- 更快的實驗和迭代,
- 生產過程所需的資源更少。
換句話說: 節省時間,節省金錢,節省硬體資源,拯救世界!
如果你需要教程,Hugging Face 課程 可以幫助你立即入門。
使用雲基礎設施
不管你是否喜歡它們,事實是雲公司懂得如何構建高效的基礎設施。可持續性研究表明,基於雲的基礎設施比其他替代方案更節能減排: 請參閱 AWS、Azure 和 Google。 Earth.org 宣稱 雖然雲基礎設施並不完美,“[它] 比替代方案更節能,並促進了環境友好的服務及經濟增長。"
在易用性、靈活性和隨用隨付方面,雲肯定有很多優勢。它也比你想象的更環保。如果你的 GPU 不夠用,為什麼不嘗試在 AWS 的機器學習託管服務 Amazon SageMaker 上微調你的 Hugging Face 模型?我們為你準備了 大量示例。
優化你的模型
從編譯器到虛擬機器,軟體工程師長期以來一直在使用能夠針對任何執行硬體自動優化程式碼的工具。
然而,機器學習社群仍在這個課題上苦苦掙扎,這是有充分理由的。優化模型的尺寸和速度是一項極其複雜的任務,其中涉及以下技術:
- 專用硬體加速: 如訓練加速硬體 (Graphcore、Habana) 、推理加速硬體 (Google TPU,AWS Inferentia)。
- 剪枝: 刪除對預測結果影響很小或沒有影響的模型引數。
- 融合: 合併模型層 (例如,卷積和啟用) 。
- 量化: 以較小的位深儲存模型引數 (例如,使用 8 位而不是 32 位)
幸運的是,自動化工具開始出現,例如 Optimum 開源庫和 Infinity,Infinity 是一個最低能以 1 毫秒的延遲提供 Transformers 推理能力的容器化解決方案。
結論
在過去的幾年裡,大語言模型的尺寸平均每年增長 10 倍。這開始看起來像另一個摩爾定律。
這條路似曾相識,我們應該知道這條路遲早會遇到收益遞減、成本增加、複雜性等問題以及新的風險。指數的結局往往不是會很好。還記得 Meltdown and Spectre 嗎?我們想知道人工智慧的 Meltdown and Spectre 會是什麼嗎?
英文原文: http://hf.co/blog/large-language-models
原作者: Julien Simon
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態資料上的應用及大規模模型的訓練推理。
審校、排版: zhongdongy (阿東)
- 在一張 24 GB 的消費級顯示卡上用 RLHF 微調 20B LLMs
- 如何評估大語言模型
- 千億引數開源大模型 BLOOM 背後的技術
- Kakao Brain 的開源 ViT、ALIGN 和 COYO 文字-圖片資料集
- AI 影評家: 用 Hugging Face 模型打造一個電影評分機器人
- 我的語言模型應該有多大?
- Hugging Face 每週速遞: Chatbot Hackathon;FLAN-T5 XL 微調;構建更安全的 LLM
- AI 大戰 AI,一個深度強化學習多智慧體競賽系統
- Hugging Face 每週速遞: ChatGPT API 怎麼用?我們幫你搭好頁面了
- 深入瞭解視覺語言模型
- CPU推理|使用英特爾 Sapphire Rapids 加速 PyTorch Transformers
- 大語言模型: 新的摩爾定律?
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 在低程式碼開發平臺 ILLA Cloud 中使用 Hugging Face 上的模型
- 瞭解 Transformers 是如何“思考”的
- 第 1 天|基於 AI 進行遊戲開發:5 天建立一個農場遊戲!
- 加速 Document AI (文件智慧) 發展
- 一文帶你入門圖機器學習
- 解讀 ChatGPT 背後的技術重點:RLHF、IFT、CoT、紅藍對抗