从 1 秒到 10 毫秒!在 APISIX 中减少 Prometheus 请求阻塞
本文介绍了 Prometheus 插件造成长尾请求现象的原因,以及如何解决这个问题。
作者屠正松,Apache APISIX PMC Member。
现象
在 APISIX 社区中,曾有部分用户陆续反馈一种神秘现象:部分请求延迟较长。具体表现为:当流量请求进入一个正常部署的 APISIX 集群时,偶尔会出现部分请求有 1 ~ 2 秒的延迟。用户的 QPS 规模大概在 1 万,但是这种异常请求非常少见,每隔几分钟就会出现 1 ~ 3 次。一些用户在 issue 中也提供了捕获到的延迟较长的请求。从这些截图中可以看出,确实有请求延迟较高,甚至可以达到秒级别。


这种现象伴随着另一种现象:某个 worker 进程的 CPU 占用率达到了 100%。

开发团队通过不同渠道与这些反馈的用户沟通得知,这个现象发生的条件是:
- 开启 prometheus 插件,并且有 Prometheus Exporter 访问 APISIX 的 endpoint
/apisix/prometheus/metrics来采集指标; - prometheus 插件统计的 metrics 的数量达到一定规模,通常是上万级别;
这个现象是在业界称为 "长尾请求",是指在一个请求群体中,大部分请求响应时间较短,但有少部分请求响应时间较长的情况。它可能是由于后端系统的性能瓶颈、资源不足或其他原因导致的。它不是一个致命的 bug,但是它严重影响了终端用户的体验。
抽丝剥茧
APISIX 基于一个开源的 Lua 库 nginx-lua-prometheus 开发了 Prometheus 插件,提供跟踪和收集 metrics 的功能。当 Prometheus Exporter 访问 APISIX 暴露的 Prometheus 指标的 endpoint 时,APISIX 会调用 nginx-lua-prometheus 提供的函数来暴露 metrics 的计算结果。
开发团队从社区用户,企业用户等渠道收集汇总了长尾请求发生的条件,基本定位了问题所在:nginx-lua-prometheus 中用于暴露 metrics 指标的函数 prometheus:metric_data()。
不过这只是初步推断,还需要直接的证据来证明长尾请求与此有关,并且需要搞清楚以下问题:
- 这个函数具体做了什么?
- 这个函数为什么会造成长尾请求现象?
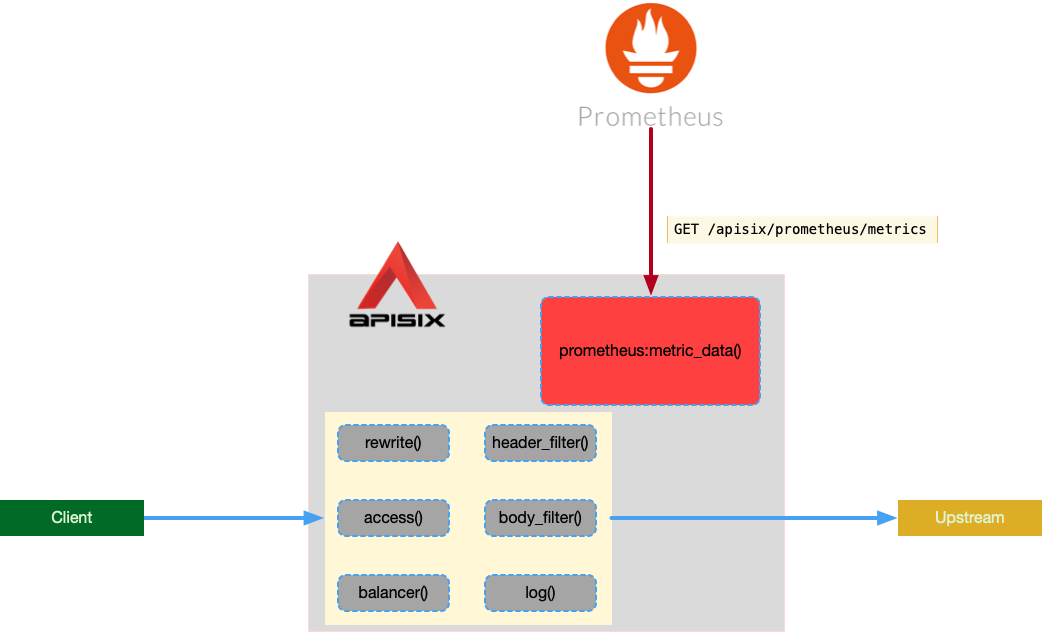
开发团队构造了本地复现环境,这个复现环境主要模拟以下场景:
- 模拟客户端发送正常请求,被 APISIX 代理到上游
- 模拟 Prometheus Exporter 每隔 5 秒访问
/apisix/prometheus/metrics,触发 APISIX 运行prometheus:metric_data()函数
复现环境示意图:
在执行复现测试时,我们会观察 wrk2 的测试结果中的 P100 等指标来确认是否发生了长尾请求现象,并且会对运行中的 APISIX 生成火焰图,来观测发生长尾请求时,CPU 资源消耗在哪里。
wrk2 的测试结果如下:
Latency Distribution (HdrHistogram - Uncorrected Latency (measured without taking delayed starts into account))
50.000% 1.13ms
75.000% 2.56ms
90.000% 4.82ms
99.000% 14.70ms
99.900% 27.95ms
99.990% 74.75ms
99.999% 102.78ms
100.000% 102.78ms
根据这个测试结果可以得到结论:在测试期间,99% 的请求在 14.70 毫秒内完成了,但是还有很少一部分请求消耗了 100 多毫秒。并且我们用 metrics 数量作为变量,进行了多次测试,发现 metrics 数量与 P100 的延迟呈线性增长。如果 metrics 达到 10 万级别,P100 将达到秒级别。
生成的火焰图如下:

从火焰图的函数堆栈可以看到,prometheus:metric_data() 占据了最长的横轴宽度,这证明了大量 CPU 消耗在这里。这也直接证明了 prometheus:metric_data() 造成长尾请求现象。
下面我们来简单分析一下 prometheus:metric_data() 函数做了什么。prometheus:metric_data() 将会从共享内存中获取指标,对指标进行分类,并加工成 Prometheus 兼容的文本格式。在这个过程中,会对所有 metrics 按照字典序进行排序,会用正则处理 metrics 的前缀。根据经验,这些都是非常昂贵的操作。
不够完美的优化
当定位到有问题的代码后,下一步就是结合火焰图,详细分析代码,寻找优化空间。
从火焰图可以定位到 fix_histogram_bucket_labels 函数。通过 review 这个函数,我们发现了两个比较敏感的函数:string:match 和 string:gsub。这两个函数都不能被 LuaJIT 所 JIT 编译,只能解释执行。
LuaJIT 是一个针对 Lua 编程语言的 JIT 编译器,可以将 Lua 代码编译成机器码并运行。这相比于使用解释器来运行 Lua 代码,可以提供更高的性能。 使用 LuaJIT 运行 Lua 代码的一个优势是,它可以大幅提升代码的执行速度。这使得 APISIX 在处理大量请求时可以保持较低的延迟,并且可以在高并发环境下表现出较好的性能。 关于 LuaJIT 的更多介绍可以参考:什么是 JIT?
因此不能被 LuaJIT 编译的代码必然会成为潜在的性能瓶颈。
我们整理以上信息并提交了 issue: optimize the long-tail request phenomenon 到 nginx-lua-prometheus,与这个项目的作者 knyar 一起探讨可以优化的空间。knyar 响应很及时,我们沟通后明确了可以优化的点。于是提交了 PR:chore: use ngx.re.match instead of string match to improve performance 进行优化。 在这个 PR 中,主要完成了:
- 用
ngx.re.match替代string:match - 用
ngx.re.gsub替代string:gsub
在完成这个优化后,我们其实非常理性地知道,这个优化只能提升一些性能,但不能根本解决问题。根本问题是:
Nginx 是一种多进程单线程的架构。所有的 worker 进程都会监听 TCP 连接,但一旦连接进入了某个 worker 进程,就不能再被迁移到其他 worker 进程去处理了。 这意味着,如果某个 worker 进程非常忙碌,那么该 worker 进程内的其他连接就可能无法及时获得处理。另一方面,进程内的单线程模型意味着,所有 CPU 密集型和 IO 密集型的任务都必须按顺序执行。如果某个任务执行时间较长,那么其他任务就可能被忽略,导致任务处理时间不均匀。
prometheus:metric_data() 占据了大量的 CPU 时间片进行计算,挤压了处理正常请求的 CPU 资源。这也是为什么会看到某个 worker 进程的 CPU 占用率达到 100%。
基于这个问题,我们在完成上述优化后继续分析,抓取了火焰图:

上面火焰图 builtin#100 表示的是 luajit/lua 的库函数(比如 string.find 这种),可以通过 http://github.com/openresty/openresty-devel-utils/blob/master/ljff.lua 这个项目里的脚本来得到对应的函数名称。
使用方式:
$ luajit ljff.lua 100
FastFunc table.sort
由于计算 metrics 时占用了过量的 CPU,所以我们考虑在计算 metrics 时适当让出 CPU 时间片。
对于 APISIX 来说,处理正常请求的优先级是最高的,CPU 资源应当向此倾斜,而 prometheus:metric_data() 只会影响 Prometheus Exporter 获取指标时的效率。
在 OpenResty 世界,有一个隐秘的让出 CPU 时间片的方式:ngx.sleep(0) 。我们在 prometheus:metric_data() 中引入这种方式,当处理所有的 metrics 时,每处理固定数目(比如 200 个)的 metrics 后让出 CPU 时间片,这样新进来的请求将有机会得到处理。
我们提交了引入这个优化的 PR:feat: performance optimization。
在我们的测试场景中,当 metrics 的总数量达到 10 万级别时,引入这个优化之前用 wrk2 测试得到的结果:
Latency Distribution (HdrHistogram - Uncorrected Latency (measured without taking delayed starts into account))
50.000% 10.21ms
75.000% 12.03ms
90.000% 13.25ms
99.000% 92.80ms
99.900% 926.72ms
99.990% 932.86ms
99.999% 934.40ms
100.000% 934.91ms
引入这个优化后,用 wrk2 测试得到的结果:
Latency Distribution (HdrHistogram - Uncorrected Latency (measured without taking delayed starts into account))
50.000% 4.34ms
75.000% 12.81ms
90.000% 16.12ms
99.000% 82.75ms
99.900% 246.91ms
99.990% 349.44ms
99.999% 390.40ms
100.000% 397.31ms
可以看到 P100 的指标大约是优化前的 1/3 ~ 1/2。
不过这并没有完美解决这个问题,通过分析优化后的火焰图:
可以直接看到 builtin#100(即 table.sort) 和 builtin#92(即 string.format)等,仍然占据了相当宽度的横轴,这是因为:
prometheus:metric_data()中首先会对所有的 metrics 调用table.sort进行排序,当 metrics 到 10 万级别时,相当于对 10 万个字符串进行排序,并且table.sort不可以被ngx.sleep(0)中断。- 使用
string.format的地方,以及fix_histogram_bucket_labels无法优化,经过与 knyar 交流后得知,这些步骤必须存在以保证prometheus:metric_data()可以产出格式正确的 metrics。
至此,代码层面的优化手段已经用完了,但遗憾的是,还是没有完美解决问题。P100 的指标仍然有明显的延迟。
怎么办?
让我们再回到核心问题:prometheus:metric_data() 占据了大量的 CPU 时间片进行计算,挤压了处理正常请求的 CPU 资源。
在 Linux 系统中,CPU 分配时间片的单位是线程还是进程?准确来说是线程,线程才是实际的工作单元。不过 Nginx 是多进程单线程的架构,实际在每个进程中只有一个线程。
此时我们会想到一个优化方向:将 prometheus:metric_data() 转移到其他线程,或者说进程。于是我们调研了两个方向:
- 用
ngx.run_worker_thread来运行prometheus:metric_data()的计算任务,相当于将 CPU 密集型任务交给线程池; - 用单独的进程来处理
prometheus:metric_data()的计算任务,这个进程不会处理正常请求。
经过 PoC 后,我们否定了方案 1,采用了方案 2。否定方案 1 是因为 ngx.run_worker_thread 只适合运行与请求无关的计算任务,而 prometheus:metric_data() 明显是与请求有关的。
方案 2 的实现:让 privileged agent(特权进程)来处理 prometheus:metric_data()。但是特权进程本身不监听任何端口,也不会处理任何请求。因此,我们需要对特权进程进行一些改造,让它监听端口。
最终,我们通过 feat: allow privileged agent to listen port 和 feat(prometheus): support collect metrics works in the priviledged agent 实现了方案 2。
我们使用带上了这个优化的 APISIX 来测试,发现 P100 的指标延迟已经降低到合理的范围内,长尾请求现象也不存在了。
Latency Distribution (HdrHistogram - Uncorrected Latency (measured without taking delayed starts into account))
50.000% 3.74ms
75.000% 4.66ms
90.000% 5.77ms
99.000% 9.99ms
99.900% 13.41ms
99.990% 16.77ms
99.999% 18.38ms
100.000% 18.40ms
这个方案有些巧妙,也解决了最核心的问题。我们在生产环境中观察并验证了这个方案,它消除了长尾请求现象,也没有造成其他额外的异常。 与此同时,我们发现社区中也有类似的修复方案,有兴趣的话可以延伸阅读:如何修改 Nginx 源码实现 worker 进程隔离。
展望
在我们修复这个问题的时候,产生了一个新的思考:nginx-lua-prometheus 这个开源库适合 APISIX 吗?
我们在 APISIX 侧解决了 prometheus:metric_data() 的问题,同时,我们也发现了 nginx-lua-prometheus 存在的其他问题,并且修复了。比如修复内存泄漏,以及修复 LRU 缓存淘汰。
nginx-lua-prometheus 刚开始是被设计为 Nginx 使用,并不是为了 OpenResty 以及基于 OpenResty 的应用所设计的。OpenResty 生态内没有比 nginx-lua-prometheus 更成熟的对接 Prometheus 生态的开源项目,因此 nginx-lua-prometheus 不断被开源社区的力量推动成为适合 OpenResty 生态的方向。
也许我们应该将视野放得更开阔一些,寻找不用修改 APISIX 底层的方式来对接 Prometheus 生态。比如设计一个更适合 APISIX 的依赖库,或者用某种方式对接 Prometheus 生态中成熟的项目,将收集和计算 metrics 的过程转移到那些成熟的项目中。
后续
该问题已经在 Apache APISIX 3.1 版本中修复。http://github.com/apache/apisix/pull/8434
关于 API7.ai 与 APISIX
API7.ai 是一家提供 API 处理和分析的开源基础软件公司,于 2019 年开源了新一代云原生 API 网关 -- APISIX 并捐赠给 Apache 软件基金会。此后,API7.ai 一直积极投入支持 Apache APISIX 的开发、维护和社区运营。与千万贡献者、使用者、支持者一起做出世界级的开源项目,是 API7.ai 努力的目标。
- 什么是 LuaJIT?为什么 Apache APISIX 选择了 LuaJIT?
- 为什么 APISIX Ingress 是比 Emissary-ingress 更好的选择?
- 无需二次开发,SOAP-to-REST 简化企业用户的业务迁移和整合
- API 网关日志的价值,你了解多少?
- API Gateway vs Load Balancer:选择适合你的网络流量管理组件
- 从 1 秒到 10 毫秒!在 APISIX 中减少 Prometheus 请求阻塞
- 微服务为什么要用到 API 网关?
- 备战一年半,我们让最火的开源网关上了云
- APISIX 是怎么保护用户的敏感数据不被泄露的?
- 如何使用 Kubernetes 实现应用程序的弹性伸缩
- 详解 APISIX Lua 动态调试插件 inspect
- 借助 APISIX Ingress,实现与注册中心的无缝集成
- 多云和混合云场景下的 API 管理:挑战与选择
- 从 HTTP 到 gRPC:APISIX 中 etcd 操作的迁移之路
- 关于 OAuth 你又了解哪些?