瞭解 Transformers 是如何“思考”的
Transformer 模型是 AI 系統的基礎。已經有了數不清的關於 "Transformer 如何工作" 的核心結構圖表。
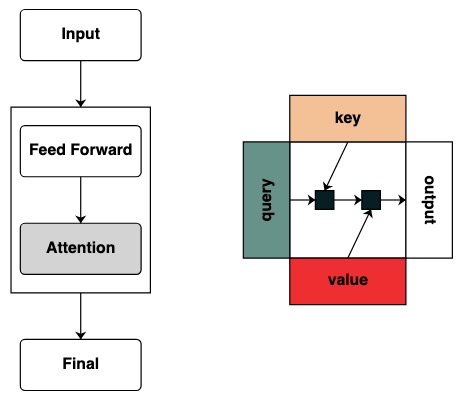
但是這些圖表沒有提供任何直觀的計算該模型的框架表示。當研究者對於 Transformer 如何工作抱有興趣時,直觀的獲取他執行的機制變得十分有用。
Thinking Like Transformers 這篇論文中提出了 transformer 類的計算框架,這個框架直接計算和模仿 Transformer 計算。使用 RASP 程式語言,使每個程式編譯成一個特殊的 Transformer。
在這篇部落格中,我用 Python 復現了 RASP 的變體 (RASPy)。該語言大致與原始版本相當,但是多了一些我認為很有趣的變化。通過這些語言,作者 Gail Weiss 的工作,提供了一套具有挑戰性的有趣且正確的方式可以幫助瞭解其工作原理。
!pip install git+http://github.com/srush/RASPy
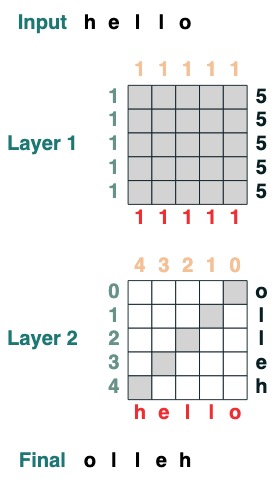
在說起語言本身前,讓我們先看一個例子,看看用 Transformers 編碼是什麼樣的。這是一些計算翻轉的程式碼,即反向輸入序列。程式碼本身用兩個 Transformer 層應用 attention 和數學計算到達這個結果。
def flip():
length = (key(1) == query(1)).value(1)
flip = (key(length - indices - 1) == query(indices)).value(tokens)
return flip
flip()
文章目錄
- 第一部分:Transformers 作為程式碼
- 第二部分:用 Transformers 編寫程式
Transformers 作為程式碼
我們的目標是定義一套計算形式來最小化 Transformers 的表達。我們將通過類比,描述每個語言構造及其在 Transformers 中的對應。(正式語言規範請在本文底部檢視論文全文連結)。
這個語言的核心單元是將一個序列轉換成相同長度的另一個序列的序列操作。我後面將其稱之為 transforms。
輸入
在一個 Transformer 中,基本層是一個模型的前饋輸入。這個輸入通常包含原始的 token 和位置資訊。
在程式碼中,tokens 的特徵表示最簡單的 transform,它返回經過模型的 tokens,預設輸入序列是 "hello":
tokens

如果我們想要改變 transform 裡的輸入,我們使用輸入方法進行傳值。
tokens.input([5, 2, 4, 5, 2, 2])

作為 Transformers,我們不能直接接受這些序列的位置。但是為了模擬位置嵌入,我們可以獲取位置的索引:
indices

sop = indices
sop.input("goodbye")

前饋網路
經過輸入層後,我們到達了前饋網路層。在 Transformer 中,這一步可以對於序列的每一個元素獨立的應用數學運算。
在程式碼中,我們通過在 transforms 上計算表示這一步。在每一個序列的元素中都會進行獨立的數學運算。
tokens == "l"

結果是一個新的 transform,一旦重構新的輸入就會按照重構方式計算:
model = tokens * 2 - 1
model.input([1, 2, 3, 5, 2])

該運算可以組合多個 Transforms,舉個例子,以上述的 token 和 indices 為例,這裡可以類別 Transformer 可以跟蹤多個片段資訊:
model = tokens - 5 + indices
model.input([1, 2, 3, 5, 2])

(tokens == "l") | (indices == 1)

我們提供了一些輔助函式讓寫 transforms 變得更簡單,舉例來說,where 提供了一個類似 if 功能的結構。
where((tokens == "h") | (tokens == "l"), tokens, "q")

map 使我們可以定義自己的操作,例如一個字串以 int 轉換。(使用者應謹慎使用可以使用的簡單神經網路計算的操作)
atoi = tokens.map(lambda x: ord(x) - ord('0'))
atoi.input("31234")

函式 (functions) 可以容易的描述這些 transforms 的級聯。舉例來說,下面是應用了 where 和 atoi 和加 2 的操作
def atoi(seq=tokens):
return seq.map(lambda x: ord(x) - ord('0'))
op = (atoi(where(tokens == "-", "0", tokens)) + 2)
op.input("02-13")

注意力篩選器
到開始應用注意力機制事情就變得開始有趣起來了。這將允許序列間的不同元素進行資訊交換。
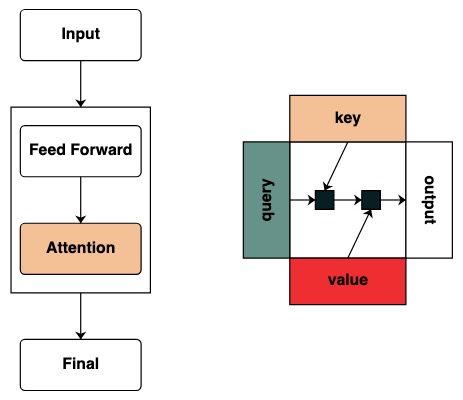
我們開始定義 key 和 query 的概念,Keys 和 Queries 可以直接從上面的 transforms 建立。舉個例子,如果我們想要定義一個 key 我們稱作 key。
key(tokens)

對於 query 也一樣
query(tokens)

標量可以作為 key 或 query 使用,他們會廣播到基礎序列的長度。
query(1)

我們建立了篩選器來應用 key 和 query 之間的操作。這對應於一個二進位制矩陣,指示每個 query 要關注哪個 key。與 Transformers 不同,這個注意力矩陣未加入權重。
eq = (key(tokens) == query(tokens))
eq
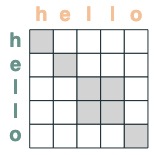
一些例子:
- 選擇器的匹配位置偏移 1:
offset = (key(indices) == query(indices - 1))
offset
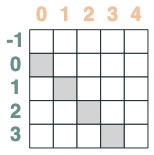
- key 早於 query 的選擇器:
before = key(indices) < query(indices)
before
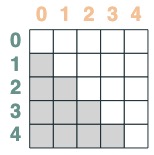
- key 晚於 query 的選擇器:
after = key(indices) > query(indices)
after
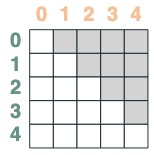
選擇器可以通過布林操作合併。比如,這個選擇器將 before 和 eq 做合併,我們通過在矩陣中包含一對鍵和值來顯示這一點。
before & eq
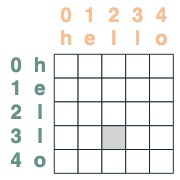
使用注意力機制
給一個注意力選擇器,我們可以提供一個序列值做聚合操作。我們通過累加那些選擇器選過的真值做聚合。
(請注意:在原始論文中,他們使用一個平均聚合操作並且展示了一個巧妙的結構,其中平均聚合能夠代表總和計算。RASPy 預設情況下使用累加來使其簡單化並避免碎片化。實際上,這意味著 raspy 可能低估了所需要的層數。基於平均值的模型可能需要這個層數的兩倍)
注意聚合操作使我們能夠計算直方圖之類的功能。
(key(tokens) == query(tokens)).value(1)
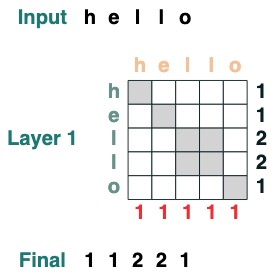
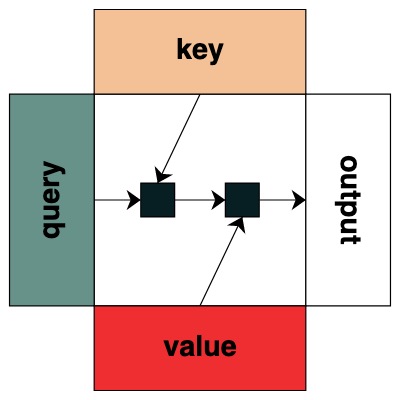
視覺上我們遵循圖表結構,Query 在左邊,Key 在上邊,Value 在下面,輸出在右邊
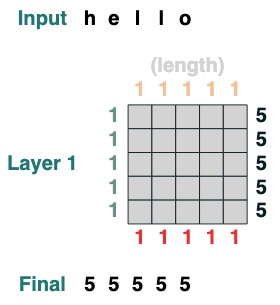
一些注意力機制操作甚至不需要用到輸入 token 。舉例來說,去計算序列長度,我們建立一個 " select all " 的注意力篩選器並且給他賦值。
length = (key(1) == query(1)).value(1)
length = length.name("length")
length
這裡有更多複雜的例子,下面將一步一步展示。(這有點像做採訪一樣)
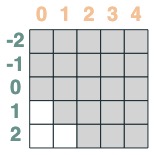
我們想要計算一個序列的相鄰值的和,首先我們向前截斷:
WINDOW=3
s1 = (key(indices) >= query(indices - WINDOW + 1))
s1
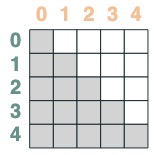
然後我們向後截斷:
s2 = (key(indices) <= query(indices))
s2
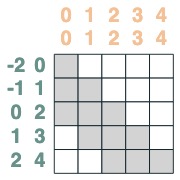
兩者相交:
sel = s1 & s2
sel
最終聚合:
sum2 = sel.value(tokens)
sum2.input([1,3,2,2,2])
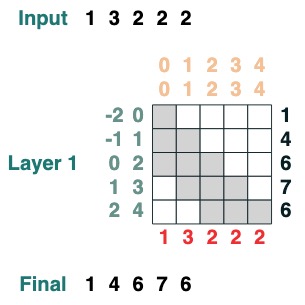
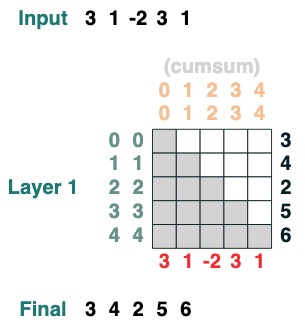
這裡有個可以計算累計求和的例子,我們這裡引入一個給 transform 命名的能力來幫助你除錯。
def cumsum(seq=tokens):
x = (before | (key(indices) == query(indices))).value(seq)
return x.name("cumsum")
cumsum().input([3, 1, -2, 3, 1])
層
這個語言支援編譯更加複雜的 transforms。他同時通過跟蹤每一個運算操作計算層。
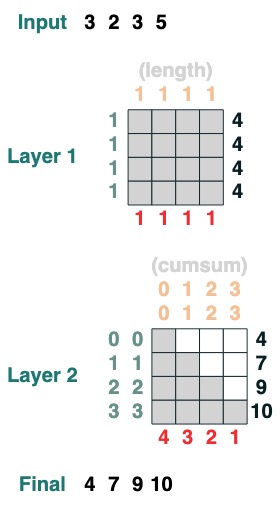
這裡有個 2 層 transform 的例子,第一個對應於計算長度,第二個對應於累積總和。
x = cumsum(length - indices)
x.input([3, 2, 3, 5])
用 transformers 進行程式設計
使用這個函式庫,我們可以編寫完成一個複雜任務,Gail Weiss 給過我一個極其挑戰的問題來打破這個步驟:我們可以載入一個新增任意長度數字的 Transformer 嗎?
例如: 給一個字串 "19492+23919", 我們可以載入正確的輸出嗎?
如果你想自己嘗試,我們提供了一個 版本 你可以自己試試。
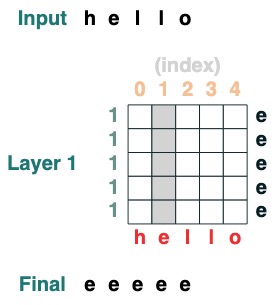
挑戰一:選擇一個給定的索引
載入一個在索引 i 處全元素都有值的序列
def index(i, seq=tokens):
x = (key(indices) == query(i)).value(seq)
return x.name("index")
index(1)
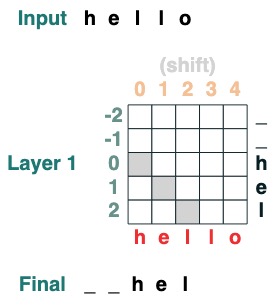
挑戰二:轉換
通過 i 位置將所有 token 移動到右側。
def shift(i=1, default="_", seq=tokens):
x = (key(indices) == query(indices-i)).value(seq, default)
return x.name("shift")
shift(2)
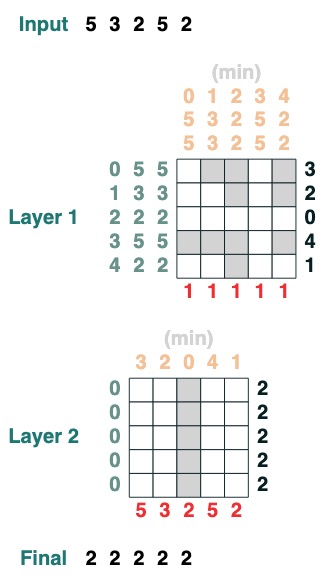
挑戰三:最小化
計算序列的最小值。(這一步開始變得困難,我們版本用了 2 層注意力機制)
def minimum(seq=tokens):
sel1 = before & (key(seq) == query(seq))
sel2 = key(seq) < query(seq)
less = (sel1 | sel2).value(1)
x = (key(less) == query(0)).value(seq)
return x.name("min")
minimum()([5,3,2,5,2])
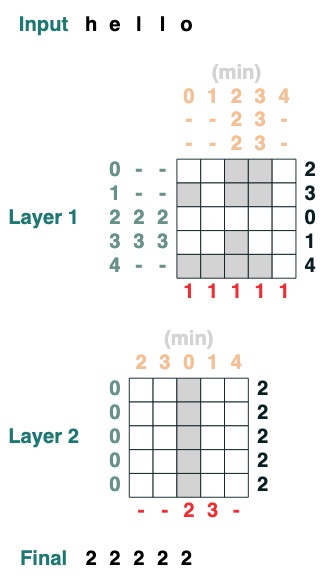
挑戰四:第一索引
計算有 token q 的第一索引 (2 層)
def first(q, seq=tokens):
return minimum(where(seq == q, indices, 99))
first("l")
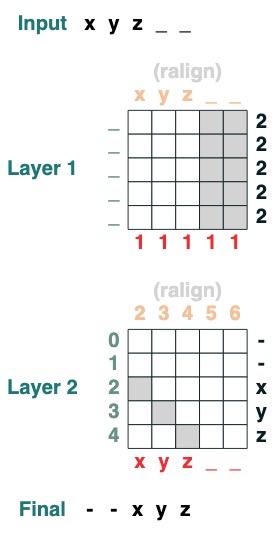
挑戰五:右對齊
右對齊一個填充序列。例:"ralign().inputs('xyz___') ='—xyz'" (2 層)
def ralign(default="-", sop=tokens):
c = (key(sop) == query("_")).value(1)
x = (key(indices + c) == query(indices)).value(sop, default)
return x.name("ralign")
ralign()("xyz__")
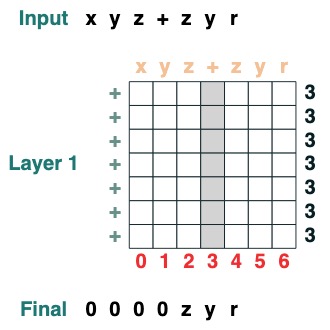
挑戰六:分離
把一個序列在 token "v" 處分離成兩部分然後右對齊 (2 層):
def split(v, i, sop=tokens):
mid = (key(sop) == query(v)).value(indices)
if i == 0:
x = ralign("0", where(indices < mid, sop, "_"))
return x
else:
x = where(indices > mid, sop, "0")
return x
split("+", 1)("xyz+zyr")
split("+", 0)("xyz+zyr")
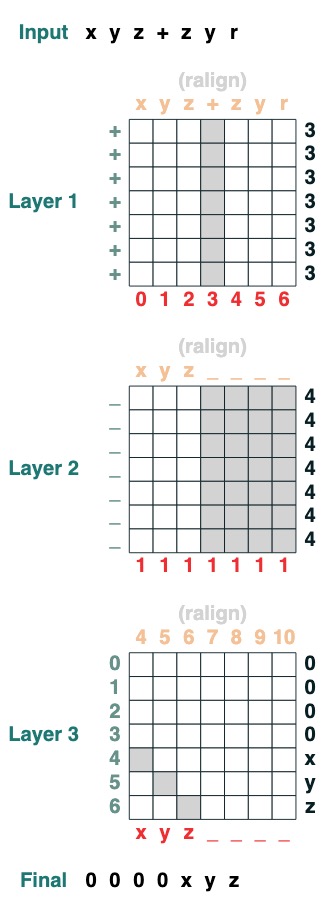
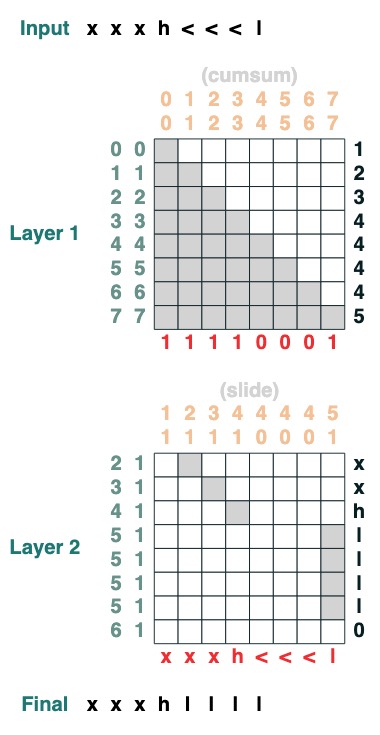
挑戰七:滑動
將特殊 token "<" 替換為最接近的 "<" value (2 層):
def slide(match, seq=tokens):
x = cumsum(match)
y = ((key(x) == query(x + 1)) & (key(match) == query(True))).value(seq)
seq = where(match, seq, y)
return seq.name("slide")
slide(tokens != "<").input("xxxh<<<l")
挑戰八:增加
你要執行兩個數字的新增。這是步驟。
add().input("683+345")
- 分成兩部分。轉製成整形。加入
“683+345” => [0, 0, 0, 9, 12, 8]
- 計算攜帶條款。三種可能性:1 個攜帶,0 不攜帶,< 也許有攜帶。
[0, 0, 0, 9, 12, 8] => “00<100”
- 滑動進位係數
“00<100” => 001100"
- 完成加法
這些都是 1 行程式碼。完整的系統是 6 個注意力機制。(儘管 Gail 說,如果你足夠細心則可以在 5 箇中完成!)。
def add(sop=tokens):
# 0) Parse and add
x = atoi(split("+", 0, sop)) + atoi(split("+", 1, sop))
# 1) Check for carries
carry = shift(-1, "0", where(x > 9, "1", where(x == 9, "<", "0")))
# 2) In parallel, slide carries to their column
carries = atoi(slide(carry != "<", carry))
# 3) Add in carries.
return (x + carries) % 10
add()("683+345")
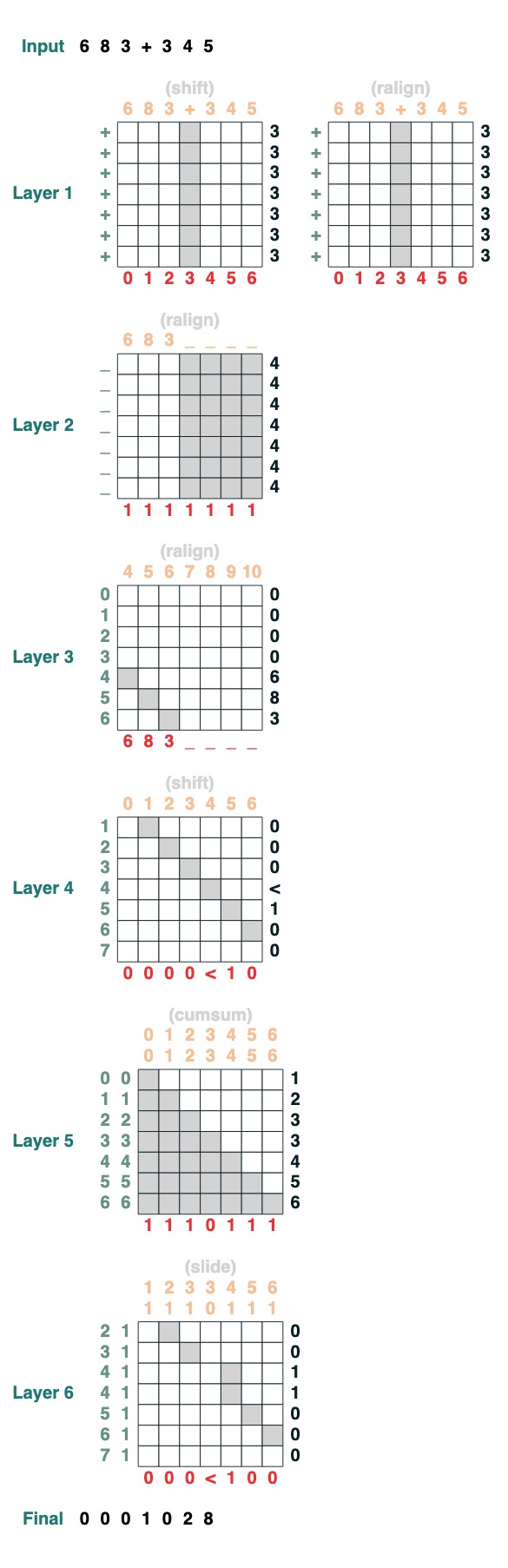
683 + 345
1028
完美搞定!
參考資料 & 文內連結:
- 如果你對這個主題感興趣想了解更多,請檢視論文:Thinking Like Transformers
- 以及瞭解更多 RASP 語言
- 如果你對「形式語言和神經網路」(FLaNN) 感興趣或者有認識感興趣的人,歡迎邀請他們加入我們的 線上社群!
- 本篇博文,包含庫、Notebook 和博文的內容
- 本部落格文章由 Sasha Rush 和 Gail Weiss 共同編寫
<hr>
英文原文:Thinking Like Transformers
譯者:innovation64 (李洋)
- 在一張 24 GB 的消費級顯示卡上用 RLHF 微調 20B LLMs
- 如何評估大語言模型
- 千億引數開源大模型 BLOOM 背後的技術
- Kakao Brain 的開源 ViT、ALIGN 和 COYO 文字-圖片資料集
- AI 影評家: 用 Hugging Face 模型打造一個電影評分機器人
- 我的語言模型應該有多大?
- Hugging Face 每週速遞: Chatbot Hackathon;FLAN-T5 XL 微調;構建更安全的 LLM
- AI 大戰 AI,一個深度強化學習多智慧體競賽系統
- Hugging Face 每週速遞: ChatGPT API 怎麼用?我們幫你搭好頁面了
- 深入瞭解視覺語言模型
- CPU推理|使用英特爾 Sapphire Rapids 加速 PyTorch Transformers
- 大語言模型: 新的摩爾定律?
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 從 PyTorch DDP 到 Accelerate 到 Trainer,輕鬆掌握分散式訓練
- 在低程式碼開發平臺 ILLA Cloud 中使用 Hugging Face 上的模型
- 瞭解 Transformers 是如何“思考”的
- 第 1 天|基於 AI 進行遊戲開發:5 天建立一個農場遊戲!
- 加速 Document AI (文件智慧) 發展
- 一文帶你入門圖機器學習
- 解讀 ChatGPT 背後的技術重點:RLHF、IFT、CoT、紅藍對抗