如何有效的解決程式碼的圈複雜度
作者:京東零售 楊學剛
背景介紹
不管小型公司還是大型網際網路公司,很多專案債臺高築,新功能開發困難。其中一個很大的原因就是程式碼複雜,可讀性差。Sonar開發團隊曾上綱上線的戲稱開發人員的7宗罪,其中很關鍵的一條就是“複雜度”。那複雜度有沒有一個明確的衡量標準,我們又如何去解決程式碼的圈複雜度呢?今天我在這裡和大家聊一下。
圈複雜度的計算方法
我們先來看一下圈複雜度與程式碼質量以及測試和維護成本之間的一個關係。
我們可以看到當圈複雜度,在1-10之間的時候,程式碼是清晰,結構化的。可測試性比較高,維護成本也比較低。隨著圈複雜度的升高,程式碼的狀況開始惡化,當大於30的時候,程式碼已經逐步變為不可讀,維護成本非常高。
點邊計演算法
那圈複雜度是如何計算的呢,常用的第一種方法叫做點邊計演算法,它圈複雜度的計算方式 V(G) = E − N + 2,我們用下邊圖來解釋一下這個公式:
其中公式之中的E指的是控制流圖中邊的數量,N指的是控制流圖中的節點數量。這兩個圖形指的就是控制流圖。那我們可以計算一下,第一個控制流圖的圈複雜度是:4-4+2=2.
節點判定法
除此之外圈複雜度還有一種更為直觀的計算方法,因為圈複雜度實際上體現了“判定條件”的數量,所以圈複雜度實際上就是等於判定節點的數量再加上1。它的計算公式為:V (G) = P + 1 其中判定節點(P)指的是我們常用的分支語句。例如if語句、while語句、case語句等。
那如何來降低圈複雜度呢?
圈複雜度的常用解決方法
提煉函式
接下來我們重點介紹一些降低圈複雜的方法,我通過工作中常見的程式碼,來表述一下,如何去降低複雜度,如果你有更好的方法,也歡迎留言跟我交流。在我們的工作中,做業務系統的時候,通過非同步訊息進行資料傳遞,是比較常用的一種方式,在我們監聽到對端系統的訊息的時候,一般會做這幾件事情。判斷訊息是否為空-->轉換訊息為資料傳輸物件DTO-->進一步的判斷物件的資料是否合法-->進行業務邏輯的處理。這幾個典型的步驟,很多童鞋可能用左邊圖的方式進行處理。這個時候,如果每一個步驟的方法比較複雜的時候,這個總的方法會非常複雜,這個時候,我們可以通過提煉方法的方式,對高內聚的操作,提煉到一個獨立的方法中,來分治複雜性。
使用衛語句
我們知道圈複雜度的一個因素就是分支語句多,我們在寫業務程式碼的時候,常見到這樣的一種程式碼,if-then-else的層層巢狀。衛語句的原則是,如果某個條件極其罕見,就應該單獨檢查該條件,並在該條件為真時,立刻返回。下面是一個生產中的場景,如果記賬請求落庫成功後就進行餘額的操作,如果不成功就返回失敗結果。因為落庫失敗是不常見的,所以我們採用衛語句的方式,來減少分支語句。讓程式碼更清晰。
合併條件
經常遇到一種情況,我們對錯誤的處理,需要返回給呼叫方,內部的錯誤碼,為了方便快讀的定位錯誤會非常詳細,但是對外可能會泛化這種錯誤碼,這個時候我們可以通過合併條件的方式,簡化條件分支,來降低圈複雜度。下面是一個生產中的場景,如果記賬失敗,則對錯誤結果進行包裝處理,並返回給呼叫方。這個時候我們可以將錯誤碼合併,這裡它是合併到map中,然後針對這組錯誤碼統一進行了處理。
通過多型方式替代條件式
在我們開發中,如果是一個平臺化的系統,很多時候,有這樣的需求。例如:不同的租戶、不同的業務甚至不同的訂單型別都會有不同的處理流程。 這個時候最簡單的方式,就是通過條件分支來進行不同的處理。但是當業務繁多的時候,處理分支會顯得混亂,從而導致圈複雜度的升高,這個時候我們通過利用多型的方式,可以有效的降低複雜度。我們看一下下邊這段程式碼,不同的訂單型別,使用不同的處理流程,這裡他使用了在列舉中實現多型的方式。我們發現,其實他是實現了工廠模式。
替換演算法
複雜演算法會導致bug可能性的增加及可理解性/可維護性的降低,如果函式對效能要求不高,提倡使用簡單明瞭的演算法。這裡我引用了重構中的一個例子,我們可以一起看一下。這裡傳入一個人名的陣列,如果陣列中包含指定的名稱,就立即返回名稱。
分解條件式
在面對大塊頭的程式碼時,你可以通過提煉方法的方式,將它分解為多個方法。根據每個小塊程式碼的用途,命名新的方法名。對於條件邏輯,將每個分支條件分解成新方法可以突出條件邏輯,並更清楚的表達每個分支的作用。比如下面的例子中,夏季的時候商品的折扣和非夏天的商品折扣,是不同的計算方法。 這個時候,我們可以把兩種演算法,提煉到兩個不同的方法中.
移除控制標記
有時候我們會通過控制標記來對迴圈進行處理,我們看一下這樣的一段經常使用的程式碼,同一個陣列列表中查詢罪惡的人,匹配到任意一個罪惡的人後返回。這裡found是控制標記,我們可通過下邊的方式去掉控制標記,來減少一層迴圈,達到削減複雜度的效果。
圈複雜度的思辨
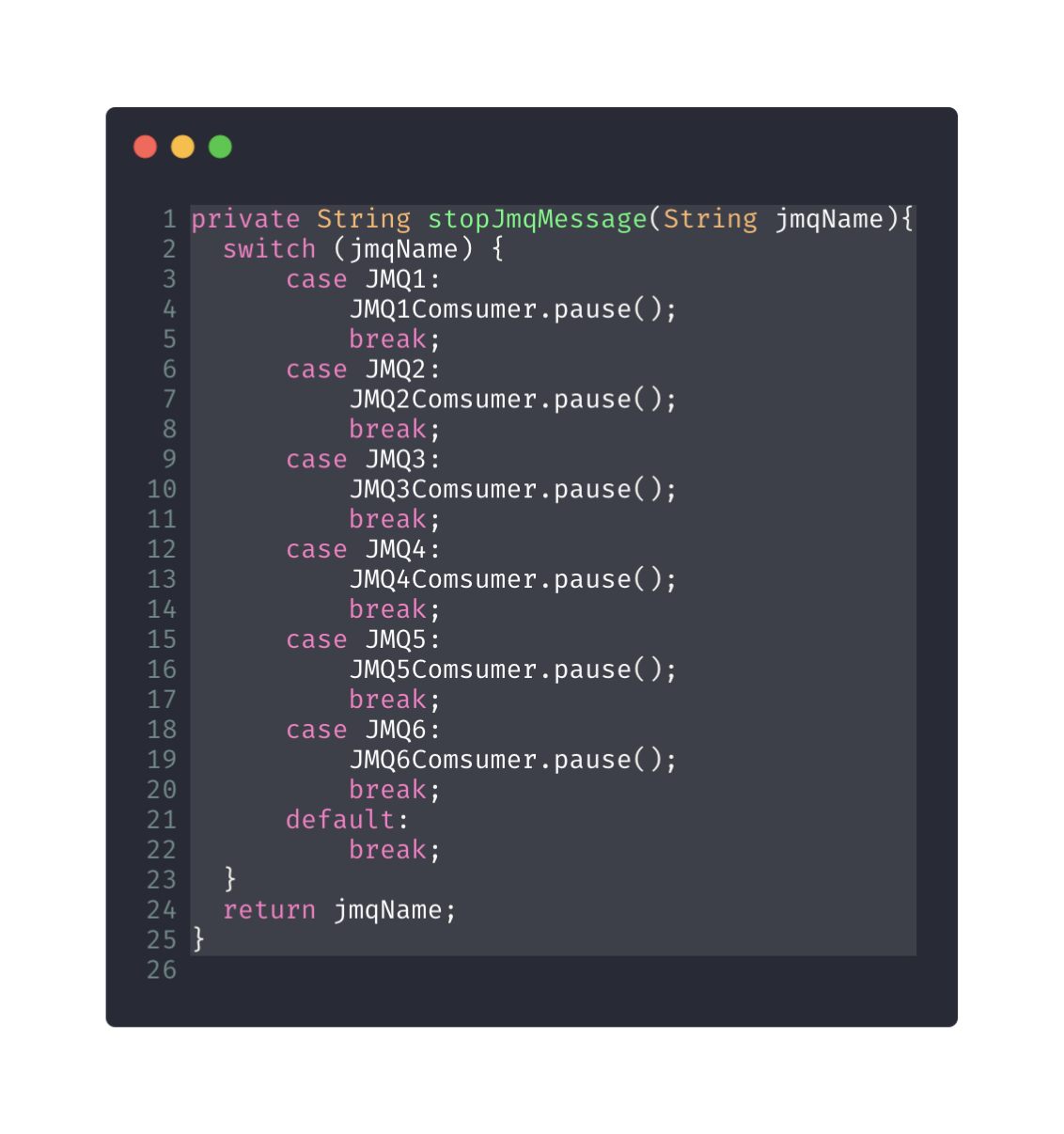
那是不是當我們檢測到圈複雜度高的時候他就一定複雜呢,下面的程式碼是一個生產上的例子,他通過傳入的MQ的名字,對MQ進行手動的暫停。這個地方實際上是可以通過mq的名稱,從spring的容器中,獲取bean的。這裡的例子主要是讓大家看到,雖然,這個分支比較多,但是這種扁平化的結構可讀性還是可以的。不過如果它做的不僅僅是一個暫停的操作,而是一個很複雜的操作,這個時候,可能就需要通過提煉方法的方式進行重構。如果提煉方法重構後,這個類還是過長,那就需要我們通過使用多型的特性,利用工廠模式等方式進行進一步的重構。如果一開始我們就通過應用一些複雜的設計模式進行重構,就會存在過度設計的弊端,使程式碼更不易於理解。
總結
首先介紹了什麼是圈複雜度,然後介紹瞭解決圈複雜度的幾種方法。
通過圈複雜度計算的兩種方式我們可以看到,圈複雜度的核心是分支語句。那解決問題的核心就集中在如何去減少分支語句。
不過最後我們也看到了,實際上,只是刻板的使用圈複雜度的演算法,去度量一個段程式碼的清晰度,有時候也是不可取的,所以我們在重構系統的時候,可以通過圈複雜度的工具,進行復雜度的統計,然後對複雜度高的程式碼,具體場景,具體分析。而不能一味的教條。
最後我們通過思維導圖來梳理一下:
- 應用健康度隱患刨析解決系列之資料庫時區設定
- 對於Vue3和Ts的心得和思考
- 一文詳解擴散模型:DDPM
- zookeeper的Leader選舉原始碼解析
- 一文帶你搞懂如何優化慢SQL
- 京東金融Android瘦身探索與實踐
- 微前端框架single-spa子應用載入解析
- cookie時效無限延長方案
- 聊聊前端效能指標那些事兒
- Spring竟然可以建立“重複”名稱的bean?—一次專案中存在多個bean名稱重複問題的排查
- 京東金融Android瘦身探索與實踐
- Spring原始碼核心剖析
- 深入淺出RPC服務 | 不同層的網路協議
- 安全測試之探索windows遊戲掃雷
- 關於資料庫分庫分表的一點想法
- 對於Vue3和Ts的心得和思考
- Bitmap、RoaringBitmap原理分析
- 京東小程式CI工具實踐
- 測試用例設計指南
- 當你對 redis 說你中意的女孩是 Mia