使用Colossal-AI復現Pathways Language Model

Google Brain的Jeff Dean在2021年提出了Pathways的設想,這是一個為未來深度學習模型而設計的系統。在前不久,Google終於放出了關於Pathways的第一篇論文《Pathways: Asynchronous Distributed Dataflow for ML》 以及使用TPU Pod在Pathways上訓練的第一個模型PaLM (Pathways Language Model)。相比傳統Transformers結構,PaLM做了一些大膽的創新,相信很多小夥伴已經迫不及待想嚐鮮一下PaML的效果,但是又苦於無法實現複雜的並行策略。團隊使用PyTorch實現了PaLM的模型結構,並應用ZeRO,模型並行,數據並行等方法,將其擴展到多GPU。
PaLM代碼現已開源在:
http://github.com/hpcaitech/PaLM-colossalai
關於Colossal-AI
Colossal-AI是一個專注於大規模模型訓練的深度學習系統,Colossal-AI基於PyTorch開發,旨在支持完整的高性能分佈式訓練生態。Colossal-AI已在GitHub上開源,且多次登頂GitHub Trending榜單,感興趣的同學可以訪問我們的GitHub主頁:
http://github.com/hpcaitech/ColossalAI
在Colossal-AI中,我們支持了不同的分佈式加速方式,包括張量並行、流水線並行、零宂餘數據並行、異構計算等。在例子庫裏,我們已經提供了BERT, GPT以及ViT等支持混合並行的訓練實例。這次,我們將Colossal-AI應用到PaLM的模型上,來支持不同並行策略的分佈式訓練。
關於Pathways
Pathways是Google開發的新一代機器學習系統,它是為了滿足Google未來深度學習訓練需求而重新設計的。想了解更多的同學可以閲讀一流科技袁老師寫的博客。由於Pathways的設計是面向類似TPU Pod的硬件和網絡結構相對定製化的,並且很多核心組件也尚未開源,這給大家在GPU上體驗PaLM模型效果造成了很大的障礙。而PaLM模型參數量巨大,採用傳統的數據並行技術也已經無法其擴展到多個GPU。那能否用我們常見的GPU集羣來嚐鮮一下PaLM模型呢?潞晨科技的工程師們利用Colossal-AI給出瞭解決方案。
PaLM模型解讀
比起常規的Transformer層,PaLM有以下幾個重要的改動。
1.SwiGLU激活函數
SwiGLU是谷歌的一名研究員設計的激活函數,比起Transformer模型常用的ReLU、GeLU或者Swish,SwiGLU能實現更好的模型性能。
2.並行Transformer層
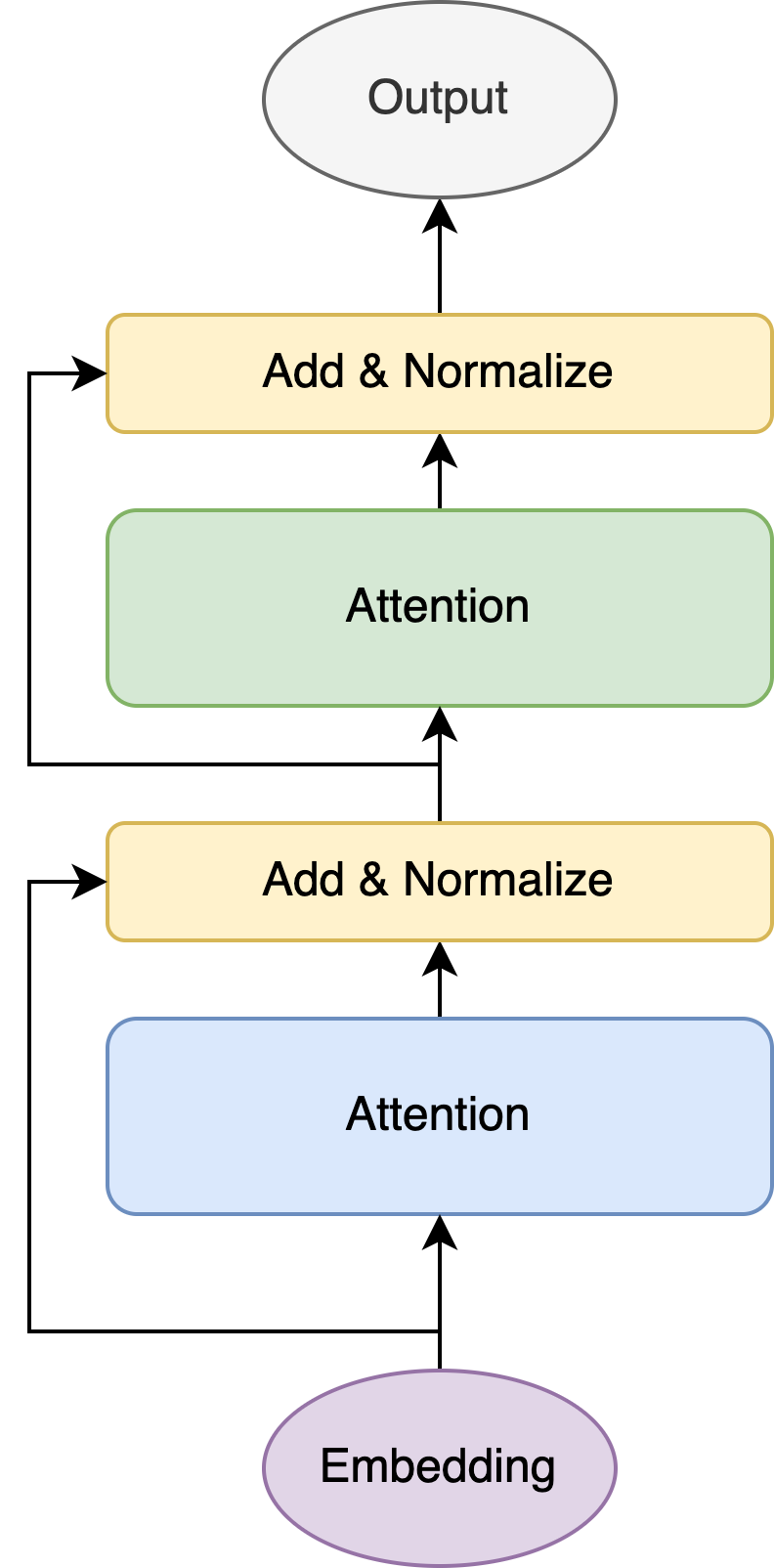
熟悉Transformer模型的同學都知道Transformer主要有attention和MLP兩個模塊。如上圖,MLP模塊通常接在attention模塊之後。但是在PaLM中,為了追求計算效率,將Attention和MLP層合併到了一起。
正常的Transformer層可以表示為:
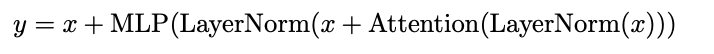
PaLM的Transformer層則表示為:
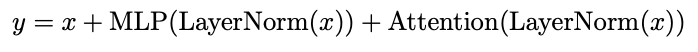
論文中提到MLP層和Attention層的第一個linear層可以融合,這可以帶來大約15%的提升,但是我們發現MLP和Attention的第二個linear層也可以融合,能進一步提升計算效率。融合之後的模型架構可以用下面的架構圖表示。
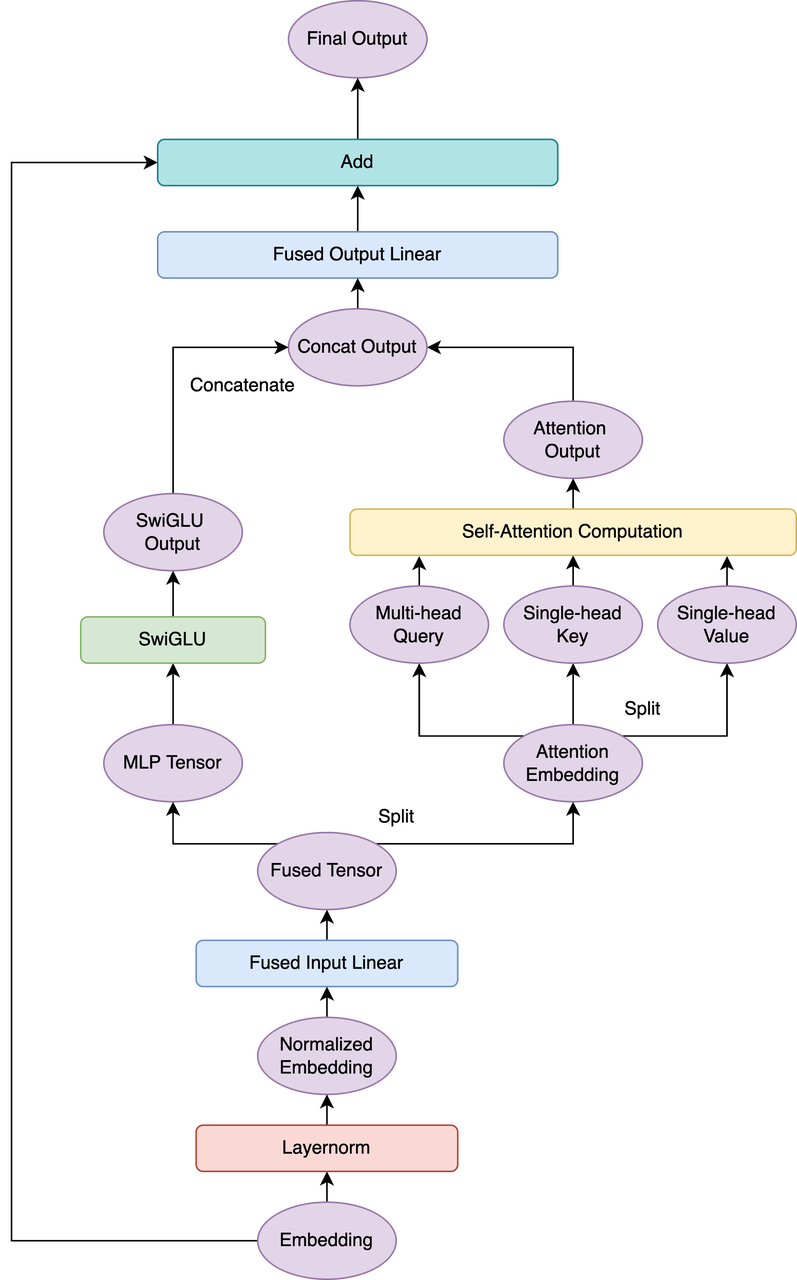
3.Multi-Query 注意力機制
與常規的多頭注意力(multi-head attention)不同,PaLM中key和value都只有一頭,只有query保持了多頭,這樣能夠在不損失模型性能的情況下減少計算量,提升訓練和推理的速度。在我們的實現中,提供了multi-query和multi-head兩種機制。
4.linear和layernorm層均不使用bias,Google研究員聲稱這有利於模型的訓練穩定。
我們根據論文描述,首先編寫了單卡版本的PaLM。這裏我們參考瞭如下repo的工作:
http://github.com/lucidrains/PaLM-pytorch
Colossal-AI並行改造
在實現單卡串行版本的訓練程序後,利用Colossal-AI,我們可以很容易地將訓練過程擴展到多GPU並行。
張量並行改造
Colossal-AI支持了與PyTorch算子接口一致的並行算子,我們使用colossalai.nn.Linear去替換原生的torch.nn.Linear,這樣能夠允許運行時使用不同的張量並行(1D, 2D, 2.5D, 3D),想詳細瞭解不同類型的張量並行的同學可以移步到Colossal-AI文檔。
在對PaLM進行並行版本改造時,會遇到由其attention結構引起的一個特殊問題。張量並行會對query, key和value的最後一維進行切割(第一個維度根據並行模式可能會切,但是不影響計算,所以在下文會忽略),由於key和value為single-head,我們需要進行額外的通信來確保正確性。我們用B來表示batch size, S表示sequence length,H表示hidden size,N表示attention head的個數,A表示單個attention head的大小,P表示被切割的份數, 其中H = NA。
在非並行的情況下,我們的multi-head query張量大小為(B, S, H),single-head key和value的大小為(B, S, A),通過將query轉換為(B, S, N, A),可以直接與key和value進行注意力計算。但是在並行情況下,query為(B, S, H / P),key和value為(B, S, A/P)。我們可以將query轉化為(B, S, N/P, A),這樣我們就可以在不同GPU上切割query的head維度。但是這樣仍然不能進行計算,因為key和value上的值並不足以組成一個完整的attention head,所以需要引入額外的all-gather操作來組成一個完成head,即(B, S, A/P) -> (B, S, A)。如此一來,便能進行正常的注意力計算。
ZeRO並行
Colossal-AI可通過在配置文件里加入ZeRO相關配置,實現微軟提出的ZeRO方式數據並行,並與上述不同張量並行方式混合使用。
異構訓練
為了支持在單節點上進行大規模AI模型訓練,我們實現動態異構內存管理機制,通過捕捉一個張量的生命週期,將張量在合適的時間放置在CPU或GPU上。相比DeepSpeed的ZeRO-offload,我們的方式可以減少CPU-GPU內存移動,並且更高效利用異構內存。
訓練流程
在明確了優化手段後,我們可以直接定義一下配置文件(config.py),在配置文件中添加張量並行以及ZeRO的配置。

有了這個配置文件,我們就可以使用colossalai.initialize去初始化一個訓練引擎,這個引擎提供了與PyTorch類似的常用API,這樣就能使用Colossal-AI進行大規模訓練了。

性能測試
我們在一台搭載8張A100 40GB GPU的單機多卡服務器上進行測試。該服務器使用NVLink將相鄰成對的兩張GPU高速互聯,4對GPU之間採用PCI-E進行互聯。
我們構造了一個80億參數的PaLM結構網絡,並使用混合並行策略(1D, 2D, 2.5D Tensor Parallel,ZeRO)去訓練它。ColossalAI只需要通過零代碼方式改動配置文件,就可以低成本的切換不同訓練策略。下圖中,b表示每個數據並行進程組的batch size,XXtpY表示tp並行策略,XX表示1D,2D,2.5D並行方案,Y表示TP的並行degree。zero表示ZeRO方式數據並行degree。數據並行degree X 模型並行degree=總的GPU數。
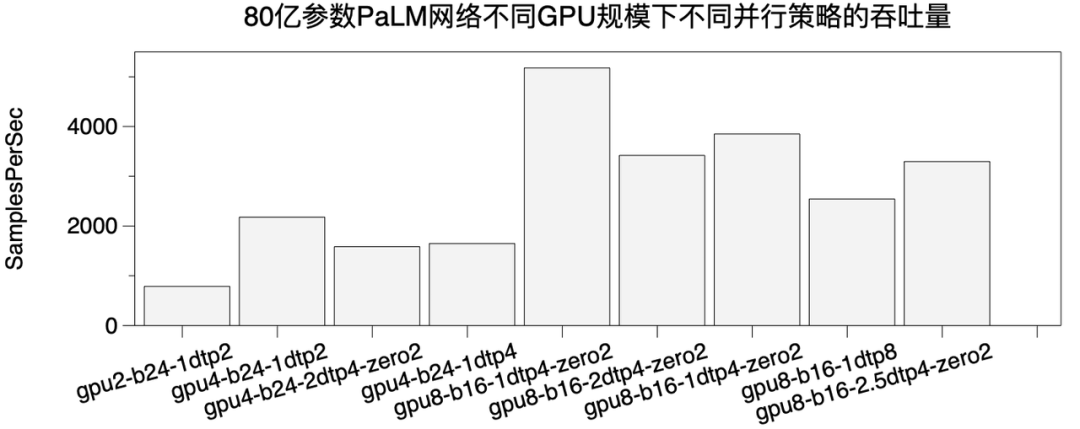
通過實驗我們發現,異構訓練是非常必要的,以上方案全部需要使用異構訓練實現,如果不使用則無法成功運行80億參數模型。
在2,4,8GPU情況下,我們發現1D TP degree為2效果最好。這是由我們的網絡硬件拓撲決定的,因為相鄰2個GPU之間通信帶寬相對比較高,TP=2可以將大部分通信放在相鄰GPU內。如果,在不同的網絡硬件下,2D和2.5D會顯示出更大的威力。ColossalAI通過簡單的並行策略配置來快速適配不同的網絡硬件。
總結
Colossal-AI團隊根據Pathways的論文復現了PaLM的模型架構,由於計算資源的限制,很遺憾我們無法嘗試復現論文中的千億級參數模型結構。同時,目前Google原始版的PaLM並沒有開源,所以我們的實現也可能和Google的官方實現有偏差。如果有任何疑問,歡迎大家在GitHub提出Issue或者PR,我們將積極嘗試解答大家的問題。:)
項目團隊
潞晨技術團隊的核心成員均來自美國加州大學伯克利分校,斯坦福大學,清華大學,北京大學,新加坡國立大學,新加坡南洋理工大學等國內外知名高校;擁有Google Brain、IBM、Intel、 Microsoft、NVIDIA等知名廠商工作經歷。公司成立即獲得創新工場、真格基金等多家頂尖VC機構種子輪投資。
目前,潞晨科技還在廣納英才,招聘全職/實習AI分佈式系統、架構、編譯器、網絡、CUDA、SaaS、k8s等核心系統研發人員,開源社區運營、銷售人員。
潞晨科技提供有競爭力的薪資回報,特別優秀的,還可以申請遠程工作。也歡迎各位向潞晨科技引薦優秀人才,如果您推薦優秀人才成功簽約潞晨科技,我們將為您提供數千元至數萬元的推薦費。
工作地點:中國北京,新加坡,美國。(可相互轉崗)
簡歷投遞郵箱:[email protected]
傳送門
PaLM項目地址:
http://github.com/hpcaitech/PaLM-colossalai
Colossal-AI項目地址:
http://github.com/hpcaitech/ColossalAI
Colossal-AI文檔地址:
http://www.colossalai.org/
參考鏈接:
http://arxiv.org/abs/2204.02311
http://arxiv.org/abs/2203.12533
http://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
- 開源方案復現ChatGPT流程!1.62GB顯存即可體驗,單機訓練提速7.73倍
- 硬件預算最高直降46倍!低成本上手AIGC和千億大模型,一行代碼自動並行,Colossal-AI再升級
- 潞晨科技完成600萬美元種子及天使輪融資,藍馳領投天使輪
- 無縫支持Hugging Face社區,Colossal-AI低成本輕鬆加速大模型
- 推理加速性能超越英偉達FasterTransformer 50%,開源方案打通大模型落地關鍵路徑
- 在個人電腦用單塊GPU帶動180億參數GPT!熱門開源項目再添新特性
- 使用Colossal-AI分佈式訓練BERT模型
- 使用Colossal-AI復現Pathways Language Model
- 霸榜GitHub熱門第一多日後,Colossal-AI正式版發佈
- 助力藥物研發,低成本加速AlphaFold訓練從11天到67小時,11倍推理加速——開源解決方案FastFold