
作者 | 陳永強
來源 | 微軟研究院AI頭條(ID:MSRAsia)
【導讀】BERT 自從在 arXiv 上發表以來獲得了很大的成功和關注,打開了 NLP 中 2-Stage 的潘多拉魔盒。隨後湧現了一大批類似於“BERT”的預訓練(pre-trained)模型,有引入 BERT 中雙向上下文資訊的廣義自迴歸模型 XLNet,也有改進 BERT 訓練方式和目標的 RoBERTa 和 SpanBERT,還有結合多工以及知識蒸餾(Knowledge Distillation)強化 BERT 的 MT-DNN 等。除此之外,還有人試圖探究 BERT 的原理以及其在某些任務中表現出眾的真正原因。以上種種,被戲稱為 BERTology。本文中,微軟亞洲研究院知識計算組實習生陳永強嘗試彙總上述內容,作拋磚引玉。
1. XLNet 及其與 BERT 的對比
2. RoBERTa
3. SpanBERT
4. MT-DNN 與知識蒸餾
對 BERT 在部分 NLP 任務中表現的深入分析: 1. BERT 在 Argument Reasoning Comprehension 任務中的表現
2. BERT 在 Natural Language Inference 任務中的表現
我們的討論從 XLNet 團隊的一篇博文開始,他們想通過一個公平的比較證明最新預訓練模型 XLNet 的優越性。但什麼是 XLNet 呢?
我們知道,BERT 是典型的自編碼模型(Autoencoder),旨在從引入噪聲的資料重建原資料。而 BERT 的預訓練過程採用了降噪自編碼(Variational Autoencoder)思想,即 MLM(Mask Language Model)機制,區別於自迴歸模型(Autoregressive Model),最大的貢獻在於使得模型獲得了雙向的上下文資訊,但是會存在一些問題:
1. Pretrain-finetune Discrepancy:預訓練時的[MASK]在微調(fine-tuning)時並不會出現,使得兩個過程不一致,這不利於 Learning。2. Independence Assumption:每個 token 的預測是相互獨立的。而類似於 New York 這樣的 Entity,New 和 York 是存在關聯的,這個假設則忽略了這樣的情況。自迴歸模型不存在第二個問題,但傳統的自迴歸模型是單向的。XLNet 團隊想做的,就是讓自迴歸模型也獲得雙向上下文資訊,並避免第一個問題的出現。- Permutation Language Model
- Two-Stream Self-Attention
Permutation Language Model在預測某個 token 時,XLNet 使用輸入的 permutation 獲取雙向的上下文資訊,同時維持自迴歸模型原有的單向形式。這樣的好處是可以不用改變輸入順序,只需在內部處理。它的實現採用了一種比較巧妙的方式:使用 token 在 permutation 的位置計算上下文資訊。如對於,當前有一個 2 -> 4 ->3 ->1 的排列,那麼我們就取出 token_2 和 token_4 作為AR 的輸入預測 token_3。不難理解,當所有 permutation 取完時,我們就能獲得所有的上下文資訊。但是在原來的公式中,我們只使用了 h_θ (x_(Z因此,新的公式做出了改變,引入了要預測的 token 的位置資訊。
此外,為了降低模型的優化難度,XLNet 使用了 Partial Prediction,即只預測當前 permutation 位置 c 之後的 token,最終優化目標如下所示。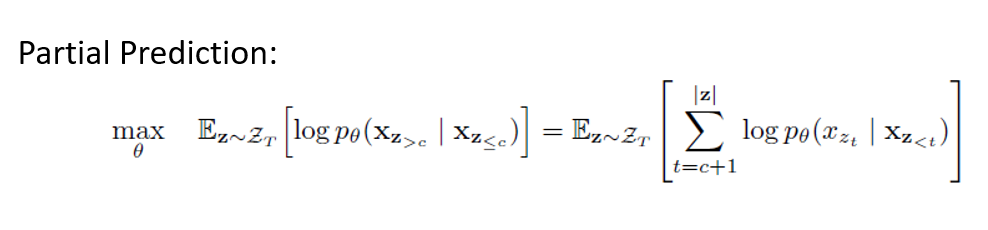
Two-Stream Self-Attention圖3:Two-Stream Self-Attention 機制該機制所要解決的問題是,當我們獲得了 g_θ (x_{Z圖4:Recurrence Mechanism 機制該機制來自 Transformer-XL,即在處理下一個 segment 時結合上個 segment 的 hidden representation,使得模型能夠獲得更長距離的上下文資訊。而在 XLNet 中,雖然在前端採用相對位置編碼,但在表示 h_θ (x_{Z為了說明 XLNet 與 BERT 的區別,作者舉了一個處理“New York is a city”的例子。這個可以直接通過兩個模型的公式得到。假設我們要處理 New York 這個單詞,BERT 將直接 mask 這兩個 tokens,使用“is a city”作為上下文進行預測,這樣的處理忽略了 New 和 York 之間的關聯;而 XLNet 則通過 permutation 的形式,可以使得模型獲得更多如 York | New, is a city 這樣的資訊。為了更好地說明 XLNet 的優越性,XLNet 團隊發表了開頭提到的博文“A Fair Comparison Study of XLNet and BERT”。在這篇博文中,XLNet 團隊控制 XLNet 的訓練資料、超引數(Hyperparameter)以及網格搜尋空間(Grid Search Space)等與 BERT 一致,同時還給出了三個版本的 BERT 進行比較。BERT 一方則使用以下三個模型中表現最好的模型。從中可以看出,在相同設定情況下,XLNet 完勝 BERT。但有趣的是:- XLNet 在使用 Wikibooks 資料集時,在MRPC(Microsoft Research Paraphrase Corpus: 句子對來源於對同一條新聞的評論,判斷這一對句子在語義上是否相同)和 QQP(Quora Question Pairs: 這是一個二分類資料集。目的是判斷兩個來自於 Quora 的問題句子在語義上是否是等價的)任務上獲得了不弱於原版 XLNet 的表現;
- BERT-WWM 模型普遍表現都優於原 BERT;
- 去掉 NSP(Next Sentence Prediction)的 BERT 在某些任務中表現會更好;
除了 XLNet,還有其他模型提出基於 BERT 的改進,讓 BERT 發揮更大的潛能。2. RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa 是最近 Facebook AI 聯合 UW 釋出的 BERT 預訓練模型,其改進主要是如圖所示幾點,除了調參外,還引入了 Dynamically Change Mask Pattern 並移除 Next Sentence Prediction,使得模型在 GLUE Benchmark 排名第一。作者的觀點是:BERT is significantly undertrained。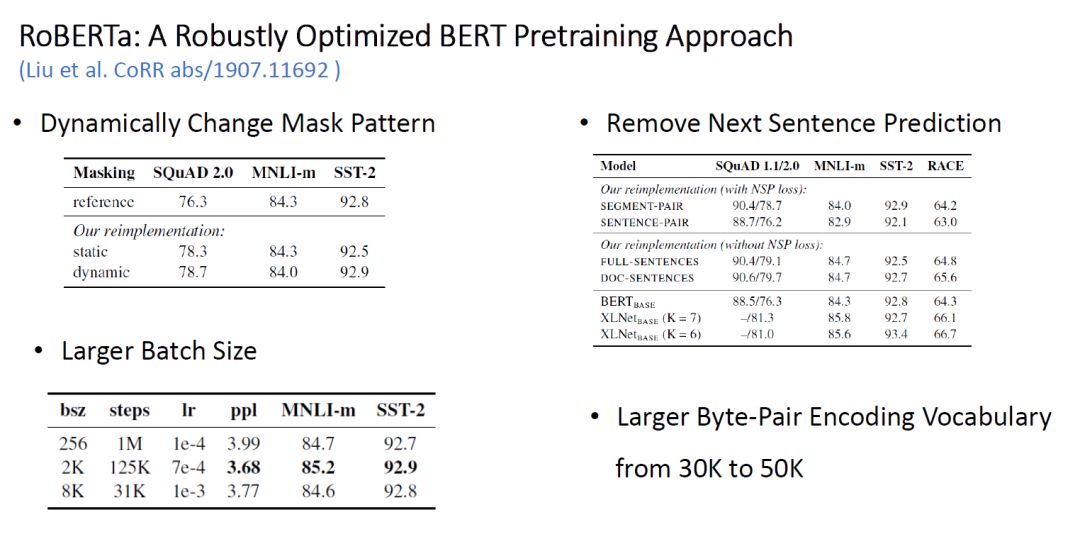 表3:RoBERTa 各個機制的效果比較實驗不同於原有的 BERT 的 MLM 機制,作者在總共40個 epoch 中使用10種不同的 Mask Pattern,即每種 Mask Pattern 訓練4代,作為 static 策略;作者還引入了 dynamic masking 策略,即每輸入一個 sequence 就為其生成一個 mask pattern。最終發現,新策略都比原 BERT 好,而 dynamic 總體上比 static 策略要好一些,並且可以用於訓練更大的資料集以及更長的訓練步數,因此最終選用 dynamic masking pattern。作者還通過替換 NSP 任務進行預訓練。雖然 BERT 中已經做了嘗試去掉 NSP 後的對比,結果在很多工中表現會下降,但是包括前文 XLNet 團隊所做的實驗都在質疑這一結論。
表3:RoBERTa 各個機制的效果比較實驗不同於原有的 BERT 的 MLM 機制,作者在總共40個 epoch 中使用10種不同的 Mask Pattern,即每種 Mask Pattern 訓練4代,作為 static 策略;作者還引入了 dynamic masking 策略,即每輸入一個 sequence 就為其生成一個 mask pattern。最終發現,新策略都比原 BERT 好,而 dynamic 總體上比 static 策略要好一些,並且可以用於訓練更大的資料集以及更長的訓練步數,因此最終選用 dynamic masking pattern。作者還通過替換 NSP 任務進行預訓練。雖然 BERT 中已經做了嘗試去掉 NSP 後的對比,結果在很多工中表現會下降,但是包括前文 XLNet 團隊所做的實驗都在質疑這一結論。- Sentence-Pair+NSP Loss:與原 BERT 相同;
- Segment-Pair+NSP Loss:輸入完整的一對包含多個句子的片段,這些片段可以來自同一個文件,也可以來自不同的文件;
- Full-Sentences:輸入是一系列完整的句子,可以是來自同一個文件也可以是不同的文件;
- Doc-Sentences:輸入是一系列完整的句子,來自同一個文件;
結果發現完整句子會更好,來自同一個文件的會比來自不同文件的好一些,最終選用 Doc-Sentences 策略。表4:RoBERTa 在更多訓練資料和更久訓練時間下的實驗結果作者還嘗試了更多的訓練資料以及更久的訓練時間,發現都能提升模型的表現。這種思路一定程度上與 OpenAI 前段時間放出的 GPT2.0 暴力擴充資料方法有點類似,但是需要消耗大量的計算資源。3. SpanBERT: Improving Pre-training by Representing and Predicting Spans
圖6:SpanBER模型框架以及在 GLUE 中的實驗結果不同於 RoBERTa,SpanBERT 通過修改模型的預訓練任務和目標使模型達到更好的效果。其修改主要是三個方面:- Span Masking:這個方法與之前 BERT 團隊放出WWM(Whole Word Masking)類似,即在 mask 時 mask 一整個單詞的 token 而非原來單個token。每次 mask 前,從一個幾何分佈中取樣得到需要 mask 的 span 的長度,並等概率地對輸入中為該長度的 span 進行 mask,直到 mask 完15%的輸入。
- Span Boundary Object:使用 span 前一個 token 和末尾後一個 token 以及 token 位置的 fixed-representation 表示 span 內部的一個 token。並以此來預測該 token,使用交叉熵作為新的 loss 加入到最終的 loss 函式中。該機制使得模型在 Span-Level 的任務種能獲得更好的表現。
- Single-Sequence Training:直接輸入一整段連續的 sequence,這樣可以使得模型獲得更長的上下文資訊。
在這三個機制下,SpanBERT 使用與 BERT 相同的語料進行訓練,最終在 GLUE 中獲得82.8的表現,高於原版 Google BERT 2.4%,高於他們調參後的 BERT 1%,同時在 Coreference Resolution 上將最好結果提高了6.6%。4. MT-DNN 與知識蒸餾
Multi-Task Deep Neural Networks for Natural Language Understanding這篇論文旨在將 Multi-Task 與 BERT 結合起來,使得模型能在更多的資料上進行訓練的同時還能獲得更好的遷移能力(Transfer Ability)。模型架構如上圖所示,在輸入以及 Transformer 層,採用與 BERT 相同的機制,但是在後續處理不同任務資料時使用不同的任務引數與輸出的表示做點積(Dot Production),用不同的啟用函式(Activation Function)和損失函式(Loss Function)進行訓練。
MT-DNN 具有不錯的遷移能力。如上圖所示,MT-DNN 只需要23個任務樣本就可以在 SNLI 中獲得82%的準確率!尤其是 BERT 在一些小資料集上微調可能存在無法收斂表現很差的情況,MT-DNN 就可以比較好地解決這一問題,同時節省了新任務上標註資料以及長時間微調的成本。Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding
由於 MT-DNN 可以看作一個 ensemble 過程,所以就可以用知識蒸餾(Knowledge Distillation)進行優化,該方法能提升很多 ensemble 模型的表現,感興趣的讀者可以自行了解相關內容。本文的知識蒸餾過程即對於不同的任務,使用相同的結構在對應的資料集上進行微調,這就可以看作每個任務的 Teacher,他們分別擅長解決對應的問題。Student 則去擬合 target Q,並且使用 soft 交叉熵損失(Cross Entropy Loss)。為什麼使用 soft 交叉熵損失呢?因為有些句子的意思可能並不是絕對的,比如“I really enjoyed the conversation with Tom"有一定概率說的是反語,而不是100%的積極意思。這樣能讓 Student 學到更多的資訊。採用知識蒸餾後,模型在 GLUE 中的表現增長了1%,目前排名前三。我們還可以期待 MT-DNN 機制在 XLNet 上等其他預訓練模型中的表現。
對 BERT 在部分 NLP 任務中表現的深入分析
上文的 BERT 在 NLP 許多工中都取得了耀眼的成績,甚至有人認為 BERT 幾乎解決了 NLP 領域的問題,但接下來的兩篇文章則給人們澆了一盆冷水。1. BERT 在 Argument Reasoning Comprehension 任務中的表現Probing Neural Network Comprehension of Natural Language Arguments表5:BERT 在 Argument Reasoning Comprehension 任務中的表現
該文主要探究 BERT 在 ARCT(Argument Reasoning Comprehension)任務中取得驚人表現的真正原因。首先,ARCT 任務是 Habernal 等人在 NACCL 2018 中提出的,即在給定的前提(premise)下,對於某個陳述(claim),相反的兩個依據(warrant0,warrant1)哪個能支援前提到陳述的推理。他們還在 SemEval-2018 中指出,這個任務不僅需要模型理解推理的結構,還需要一定的外部知識。在本例中,這個外部知識可以是“Sport Leagues 是一個和 Sport 相關的某組織”。該任務中表現最好的模型是 GIST,這裡不詳細展開,有興趣的讀者可以關注該論文。作者嘗試使用 BERT 處理該任務,調整輸入為[CLS,Claim,Reason,SEP,Warrant ],通過共用的 linear layer 獲得一個 logit(類似於邏輯迴歸),分別用 warrant0 和 warrant1 做一次,通過 softmax 歸一化成兩個概率,優化目標是使得答案對應的概率最大。最終該模型在測試集中獲得最高77%的準確率。需要說明的是,因為 ARCT 資料集過小,僅有1210條訓練樣本,使得 BERT 在微調時容易產生不穩定的表現。因此作者進行了20次實驗,去掉了退化(Degeneration,即在訓練集上的結果非常差)的實驗結果,統計得到上述表格。表6:作者的探索性實驗(Probing Experiments)雖然實驗結果非常好,但作者懷疑:這究竟是 BERT 學到了需要的語義資訊,還是隻是過度利用了資料中的統計資訊,因此作者提出了關於 cue 的一些概念:- A Cue's Applicability:在某個資料點 i,label 為 j 的 warrant 中出現但在另一個 warrant 中不出現的 cue 的個數。
- A Cue's Productivity:在某個資料點 i,label 為 j 的 warrant 中出現但在另一個 warrant 中不出現,且這個資料點的正確 label 是 j,佔所有上一種 cue 的比例。直觀來說就是這個 cue 能被模型利用的價值,只要這個資料大於50%,那麼我們就可以認為模型使用這個 cue 是有價值的。
- A Cue's Coverage:這個 cue 在所有資料點中出現的次數。
這樣的 cue 有很多,如 not、are 等。如上圖表一所示是 not 的出現情況,可以看出 not 在64%的資料點中都有出現,並且模型只要選擇有 not 出現的 warrant,正確的概率是61%。作者懷疑模型學到的是這樣的資訊。如果推論成立,只需輸入 warrant,模型就能獲得很好的表現。因此作者也做了上圖表二所示的實驗。可以看出,只輸入 w 模型就獲得了71%的峰值表現,而輸入(R,W)則能增加4%,輸入(C,W)則能增加2%,正好71%+4%+2%=77%,這是一個很強的證據。為了充分證明推論的正確性,作者構造了對抗資料集(Adversarial Dataset),如上圖例子所示,對於原來的結構:R and W -> C,變換成:Rand !W -> !C(這裡為了方便,用!表示取反)作者首先讓模型在原 ARCT 資料集微調並在對抗資料集評測(Evaluation),結果比隨機還要糟糕。後來又在對抗資料集微調並在對抗資料集評測,獲得表現如上圖第二個表所示。從實驗結果來看,對抗資料集基本上消除了 cue 帶來的影響,讓 BERT 真實地展現了其在該任務上的能力,與作者的猜想一致。雖然實驗稍顯不足(如未充分說明模型是否收斂,其他模型在對抗資料集中的表現如何等),但本文給 BERT 的火熱澆了一盆冷水,充分說明了 BERT 並不是萬能的,我們必須冷靜思考 BERT 如今取得驚人表現的真正原因。2. BERT 在 Natural Language Inference 任務中的表現Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language這是另一篇對 BERT 等模型在自然語言推理(Natural Language Inference,NLI)任務中表現的探討。圖12:NLI 任務中 Heuristic 示意圖
作者首先假設在 NLI 中表現好的模型可能利用了三種 Heuristic,而所謂的 Heuristic 即在 Premise 中就給了模型一些提示,有如下三種:- Lexical Overlap:對應的 Hypothesis 是 Premise 的子序列
- Subsequence:對應的 Hypothesis 是 Premise 的子串
- Constituent:Premise 的語法樹會覆蓋所有的 Hypothesis
基於這個假設,作者也做了實驗並觀察到,MNLI 訓練集中許多資料點都存在這樣的 Heuristic,且對應的選項是正確的數量遠多於不正確。針對這種情況,作者構造了 HANS 資料集,均衡兩種型別樣本的分佈,並且標記了 premise 是否 entail 上述幾種 Heuristic。實驗時模型在 MNLI 資料集微調,在 HANS 資料集評測,結果 entailment 型別的資料點中模型都表現不錯,而在 non-entailment 型別中模型表現欠佳。這一實驗結果支援了作者的假設:模型過度利用了 Heuristic 資訊。但是作者並不十分確定這種實驗結果是什麼原因導致的,並提出如下猜想:- HANS 資料集太難了?不。作者讓人類進行測試,發現人類在兩種型別的資料中準確率分別為77%和75%,遠高於模型。
- 是模型缺乏足夠的表示能力嗎?不。ICLR 2019《RNNs implicitly implement tensor-product representations》給出了一定的證據,表示 RNN 足夠在 SNLI 任務中已經學到一定的關於結構的資訊。
- 那就是 MNLI 資料集並不好,缺乏足夠的訊號讓模型學會 NLI。
因此作者在訓練集中加入了一定的 HANS 資料,構造了 MNL+資料集,讓模型在該資料集微調,最終獲得瞭如上圖所示的結果。為了證明 HANS 對模型學到 NLI 的貢獻,作者還讓在 MNL+上微調的模型在另一個數據集中做了評測,模型表現都有提升。BERT 是一個優秀的預訓練模型,它的預訓練思想可以用來改進其他模型。BERT 可以更好,我們可以設定新的訓練方式和目標,讓其發揮更大的潛能。但 BERT 並沒有想象中的那麼好,我們必須冷靜對待 BERT 在一些任務中取得不錯表現的原因——究竟是因為 BERT 真正學到了對應的語義資訊,還是因為資料集中資料的不平衡導致 BERT 過度使用了這樣的訊號。http://www.msra.cn/wp-content/uploads/2019/09/How-Powerful-are-BERTs.pdf[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding. Yang et al.CoRR abs/1906.08237.[2] A Fair Comparison Study of XLNet and BERT. XLNet Team. http://medium.com/@xlnet.team/a-fair-comparison-study-of-xlnet-and-bert-with-large-models-5a4257f59dc0[3] Probing Neural Network Comprehension of Natural Language Arguments. Niven et al. ACL2019.[4] Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. McCoy el al. Corr abs/1902.01007.[5] RoBERTa: A Robustly Optimized BERT Pretraining Approach. Liu et al. CoRR abs/190.11692.[6] SpanBERT: Improving Pre-training by Representing and Predicting Spans. Joshi et al. CoRRabs/1907.10529.[7] Multi-Task Deep Neural Networks for Natural Language Understanding. Liu et al. CoRR abs/1901.11504.[8] Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. Liu et al. CoRR abs/1904.09482.
(*本文為AI科技大本營轉載文章,轉載請聯絡作者)



 ,收到请求立即删除
,收到请求立即删除
朋友會在“發現-看一看”看到你“在看”的內容