AI 影評家: 用 Hugging Face 模型打造一個電影評分機器人
本文為社群成員 Jun Chen 為 百姓 AI 和 Hugging Face 聯合舉辦的黑客鬆所撰寫的教程文件,歡迎你閱讀今天的第二條推送了解和參加本次黑客鬆活動。文內含有較多連結,我們不再一一貼出,請 點選這裡 檢視渲染後的 Notebook 檔案。
隨著人工智慧和大模型 ChatGPT 的持續火爆,越來越多的個人和創業者都想並且可以通過自己建立人工智慧 APP 來探索這個新興領域的機會。只要你有一個想法,你就可以通過各種開放社群和資源實現一些簡單功能,滿足特定領域或者使用者的需求。
試想現在有一部新的電影剛剛上線了,我們和朋友在家熱烈的討論著這部新的電影,這些都是非常有價值的電影評價的資訊,不過估計這個時候很少有人會特地去登陸自己的豆瓣賬號再去發表這些剛剛的評論,如果有一個電影評論機器人可以自動收集這些評論並且根據評論打分,然後自動上傳到制定的電影評論網站呢?再比如,我們在某個餐廳吃飯,我們只用對著手機說幾句話,我們的評分就自動上傳到大眾點評呢?我們來試試如何實現這樣一個小小的機器人吧!
在本教程中,我們將探索如何使用 Hugging Face 資源來 Finetune 一個模型且構建一個電影評分機器人。我們將向大家展示如何整合這些資源,讓你的聊天機器人具備總結評論並給出評分的功能。我們會用通俗易懂的語言引導你完成這個有趣的專案!
為了可以簡單的說明實現的步驟,我們簡化這個【電影打分機器人】的實現方法:
- App 直接收集來自
input的text作為輸入,有興趣的小夥伴們可以研究一下如何接入到語音,Whisper to ChatGPT 是一個很有好的例子。 - App 不會實現自動上傳評價到特定網站。
第一步: 訓練電影評價打分模型
首先我們需要一個可以看懂評論且給評論打分的模型,這個例子選用的是利用資料集 IMDb 微調 DistilBERT,微調後的模型可以預測一個電影的評論是正面的還是負面的且給出評分(五分滿分)。
當然大家可以根據各自的需求找到不同的資料集來 Finetune 模型,也可以使用不同的基礎模型,Hugging Face 上提供了很多可選項。
本任務使用或間接使用了下面模型的架構:
ALBERT, BART, BERT, BigBird, BigBird-Pegasus, BLOOM, CamemBERT, CANINE, ConvBERT, CTRL, Data2VecText, DeBERTa, DeBERTa-v2, DistilBERT, ELECTRA, ERNIE, ErnieM, ESM, FlauBERT, FNet, Funnel Transformer, GPT-Sw3, OpenAI GPT-2, GPT Neo, GPT-J, I-BERT, LayoutLM, LayoutLMv2, LayoutLMv3, LED, LiLT, Longformer, LUKE, MarkupLM, mBART, Megatron-BERT, MobileBERT, MPNet, MVP, Nezha, Nyströmformer, OpenAI GPT, OPT, Perceiver, PLBart, QDQBert, Reformer, RemBERT, RoBERTa, RoBERTa-PreLayerNorm, RoCBert, RoFormer, SqueezeBERT, TAPAS, Transformer-XL, XLM, XLM-RoBERTa, XLM-RoBERTa-XL, XLNet, X-MOD, YOSO
# Transformers installation
! pip install transformers datasets evaluate
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+http://github.com/huggingface/transformers.git
在使用本示例前請安裝如下庫檔案:
pip install transformers datasets evaluate
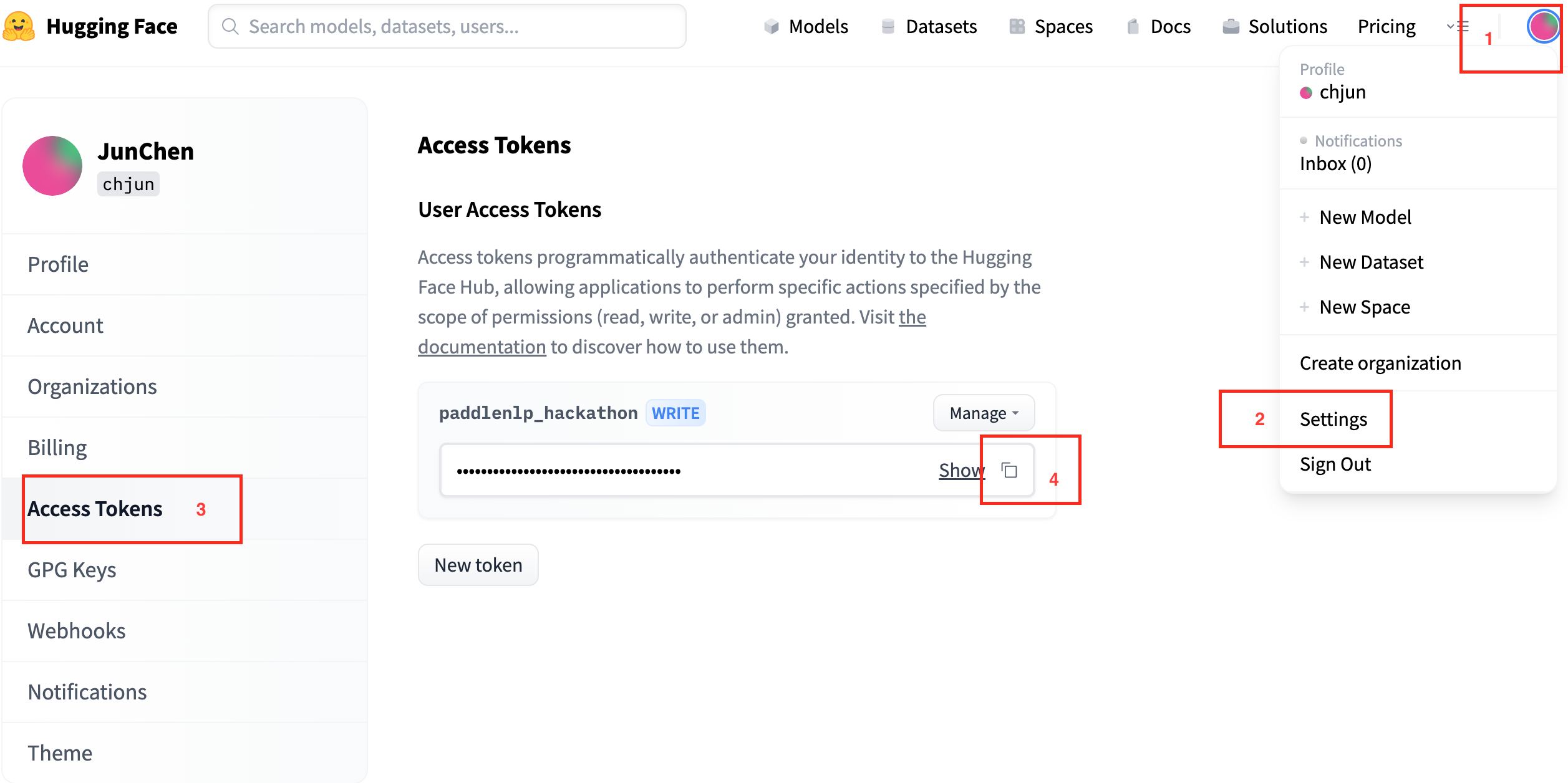
我們建議登陸 Hugging Face 賬戶進行操作,這樣就可以方便的上傳和分享自己建立的模型。當有彈框時請輸入個人的 token 。根據下圖找到我們自己的 Hugging Face Tokens。
from huggingface_hub import notebook_login
notebook_login()
Token is valid.
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /root/.cache/huggingface/token
Login successful
載入 IMDb 資料集
開始從 Datasets 庫中載入 IMDb 資料集 🤗 :
from datasets import load_dataset
imdb = load_dataset("imdb")
Downloading builder script: 0%| | 0.00/4.31k [00:00<?, ?B/s]
Downloading metadata: 0%| | 0.00/2.17k [00:00<?, ?B/s]
Downloading readme: 0%| | 0.00/7.59k [00:00<?, ?B/s]
Downloading and preparing dataset imdb/plain_text to /root/.cache/huggingface/datasets/imdb/plain_text/1.0.0/d613c88cf8fa3bab83b4ded3713f1f74830d1100e171db75bbddb80b3345c9c0...
Downloading data: 0%| | 0.00/84.1M [00:00<?, ?B/s]
Generating train split: 0%| | 0/25000 [00:00<?, ? examples/s]
Generating test split: 0%| | 0/25000 [00:00<?, ? examples/s]
Generating unsupervised split: 0%| | 0/50000 [00:00<?, ? examples/s]
Dataset imdb downloaded and prepared to /root/.cache/huggingface/datasets/imdb/plain_text/1.0.0/d613c88cf8fa3bab83b4ded3713f1f74830d1100e171db75bbddb80b3345c9c0. Subsequent calls will reuse this data.
0%| | 0/3 [00:00<?, ?it/s]
檢查一下資料是否載入成功:
imdb["test"][0]
{'text': 'I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn\'t match the background, and painfully one-dimensional characters cannot be overcome with a \'sci-fi\' setting. (I\'m sure there are those of you out there who think Babylon 5 is good sci-fi TV. It\'s not. It\'s clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It\'s really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it\'s rubbish as they have to always say "Gene Roddenberry\'s Earth..." otherwise people would not continue watching. Roddenberry\'s ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.',
'label': 0}
在這個資料集中有兩個欄位:
text: 電影評論。label: 0 或者 1。0代表負面評價、1代表正面評價。
輸入資料預處理
這一步是載入 DistilBERT tokenizer,並建立一個預處理函式來預處理 text,且保證輸入不會大於 DistilBERT 的最長輸入要求:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
Downloading (…)okenizer_config.json: 0%| | 0.00/28.0 [00:00<?, ?B/s]
Downloading (…)lve/main/config.json: 0%| | 0.00/483 [00:00<?, ?B/s]
Downloading (…)solve/main/vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading (…)/main/tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]
使用 🤗 Datasets map 函式把預處理函式應用到整個資料集中。 我們還可以使用 batched=True 來加速 map:
tokenized_imdb = imdb.map(preprocess_function, batched=True)
使用 DataCollatorWithPadding 來生成資料包,這樣動態的填充資料包到最大長度能夠更加節省資源。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
模型評測函式
選擇一個合適的測評指標是至關重要的。大家可以直接呼叫庫函式 🤗 Evaluate 裡的各種測評指標。在這個例子中,我們使用了accuracy,瞭解更多請 檢視文件快速上手:
import evaluate
accuracy = evaluate.load("accuracy")
Downloading builder script: 0%| | 0.00/4.20k [00:00<?, ?B/s]
這裡我們需要定義一個可以 計算 指標的函式:
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
訓練模型
在開始訓練前,需要定義一個id到標籤和標籤到id的 map :
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}
如果不熟悉如何使用 Trainer 來訓練模型, 可以檢視更詳細的教程!
好了,一切已經準備就緒!我們可以使用 AutoModelForSequenceClassification 載入 DistilBERT 模型:
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
)
Downloading pytorch_model.bin: 0%| | 0.00/268M [00:00<?, ?B/s]
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_layer_norm.bias', 'vocab_transform.bias', 'vocab_transform.weight', 'vocab_projector.weight', 'vocab_layer_norm.weight', 'vocab_projector.bias']
- This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['pre_classifier.bias', 'classifier.weight', 'classifier.bias', 'pre_classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
接下來只有三步需要完成:
- 在 TrainingArguments 中定義模型超參,只有
output_dir引數是必須的。我們可以設定push_to_hub=True來直接上傳訓練好的模型(如果已經登陸了Hugging Face)。在每一個訓練段,Trainer 都會評測模型的 accuracy 和儲存此節點。 - 傳入超引數,模型,資料集和評測函式到 Trainer。
- 呼叫 train() 來微調模型。
training_args = TrainingArguments(
output_dir="my_awesome_model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb["train"],
eval_dataset=tokenized_imdb["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
Cloning http://huggingface.co/chenglu/my_awesome_model into local empty directory.
WARNING:huggingface_hub.repository:Cloning http://huggingface.co/chenglu/my_awesome_model into local empty directory.
/usr/local/lib/python3.9/dist-packages/transformers/optimization.py:391: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
You're using a DistilBertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.238700 | 0.188998 | 0.927600 |
| 2 | 0.151200 | 0.233457 | 0.93096 |
TrainOutput(global_step=3126, training_loss=0.20756478166244613, metrics={'train_runtime': 3367.9454, 'train_samples_per_second': 14.846, 'train_steps_per_second': 0.928, 'total_flos': 6561288258498624.0, 'train_loss': 0.20756478166244613, 'epoch': 2.0})
訓練結束後大家就可以通過 push_to_hub() 方法 上傳模型到 Hugging Face 上了,這樣所有人都可以看見並且使用你的模型了。
第二步:模型上傳到 Hugging Face
trainer.push_to_hub()
remote: Scanning LFS files of refs/heads/main for validity...
remote: LFS file scan complete.
To http://huggingface.co/YOURUSERNAME/my_awesome_model
beedd7e..07a7f56 main -> main
WARNING:huggingface_hub.repository:remote: Scanning LFS files of refs/heads/main for validity...
remote: LFS file scan complete.
To http://huggingface.co/YOURUSERNAME/my_awesome_model
beedd7e..07a7f56 main -> main
To http://huggingface.co/YOURUSERNAME/my_awesome_model
07a7f56..94dee6f main -> main
WARNING:huggingface_hub.repository:To http://huggingface.co/YOURUSERNAME/my_awesome_model
07a7f56..94dee6f main -> main
'http://huggingface.co/YOURUSERNAME/my_awesome_model/commit/07a7f56bd4c32596537816ff2fed565f29468f17'
大家可以在 PyTorch Notebook 或者 TensorFlow Notebook 檢視更加詳細的關於如何微調模型的教程。
第三步:建立自己的 App
恭喜大家已經獲得了自己的模型!下面我們可以在 Hugging Face 中建立一個自己的 App 了。
建立新的 Hugging Face Space 應用
! pip install gradio torch
在 Spaces 主頁上點選 Create new Space 。
新增 App 邏輯
在 app.py 檔案中接入以下程式碼:
import gradio as gr
from transformers import pipeline
import torch
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}
# 匯入 HuggingFace 模型 我們剛剛訓練好而且上傳成功的模型 chjun/my_awesome_model
classifier = pipeline("sentiment-analysis", model="chjun/my_awesome_model")
# input:輸入文字
def predict(inputs):
label_score = classifier(inputs)
scaled = 0
if label_score[0]["label"] == "NEGATIVE":
scaled = 1 - label_score[0]["score"]
else:
scaled = label_score[0]["score"]
# 解碼返回值得到輸出
return round(scaled * 5)
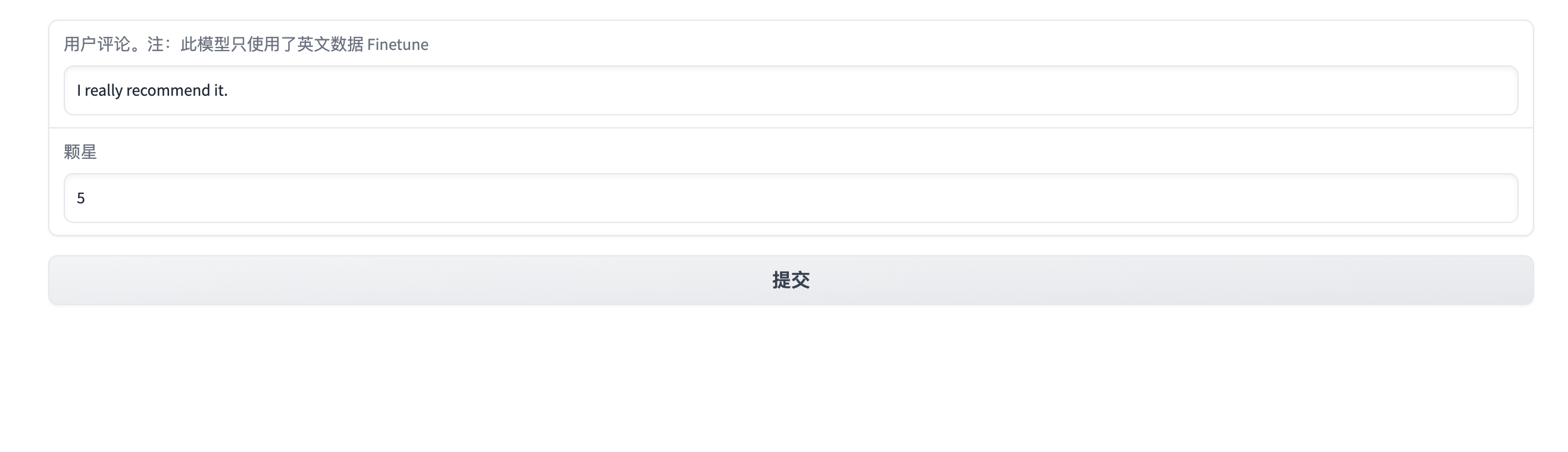
with gr.Blocks() as demo:
review = gr.Textbox(label="使用者評論。注:此模型只使用了英文資料 Finetune")
output = gr.Textbox(label="顆星")
submit_btn = gr.Button("提交")
submit_btn.click(fn=predict, inputs=review, outputs=output, api_name="predict")
demo.launch(debug=True)
成功執行後,大家應該可以看見下面類似的介面:
注意,我們需要把必須的庫檔案放在 requirements.txt 中,例如這個 App 需要:
gradio
torch
transformers
另外,由於我們在示範中只跑了 2 個 epoch,所以最終模型 accuracy 不高。大家可以根據自己的情況調整超參和訓練時長。
上傳到 Hugging Face Spaces
$git add app.py
$git commit -m "Add application file"
$git push
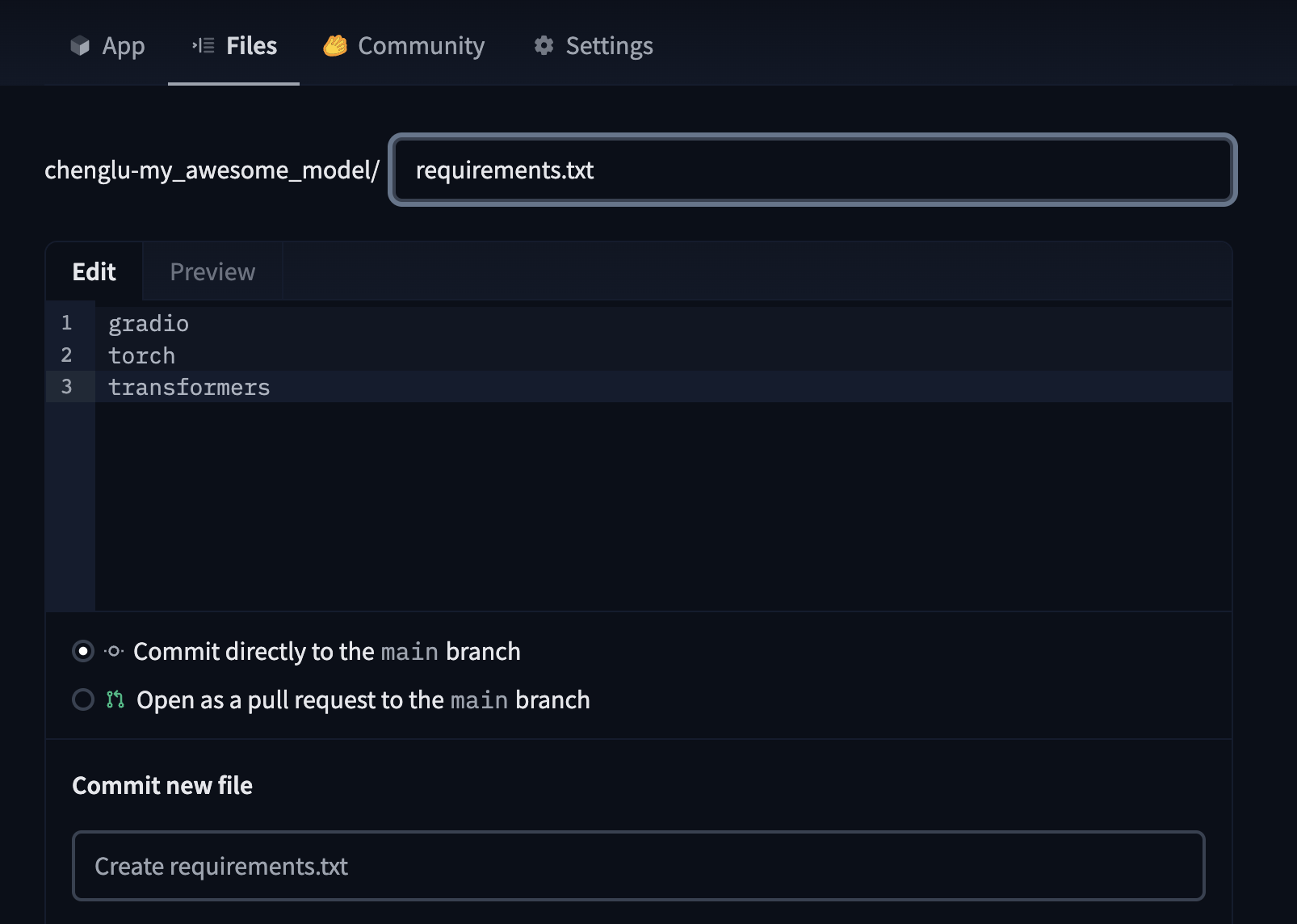
而且 app.py 以及 requirements.txt 檔案,都可以在 Hugging Face Hub 的介面上直接操作,如下圖:
第四步: 完成機器人開發
現在,你已經建立了一個能夠根據電影評論給電影打分的機器人。當你向機器人提問時,它會使用 Hugging Face 的模型進行情感分析,根據情感分析結果給出一個評分。
chjun/movie_rating_bot 是根據以上教程完成的一個機器人 App,大家也可以直接複製這一個 Space 應用,並在此基礎上更改開發。
點選 submit,與你的 AI 夥伴互動吧!這個專案僅僅是一個起點,你可以根據自己的需求和興趣進一步完善這個聊天機器人,使其具備更多有趣的功能。
第五步: 接入 BaixingAI 機器人廣場
還有更激動人心的一步,我們可以把機器人介面根據 BaixingAI 機器人廣場需求 擴充套件,讓我們自己建立的機器人可以去和其他機器人交流對話,以下是程式碼示範:
import gradio as gr
from transformers import pipeline
import torch
# 匯入 HuggingFace 模型 我們剛剛訓練好而且上傳成功的模型 chjun/my_awesome_model
classifier = pipeline("sentiment-analysis", model="chjun/my_awesome_model")
# input:輸入文字
def predict(user_review, qid, uid):
label_score = classifier(user_review)
scaled = 0
if label_score[0]["label"] == "NEGATIVE":
scaled = 1 - label_score[0]["score"]
else:
scaled = label_score[0]["score"]
# 解碼返回值得到輸出
return str(round(scaled * 5))
# user_review: 使用者評價
# qid:當前訊息的唯一標識。例如 `'bxqid-cManAtRMszw...'`。由平臺生成並傳遞給機器人,以便機器人區分單個問題(寫日誌、追蹤除錯、非同步回撥等)。同步呼叫可忽略。
# uid:使用者的唯一標識。例如`'bxuid-Aj8Spso8Xsp...'`。由平臺生成並傳遞給機器人,以便機器人區分使用者。可被用於實現多輪對話的功能。
demo = gr.Interface(
fn=predict,
inputs=["text","text","text"],
outputs="text",
)
demo.launch()
更多詳情請參考 Hugging Face baixing Spaces。
未來已來,各位 Hackathon 參賽者們都是探索者,預祝大家一切順利!
- 在一張 24 GB 的消費級顯示卡上用 RLHF 微調 20B LLMs
- 如何評估大語言模型
- 千億引數開源大模型 BLOOM 背後的技術
- Kakao Brain 的開源 ViT、ALIGN 和 COYO 文字-圖片資料集
- AI 影評家: 用 Hugging Face 模型打造一個電影評分機器人
- 我的語言模型應該有多大?
- Hugging Face 每週速遞: Chatbot Hackathon;FLAN-T5 XL 微調;構建更安全的 LLM
- AI 大戰 AI,一個深度強化學習多智慧體競賽系統
- Hugging Face 每週速遞: ChatGPT API 怎麼用?我們幫你搭好頁面了
- 深入瞭解視覺語言模型
- CPU推理|使用英特爾 Sapphire Rapids 加速 PyTorch Transformers
- 大語言模型: 新的摩爾定律?
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 在低程式碼開發平臺 ILLA Cloud 中使用 Hugging Face 上的模型
- 瞭解 Transformers 是如何“思考”的
- 第 1 天|基於 AI 進行遊戲開發:5 天建立一個農場遊戲!
- 加速 Document AI (文件智慧) 發展
- 一文帶你入門圖機器學習
- 解讀 ChatGPT 背後的技術重點:RLHF、IFT、CoT、紅藍對抗