來一波騷操作,Java內存模型
文章整理自 博學谷狂野架構師
什麼是JMM

併發編程領域的關鍵問題
線程之間的通信
線程的通信是指線程之間以何種機制來交換信息。在編程中,線程之間的通信機制有兩種,共享內存和消息傳遞。 在共享內存的併發模型裏,線程之間共享程序的公共狀態,線程之間通過寫-讀內存中的公共狀態來隱式進行通信,典型的共享內存通信方式就是通過共享對象進行通信。 在消息傳遞的併發模型裏,線程之間沒有公共狀態,線程之間必須通過明確的發送消息來顯式進行通信,在java中典型的消息傳遞方式就是wait()和notify()。
線程間的同步
同步是指程序用於控制不同線程之間操作發生相對順序的機制。
在共享內存併發模型裏,同步是顯式進行的。程序員必須顯式指定某個方法或某段代碼需要在線程之間互斥執行。 在消息傳遞的併發模型裏,由於消息的發送必須在消息的接收之前,因此同步是隱式進行的。
現代計算機的內存模型
物理計算機中的併發問題,物理機遇到的併發問題與虛擬機中的情況有不少相似之處,物理機對併發的處理方案對於虛擬機的實現也有相當大的參考意義。
其中一個重要的複雜性來源是絕大多數的運算任務都不可能只靠處理器“計算”就能完成,處理器至少要與內存交互,如讀取運算數據、存儲運算結果等,這個I/O操作是很難消除的(無法僅靠寄存器來完成所有運算任務)。
早期計算機中cpu和內存的速度是差不多的,但在現代計算機中,cpu的指令速度遠超內存的存取速度,由於計算機的存儲設備與處理器的運算速度有幾個數量級的差距,所以現代計算機系統都不得不加入一層讀寫速度儘可能接近處理器運算速度的高速緩存(Cache)來作為內存與處理器之間的緩衝:將運算需要使用到的數據複製到緩存中,讓運算能快速進行,當運算結束後再從緩存同步回內存之中,這樣處理器就無須等待緩慢的內存讀寫了。
基於高速緩存的存儲交互很好地解決了處理器與內存的速度矛盾,但是也為計算機系統帶來更高的複雜度,因為它引入了一個新的問題:緩存一致性(Cache Coherence)。
在多處理器系統中,每個處理器都有自己的高速緩存,而它們又共享同一主內存(MainMemory)。當多個處理器的運算任務都涉及同一塊主內存區域時,將可能導致各自的緩存數據不一致,舉例説明變量在多個CPU之間的共享。
如果真的發生這種情況,那同步回到主內存時以誰的緩存數據為準呢?為了解決一致性的問題,需要各個處理器訪問緩存時都遵循一些協議,在讀寫時要根據協議來進行操作,這類協議有MSI、MESI(Illinois Protocol)、MOSI、Synapse、Firefly及Dragon Protocol等。

該內存模型帶來的問題
現代的處理器使用寫緩衝區臨時保存向內存寫入的數據。寫緩衝區可以保證指令流水線持續運行,它可以避免由於處理器停頓下來等待向內存寫入數據而產生的延遲。
同時,通過以批處理的方式刷新寫緩衝區,以及合併寫緩衝區中對同一內存地址的多次寫,減少對內存總線的佔用。
雖然寫緩衝區有這麼多好處,但每個處理器上的寫緩衝區,僅僅對它所在的處理器可見。這個特性會對內存操作的執行順序產生重要的影響:處理器對內存的讀/寫操作的執行順序,不一定與內存實際發生的讀/寫操作順序一致! 處理器A和處理器B按程序的順序並行執行內存訪問,最終可能得到x=y=0的結果。 處理器A和處理器B可以同時把共享變量寫入自己的寫緩衝區(A1,B1),然後從內存中讀取另一個共享變量(A2,B2),最後才把自己寫緩存區中保存的髒數據刷新到內存中(A3,B3)。
當以這種時序執行時,程序就可以得到x=y=0的結果。 從內存操作實際發生的順序來看,直到處理器A執行A3來刷新自己的寫緩存區,寫操作A1才算真正執行了。雖然處理器A執行內存操作的順序為:A1→A2,但內存操作實際發生的順序卻是A2→A1。
| Processor A | Processor B | |
|---|---|---|
| 代碼 | a=1; //A1 x=1; //A2 | b=2; //B1 y=a; //B2 |
| 運行結果 | 初始狀態 a=b=0 處理器允許得到結果 x=y=0 |

Java內存模型定義
JMM定義了Java 虛擬機(JVM)在計算機內存(RAM)中的工作方式。JVM是整個計算機虛擬模型,所以JMM是隸屬於JVM的。
從抽象的角度來看,JMM定義了線程和主內存之間的抽象關係:線程之間的共享變量存儲在主內存(Main Memory)中,每個線程都有一個私有的本地內存(Local Memory),本地內存中存儲了該線程以讀/寫共享變量的副本。
本地內存是JMM的一個抽象概念,並不真實存在。它涵蓋了緩存、寫緩衝區、寄存器以及其他的硬件和編譯器優化。
Java內存區域

Java虛擬機在運行程序時會把其自動管理的內存劃分為以上幾個區域,每個區域都有的用途以及創建銷燬的時機,其中藍色部分代表的是所有線程共享的數據區域,而紫色部分代表的是每個線程的私有數據區域。
方法區
方法區屬於線程共享的內存區域,又稱Non-Heap(非堆),主要用於存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯後的代碼等數據,根據Java 虛擬機規範的規定,當方法區無法滿足內存分配需求時,將拋出OutOfMemoryError 異常。
值得注意的是在方法區中存在一個叫運行時常量池(Runtime Constant Pool)的區域,它主要用於存放編譯器生成的各種字面量和符號引用,這些內容將在類加載後存放到運行時常量池中,以便後續使用。
JVM堆
Java 堆也是屬於線程共享的內存區域,它在虛擬機啟動時創建,是Java 虛擬機所管理的內存中最大的一塊,主要用於存放對象實例,幾乎所有的對象實例都在這裏分配內存,注意Java 堆是垃圾收集器管理的主要區域,因此很多時候也被稱做GC 堆,如果在堆中沒有內存完成實例分配,並且堆也無法再擴展時,將會拋出OutOfMemoryError 異常。
程序計數器
屬於線程私有的數據區域,是一小塊內存空間,主要代表當前線程所執行的字節碼行號指示器。字節碼解釋器工作時,通過改變這個計數器的值來選取下一條需要執行的字節碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴這個計數器來完成。
虛擬機棧
屬於線程私有的數據區域,與線程同時創建,總數與線程關聯,代表Java方法執行的內存模型。每個方法執行時都會創建一個棧楨來存儲方法的的變量表、操作數棧、動態鏈接方法、返回值、返回地址等信息。每個方法從調用直結束就對於一個棧楨在虛擬機棧中的入棧和出棧過程,如下(圖有誤,應該為棧楨):
本地方法棧
本地方法棧屬於線程私有的數據區域,這部分主要與虛擬機用到的 Native 方法相關,一般情況下,我們無需關心此區域。
小結
這裏之所以簡要説明這部分內容,注意是為了區別Java內存模型與Java內存區域的劃分,畢竟這兩種劃分是屬於不同層次的概念。
Java內存模型概述
Java內存模型(即Java Memory Model,簡稱JMM)本身是一種抽象的概念,並不真實存在,它描述的是一組規則或規範,通過這組規範定義了程序中各個變量(包括實例字段,靜態字段和構成數組對象的元素)的訪問方式。
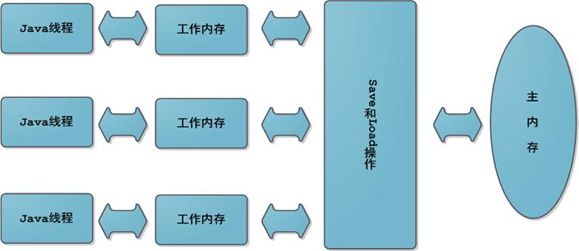
由於JVM運行程序的實體是線程,而每個線程創建時JVM都會為其創建一個工作內存(有些地方稱為棧空間),用於存儲線程私有的數據,而Java內存模型中規定所有變量都存儲在主內存,主內存是共享內存區域,
所有線程都可以訪問,但線程對變量的操作(讀取賦值等)必須在工作內存中進行,首先要將變量從主內存拷貝的自己的工作內存空間,然後對變量進行操作,操作完成後再將變量寫回主內存,不能直接操作主內存中的變量,工作內存中存儲着主內存中的變量副本拷貝,
前面説過,工作內存是每個線程的私有數據區域,因此不同的線程間無法訪問對方的工作內存,線程間的通信(傳值)必須通過主內存來完成,其簡要訪問過程如下圖

需要注意的是,JMM與Java內存區域的劃分是不同的概念層次,更恰當説JMM描述的是一組規則,通過這組規則控制程序中各個變量在共享數據區域和私有數據區域的訪問方式,JMM是圍繞原子性,有序性、可見性展開的(稍後會分析)。
JMM與Java內存區域唯一相似點,都存在共享數據區域和私有數據區域,在JMM中主內存屬於共享數據區域,從某個程度上講應該包括了堆和方法區,而工作內存數據線程私有數據區域,從某個程度上講則應該包括程序計數器、虛擬機棧以及本地方法棧。
或許在某些地方,我們可能會看見主內存被描述為堆內存,工作內存被稱為線程棧,實際上他們表達的都是同一個含義。關於JMM中的主內存和工作內存説明如下
主內存
主要存儲的是Java實例對象,所有線程創建的實例對象都存放在主內存中,不管該實例對象是成員變量還是方法中的本地變量(也稱局部變量),當然也包括了共享的類信息、常量、靜態變量。
由於是共享數據區域,多條線程對同一個變量進行訪問可能會發現線程安全問題。
工作內存
主要存儲當前方法的所有本地變量信息(工作內存中存儲着主內存中的變量副本拷貝),每個線程只能訪問自己的工作內存,即線程中的本地變量對其它線程是不可見的,就算是兩個線程執行的是同一段代碼,它們也會各自在自己的工作內存中創建屬於當前線程的本地變量,當然也包括了字節碼行號指示器、相關Native方法的信息。
注意由於工作內存是每個線程的私有數據,線程間無法相互訪問工作內存,因此存儲在工作內存的數據不存在線程安全問題。
數據同步
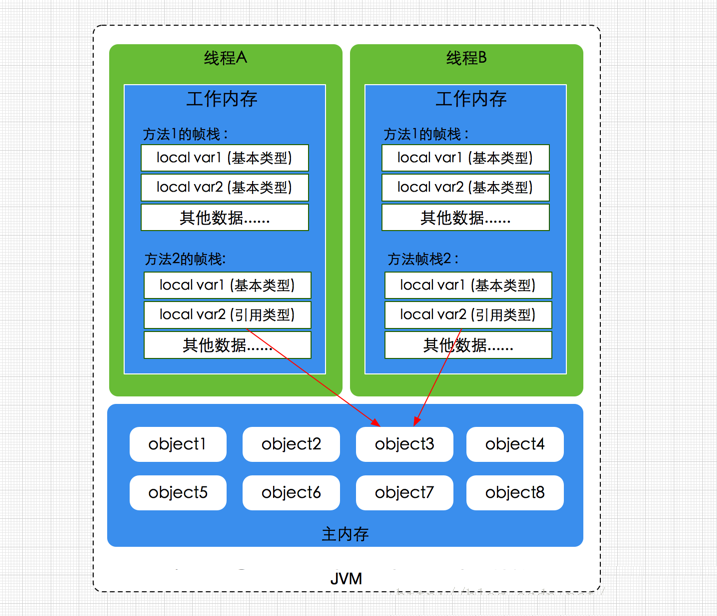
弄清楚主內存和工作內存後,接瞭解一下主內存與工作內存的數據存儲類型以及操作方式,根據虛擬機規範,對於一個實例對象中的成員方法而言,如果方法中包含本地變量是基本數據類型(boolean,byte,short,char,int,long,float,double),將直接存儲在工作內存的幀棧結構中,但倘若本地變量是引用類型,那麼該變量的引用會存儲在功能內存的幀棧中,而對象實例將存儲在主內存(共享數據區域,堆)中。
但對於實例對象的成員變量,不管它是基本數據類型或者包裝類型(Integer、Double等)還是引用類型,都會被存儲到堆區。
至於static變量以及類本身相關信息將會存儲在主內存中。需要注意的是,在主內存中的實例對象可以被多線程共享,倘若兩個線程同時調用了同一個對象的同一個方法,那麼兩條線程會將要操作的數據拷貝一份到自己的工作內存中,執行完成操作後才刷新到主內存,簡單示意圖如下所示:
硬件內存架構與Java內存模型
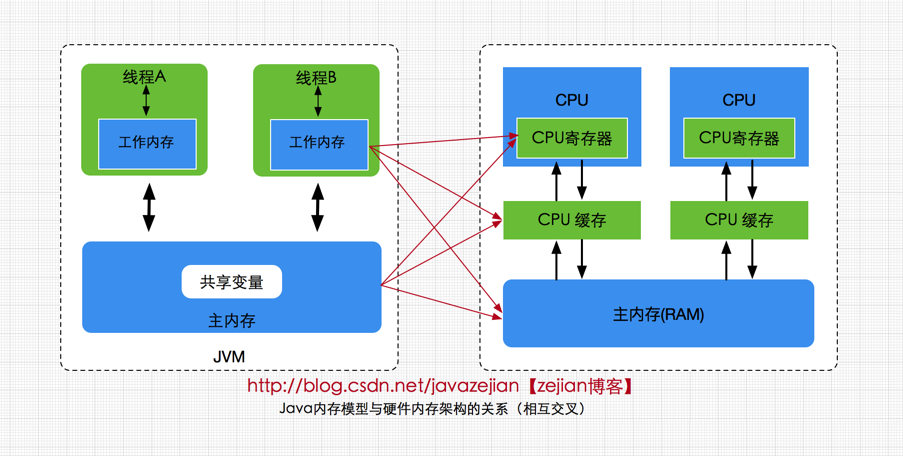
硬件內存架構

正如上圖所示,經過簡化CPU與內存操作的簡易圖,實際上沒有這麼簡單,這裏為了理解方便,我們省去了南北橋並將三級緩存統一為CPU緩存(有些CPU只有二級緩存,有些CPU有三級緩存)。
就目前計算機而言,一般擁有多個CPU並且每個CPU可能存在多個核心,多核是指在一枚處理器(CPU)中集成兩個或多個完整的計算引擎(內核),這樣就可以支持多任務並行執行,從多線程的調度來説,每個線程都會映射到各個CPU核心中並行運行。
在CPU內部有一組CPU寄存器,寄存器是cpu直接訪問和處理的數據,是一個臨時放數據的空間。一般CPU都會從內存取數據到寄存器,然後進行處理,但由於內存的處理速度遠遠低於CPU,導致CPU在處理指令時往往花費很多時間在等待內存做準備工作
於是在寄存器和主內存間添加了CPU緩存,CPU緩存比較小,但訪問速度比主內存快得多,如果CPU總是操作主內存中的同一址地的數據,很容易影響CPU執行速度,此時CPU緩存就可以把從內存提取的數據暫時保存起來,如果寄存器要取內存中同一位置的數據,直接從緩存中提取,無需直接從主內存取。
需要注意的是,寄存器並不每次數據都可以從緩存中取得數據,萬一不是同一個內存地址中的數據,那寄存器還必須直接繞過緩存從內存中取數據。
所以並不每次都得到緩存中取數據,這種現象有個專業的名稱叫做緩存的命中率,從緩存中取就命中,不從緩存中取從內存中取,就沒命中,可見緩存命中率的高低也會影響CPU執行性能,這就是CPU、緩存以及主內存間的簡要交互過程,
總而言之當一個CPU需要訪問主存時,會先讀取一部分主存數據到CPU緩存(當然如果CPU緩存中存在需要的數據就會直接從緩存獲取),進而在讀取CPU緩存到寄存器,當CPU需要寫數據到主存時,同樣會先刷新寄存器中的數據到CPU緩存,然後再把數據刷新到主內存中。
Java線程與硬件處理器
瞭解完硬件的內存架構後,接着瞭解JVM中線程的實現原理,理解線程的實現原理,有助於我們瞭解Java內存模型與硬件內存架構的關係,在Window系統和Linux系統上,Java線程的實現是基於一對一的線程模型,所謂的一對一模型,實際上就是通過語言級別層面程序去間接調用系統內核的線程模型,即我們在使用Java線程時,Java虛擬機內部是轉而調用當前操作系統的內核線程來完成當前任務。
這裏需要了解一個術語,內核線程(Kernel-Level Thread,KLT),它是由操作系統內核(Kernel)支持的線程,這種線程是由操作系統內核來完成線程切換,內核通過操作調度器進而對線程執行調度,並將線程的任務映射到各個處理器上。每個內核線程可以視為內核的一個分身,這也就是操作系統可以同時處理多任務的原因。
由於我們編寫的多線程程序屬於語言層面的,程序一般不會直接去調用內核線程,取而代之的是一種輕量級的進程(Light Weight Process),也是通常意義上的線程,由於每個輕量級進程都會映射到一個內核線程,因此我們可以通過輕量級進程調用內核線程,進而由操作系統內核將任務映射到各個處理器,這種輕量級進程與內核線程間1對1的關係就稱為一對一的線程模型。如下圖

如圖所示,每個線程最終都會映射到CPU中進行處理,如果CPU存在多核,那麼一個CPU將可以並行執行多個線程任務。
Java內存模型與硬件內存架構的關係
通過對前面的硬件內存架構、Java內存模型以及Java多線程的實現原理的瞭解,我們應該已經意識到,多線程的執行最終都會映射到硬件處理器上進行執行,但Java內存模型和硬件內存架構並不完全一致。
對於硬件內存來説只有寄存器、緩存內存、主內存的概念,並沒有工作內存(線程私有數據區域)和主內存(堆內存)之分,也就是説Java內存模型對內存的劃分對硬件內存並沒有任何影響,因為JMM只是一種抽象的概念,是一組規則,並不實際存在,
不管是工作內存的數據還是主內存的數據,對於計算機硬件來説都會存儲在計算機主內存中,當然也有可能存儲到CPU緩存或者寄存器中,因此總體上來説,Java內存模型和計算機硬件內存架構是一個相互交叉的關係,是一種抽象概念劃分與真實物理硬件的交叉。(注意對於Java內存區域劃分也是同樣的道理)
當對象和變量可以存儲在計算機的各種不同存儲區域中時,可能會出現某些問題。兩個主要問題是:
- 線程更新(寫入)共享變量的可見性。
- 讀取,檢查和寫入共享變量時的競爭條件。
共享對象的可見性
如果兩個或多個線程共享一個對象,而沒有正確使用 volatile 聲明或同步,則一個線程對共享對象的更改對於在其他CPU上運行的線程是不可見的。
這樣,每個線程最終都可能擁有自己的共享對象副本,每個副本都位於不同的CPU緩存中,並且其中的內容不相同。
下圖簡單説明了情況。在左邊CPU上運行的一個線程將共享對象複製到其CPU緩存中,並將其 count 變量更改為2。此更改對於在CPU上運行的其他線程不可見,因為count的更新尚未刷新回主內存。

要解決此問題,您可以使用Java的volatile關鍵字。volatile 關鍵字可以確保變量從主內存中直接讀取而不是從緩存中,並且更新的時候總是立即寫回主內存。
競爭條件
如果兩個或多個線程共享一個對象,並且多個線程更新該共享對象中的成員變量,則可能會出現競爭條件。
想象一下,如果線程A將共享對象的變量count讀入其CPU緩存中。再想象一下,線程B也做了同樣的事情,但是進入到了不同的CPU緩存。現在線程A添加一個值到count,線程B執行相同的操作。現在var1已經增加了兩次,每次CPU緩存一次。
如果這些增加操作按順序執行,則變量count將增加兩次並將”原始值+ 2”後產生的新值寫回主存儲器。
但是,兩個增加操作同時執行卻沒有進行適當的同步。無論線程A和B中的哪一個將其更新版本count寫回主到存儲器,更新的值將僅比原始值多1,儘管有兩個增加操作。
該圖説明了如上所述的競爭條件問題的發生:

要解決此問題,您可以使用Java synchronized塊。同步塊保證在任何給定時間只有一個線程可以進入代碼的臨界區。同步塊還保證在同步塊內訪問的所有變量都將從主存儲器中讀入,當線程退出同步塊時,所有更新的變量將再次刷新回主存儲器,無論變量是否聲明為volatile。
JMM存在的必要性
在明白了Java內存區域劃分、硬件內存架構、Java多線程的實現原理與Java內存模型的具體關係後,接着來談談Java內存模型存在的必要性。
由於JVM運行程序的實體是線程,而每個線程創建時JVM都會為其創建一個工作內存(有些地方稱為棧空間),用於存儲線程私有的數據,線程與主內存中的變量操作必須通過工作內存間接完成,主要過程是將變量從主內存拷貝的每個線程各自的工作內存空間,然後對變量進行操作,操作完成後再將變量寫回主內存,如果存在兩個線程同時對一個主內存中的實例對象的變量進行操作就有可能誘發線程安全問題。
如下圖,主內存中存在一個共享變量x,現在有A和B兩條線程分別對該變量x=1進行操作,A/B線程各自的工作內存中存在共享變量副本x。
假設現在A線程想要修改x的值為2,而B線程卻想要讀取x的值,那麼B線程讀取到的值是A線程更新後的值2還是更新前的值1呢?答案是,不確定,即B線程有可能讀取到A線程更新前的值1,也有可能讀取到A線程更新後的值2,這是因為工作內存是每個線程私有的數據區域,而線程A變量x時,
首先是將變量從主內存拷貝到A線程的工作內存中,然後對變量進行操作,操作完成後再將變量x寫回主內,而對於B線程的也是類似的,這樣就有可能造成主內存與工作內存間數據存在一致性問題,假如A線程修改完後正在將數據寫回主內存,而B線程此時正在讀取主內存,即將x=1拷貝到自己的工作內存中,
這樣B線程讀取到的值就是x=1,但如果A線程已將x=2寫回主內存後,B線程才開始讀取的話,那麼此時B線程讀取到的就是x=2,但到底是哪種情況先發生呢?這是不確定的,這也就是所謂的線程安全問題。

為了解決類似上述的問題,JVM定義了一組規則,通過這組規則來決定一個線程對共享變量的寫入何時對另一個線程可見,這組規則也稱為Java內存模型(即JMM),JMM是圍繞着程序執行的原子性、有序性、可見性展開的,下面我們看看這三個特性。
本文由
傳智教育博學谷狂野架構師教研團隊發佈。如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力。轉載請註明出處!
- ElasticSearch還能性能調優,漲見識、漲見識了!!!
- 【必須收藏】別再亂找TiDB 集羣部署教程了,這篇保姆級教程來幫你!!| 博學谷狂野架構師
- 【建議收藏】7000 字的TIDB保姆級簡介,你見過嗎
- Tomcat架構設計剖析 | 博學谷狂野架構師
- 你可能不那麼知道的Tomcat生命週期管理 | 博學谷狂野架構師
- 大哥,這是併發不是並行,Are You Ok?
- 為啥要重學Tomcat?| 博學谷狂野架構師
- 這是一篇純講SQL語句優化的文章!!!| 博學谷狂野架構師
- 捲起來!!!看了這篇文章我才知道MySQL事務&MVCC到底是啥?
- 為什麼99%的程序員都做不好SQL優化?
- 如何搞定MySQL鎖(全局鎖、表級鎖、行級鎖)?這篇文章告訴你答案!太TMD詳細了!!!
- 【建議收藏】超詳細的Canal入門,看這篇就夠了!!!
- 從菜鳥程序員到高級架構師,竟然是因為這個字final
- 為什麼95%的Java程序員,都是用不好Synchronized?
- 99%的Java程序員者,都敗給這一個字!
- 8000 字,就説一個字Volatile
- 98%的程序員,都沒有研究過JVM重排序和順序一致性
- 來一波騷操作,Java內存模型
- 時隔多年,這次我終於把動態代理的源碼翻了個地兒朝天
- 再有人問你分佈式事務,把這篇文章砸過去給他