“零”代码改动,静态编译让太乙Stable Diffusion推理速度翻倍

作者|梁德澎
AI 作图领域的工具一直不尽如人意,直到去年 8 月 Stable Diffusion 开源,成为AI 图像生成领域无可争辩的划时代模型。
为了提升其推理效率,OneFlow 首度将 Stable Diffusion 模型加速至“一秒出图”时代,极大提升了文生图的速度,在AIGC领域引发巨大反响,并得到了 Stability.ai 官方的支持。至今,OneFlow 还在不断刷新 SOTA 纪录。
不过,由于目前大部分团队主要是基于翻译 API + 英文 Stable Diffusion 模型进行开发,所以在使用中文独特的叙事和表达时,英文版模型就很难给出正确匹配的图片内容,这对部分国内用户来说不太方便。
为了解决这一问题,国内的IDEA 研究院认知计算与自然语言研究中心(IDEA CCNL)也开源了第一个中文版本的“太乙 Stable Diffusion”,基于0.2亿筛选过的中文图文对训练。上个月,太乙 Stable Diffusion 在 HuggingFace 上有近 15 万下载量,是下载量最大的中文 Stable Diffusion。
近期,OneFlow 团队为太乙 Stable Diffusion 适配了 OneFlow 后端,大大提升了推理性能,也可以做到一秒出图。不少开发者好奇OneFlow使用了哪些优化“秘笈”,后文将进行简要解读。
欢迎Star、运行 OneFlow 版太乙 Stable Diffusion:
http://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion#without-docker
1
对比 PyTorch,OneFlow 将“太乙 Stable Diffusion”推理速度提升1倍以上
下面的图表分别展示了在 A100 (PCIe 40GB / SXM 80GB),V100 ( SXM2 32GB ), RTX 2080,RTX 3080 Ti,RTX 3090, 和 T4 不同类型的 GPU 硬件上分别使用 PyTorch, 和 OneFlow对 太乙 Stable Diffusion 进行推理的性能表现。


可以看到,对于 A100 显卡,无论是 PCIe 40GB 的配置还是 SXM 80GB 的配置,OneFlow 的性能相比 PyTorch 能提升 1 倍以上,推理速度达到了 50it/s 以上,生成一张图片所需要的时间在 1 秒以内。
其他硬件数据:
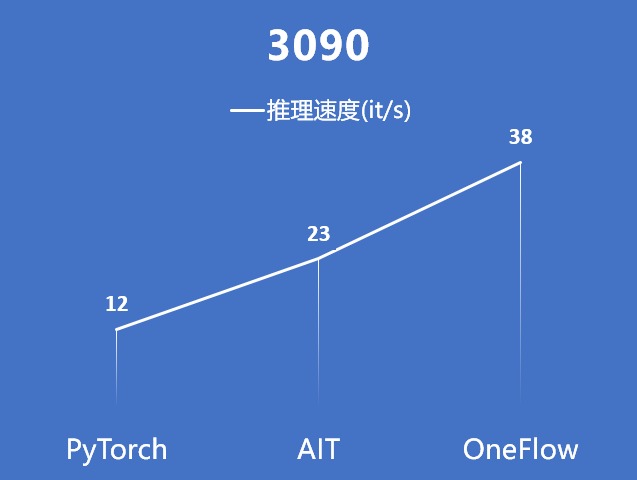
注:3090上的AIT数据由 IDEA 研究院提供




综上,在各种硬件的对比中,对比 PyTorch, OneFlow 能将太乙 Stable Diffusion 的推理性能提升 1 倍多。
2
生成图片展示
滔滔江水, 连绵不绝, 唯美, 插画

长城, 清晨, 朦胧, 唯美, 插画

梦回江南,中国古代小镇,唯美,插画

中国的未来城市, 科幻插画

古代建筑, 白雪纷飞

螺蛳粉

注:上述图片均基于 OneFlow 版太乙 Stable Diffusion 生成
3
无缝兼容 PyTorch 生态
想体验 OneFlow 版的太乙 Stable Diffusion?只需要修改两行代码:

之所以能这么轻松迁移模型,是因为 OneFlow Stable Diffusion 有两个出色的特性:
-
OneFlowStableDiffusionPipeline.from_pretrained 能够直接使用 PyTorch 权重。
-
OneFlow 本身的 API 和 PyTorch 对齐,因此 import oneflow as torch 之后,torch.autocast、torch.float16 等表达式完全不需要修改。
上述特性使得 OneFlow 兼容了 PyTorch 的生态,这不仅在 OneFlow 对 太乙 Stable Diffusion 的迁移中发挥了作用,也大大加速了 OneFlow 用户迁移其它许多模型,比如在和 torchvision 对标的 flowvision 中,许多模型只需通过在 torchvision 模型文件中加入 import oneflow as torch 即可得到。
此外,OneFlow 还提供全局 “mock torch” 功能,在命令行运行 eval $(oneflow-mock-torch) 就可以让接下来运行的所有 Python 脚本里的 import torch 都自动指向 oneflow。
4
动静一体的编程体验
深度学习算法原型开发阶段需要快速修改和调试,动态图执行(Eager mode, define by run)最优。但在部署阶段,模型已经固定下来,计算效率变得更重要,静态图执行(Lazy mode,define and run)可以借助编译器做静态优化来获得更好的性能。因此,推理阶段主要使用静态图模式。
最近,PyTorch 升级到2.0引入了compile()这个API,可以把一个模型或一个Module从动态图执行变成静态图执行。OneFlow里也有一个类似的机制,不过接口名是nn.Graph(),它可以把传入Module转成静态图执行模式。
不仅如此,OneFlow的nn.Graph模式基于MLIR实现了一系列计算图的图层优化 ,譬如内存布局、算子融合等。
这不仅使得计算图表示的深度学习模型可以在各种硬件上达到最高性能,更重要的是,使得深度学习框架导入的计算图更方便地在不同硬件之间实现迁移,有助于克服国产硬件软件生态薄弱的问题。未来,我们将发布更多内容来揭示OneFlow深度学习编译器的设计和实现。
欢迎Star、运行 OneFlow 版太乙 Stable Diffusion:
http://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion#without-docker
OneFlow 地址:http://github.com/Oneflow-Inc/oneflow/
其他人都在看
欢迎Star、试用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 - OneFlow(OneFlowTechnology)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
- NCCL源码解析①:初始化及ncclUniqueId的产生
- GPT-4问世;LLM训练指南;纯浏览器跑Stable Diffusion
- 适配PyTorch FX,OneFlow让量化感知训练更简单
- 超越ChatGPT:大模型的智能极限
- ChatGPT作者John Schulman:我们成功的秘密武器
- YOLOv5全面解析教程⑤:计算mAP用到的Numpy函数详解
- GPT-3/ChatGPT复现的经验教训
- ChatGPT背后:从0到1,OpenAI的创立之路
- 一块GPU搞定ChatGPT;ML系统入坑指南;理解GPU底层架构
- YOLOv5全面解析教程④:目标检测模型精确度评估
- ChatGPT数据集之谜
- OneFlow源码解析:Eager模式下的SBP Signature推导
- YOLOv5全面解析教程③:更快更好的边界框回归损失
- ChatGPT背后的经济账
- Sam Altman的成功学|升维指南
- 开源机器学习软件对AI的发展意味着什么?
- “一键”模型迁移,性能翻倍,多语言AltDiffusion推理速度超快
- “零”代码改动,静态编译让太乙Stable Diffusion推理速度翻倍
- GLM国产大模型训练加速:性能最高提升3倍,显存节省1/3,低成本上手
- 35张图,直观理解Stable Diffusion