作者丨gongyouliu
編輯丨Zandy
來源 | 大資料與人工智慧(ID: ai-big-data)
作者在上篇文章中講解了《矩陣分解推薦演算法》,我們知道了矩陣分解是一類高效的嵌入演算法,通過將使用者和標的物嵌入低維空間,再利用使用者和標的物嵌入向量的內積來預測使用者對標的物的偏好得分。本篇文章我們會講解一類新的演算法:因子分解機(Factorization Machine,簡稱FM,為了後面書寫簡單起見,中文簡稱為分解機),該演算法的核心思路來源於矩陣分解演算法,矩陣分解演算法可以看成是分解機的特例(我們在第三節1中會詳細說明)。分解機自從2010年被提出後,由於易於整合交叉特徵、可以處理高度稀疏資料,並且效果不錯,在推薦系統及廣告CTR預估等領域得到了大規模使用,國內很多大廠(如美團、頭條等)都用它來做推薦及CTR預估。
本篇文章我們會從分解機簡單介紹、分解機的引數估計與模型價值、分解機與其他模型的關係、分解機的工程實現、分解機的拓展、近實時分解機、分解機在推薦上的應用、分解機的優勢等8個方面來講解分解機相關的知識點。期望本文的梳理可以讓讀者更好地瞭解分解機的原理和應用價值,並且嘗試將分解機演算法應用到自己的業務中。
一、分解機簡單介紹
分解機最早由Steffen Rendle於2010年在ICDM會議(Industrial Conference on Data Mining)上提出,它是一種通用的預測方法,即使在資料非常稀疏的情況下,依然能估計出可靠的引數,並進行預測。與傳統的簡單線性模型不同的是,因子分解機考慮了特徵間的交叉,對所有特徵變數互動進行建模(類似於SVM中的核函式),因此在推薦系統和計算廣告領域關注的點選率CTR(click-through rate)和轉化率CVR(conversion rate)兩項指標上有著良好的表現。此外,FM模型還具備可以用線性時間來計算,可以整合多種資訊,以及能夠與許多其他模型相融合等優點。
我們常用的簡單模型有線性迴歸模型及logistic迴歸模型(LR)(見下面兩個公式),它們都是簡單的線性模型,原理簡單,易於理解,並且非常容易訓練,對於一般的分類及預測問題,可以提供簡單的解決方案。但是,特徵之間是彼此獨立的,無法擬合特徵之間的非線性關係,而現實生活中往往特徵之間不是獨立的而是存在一定的內在聯絡,以新聞推薦為例,一般男性使用者看軍事新聞多,而女性使用者喜歡情感類新聞,那麼可以看出性別與新聞的類別有一定的關聯性,如果能找出這類相關的特徵,是非常有意義的,可以顯著提升模型預測的準確度。
LR模型是CTR預估領域早期最成功的模型,也大量用於推薦演算法排序階段,大多工業推薦排序系統通過整合人工非線性特徵,最終採用這種“線性模型+人工特徵組合引入非線性”的模式來訓練LR模型。因為LR模型具有簡單、方便易用、解釋強、易於分散式實現等諸多好處,所以目前工業上仍然有不少算法系統採取這種模式。但是,LR模型最大的缺陷就是人工特徵工程,耗時費力,浪費大量人力資源來篩選組合非線性特徵,那麼能否將特徵組合的能力體現在模型層面呢?也即,是否有一種模型可以自動化地組合篩選交叉特徵呢?答案是肯定的。
其實想達到這一點並不難,如上圖線上性模型的計算公式里加入二階特徵組合即可,任意兩個特徵進行兩兩組合,可以將這些組合出的特徵看作一個新特徵,加入線性模型中。而組合特徵的權重和一階特徵權重一樣,在訓練階段學習獲得。其實這種二階特徵組合的使用方式,和多項式核SVM是等價的(我們在第三節2中會介紹)。藉助SVM中核函式的思路,我們可以線上性模型中整合二階交叉特徵,得到如下的模型。
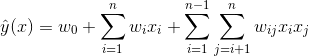
雖然這個模型看上去貌似解決了二階特徵組合問題,但是它有個潛在的缺陷:它對組合特徵建模,泛化能力比較弱,尤其是在大規模稀疏特徵存在的場景下,這個毛病尤其嚴重。在資料稀疏的情況下,滿足交叉項不為0的樣本將非常少(非常少的主要原因有,有些特徵本來就是稀疏的,很多樣本在該特徵上是無值的,有些是由於收集該特徵成本過大或者由於監管、隱私等原因無法收集到),當訓練樣本不足時,很容易導致引數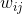 訓練不充分而不準確,最終影響模型的效果。特別是對於推薦、廣告等這類資料非常稀疏的業務場景來說(這些場景的最大特點就是特徵非常稀疏,推薦是由於標的物是海量的,每個使用者只對很少的標的物有操作,因此很稀疏,廣告是由於很少有使用者去點選廣告,點選率很低,導致收集的資料量很少,因此也很稀疏),很多特徵之間交叉是沒有(或者沒有足夠多)訓練資料支撐的,因此無法很好地學習出對應的模型引數。因此上述整合二階兩兩交叉特徵的模型並未在工業界得到廣泛採用。那麼我們有辦法解決該問題嗎?其實是有的,我們可以藉助矩陣分解的思路,對二階交叉特徵的係數進行調整,讓係數不在是獨立無關的,從而減少模型獨立係數的數量,解決由於資料稀疏導致無法訓練出引數的問題,具體是將上面的模型修改為
訓練不充分而不準確,最終影響模型的效果。特別是對於推薦、廣告等這類資料非常稀疏的業務場景來說(這些場景的最大特點就是特徵非常稀疏,推薦是由於標的物是海量的,每個使用者只對很少的標的物有操作,因此很稀疏,廣告是由於很少有使用者去點選廣告,點選率很低,導致收集的資料量很少,因此也很稀疏),很多特徵之間交叉是沒有(或者沒有足夠多)訓練資料支撐的,因此無法很好地學習出對應的模型引數。因此上述整合二階兩兩交叉特徵的模型並未在工業界得到廣泛採用。那麼我們有辦法解決該問題嗎?其實是有的,我們可以藉助矩陣分解的思路,對二階交叉特徵的係數進行調整,讓係數不在是獨立無關的,從而減少模型獨立係數的數量,解決由於資料稀疏導致無法訓練出引數的問題,具體是將上面的模型修改為
其中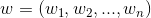 ,是n維向量。
,是n維向量。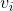 、
、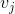 是低維向量(k維),類似矩陣分解中的使用者或者標的物特徵向量表示。V是由 組成的矩陣。 是兩個k維向量的內積:就是我們的FM模型核心的分解向量,k是超引數,一般取值較小(100左右)。利用線性代數的知識,我們知道對於任意對稱的正半定矩陣W,只要k足夠大,一定存在矩陣V使得
是低維向量(k維),類似矩陣分解中的使用者或者標的物特徵向量表示。V是由 組成的矩陣。 是兩個k維向量的內積:就是我們的FM模型核心的分解向量,k是超引數,一般取值較小(100左右)。利用線性代數的知識,我們知道對於任意對稱的正半定矩陣W,只要k足夠大,一定存在矩陣V使得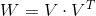 (Cholesky decomposition)。這說明,FM這種通過分解的方式基本可以擬合任意的二階交叉特徵,只要分解的維度k足夠大(首先,
(Cholesky decomposition)。這說明,FM這種通過分解的方式基本可以擬合任意的二階交叉特徵,只要分解的維度k足夠大(首先,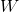 的每個元素都是兩個向量的內積,所以一定是對稱的,另外,分解機的公式中不包含
的每個元素都是兩個向量的內積,所以一定是對稱的,另外,分解機的公式中不包含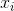 與自身的交叉,這對應矩陣的對角元素,所以我們可以任意選擇對角元素足夠大,保證是半正定的)。由於在稀疏情況下,沒有足夠的訓練資料來支撐模型訓練,一般選擇較小的k,雖然模型表達空間變小了,但是在稀疏情況下可以達到較好的效果,並且有很好的拓展性。上面我們對分解機產生的背景、具體的模型公式及特點做了簡單介紹,下面一節我們來講解怎麼估計分解機的引數以及簡單介紹一下分解機可以用於哪些機器學習任務。
與自身的交叉,這對應矩陣的對角元素,所以我們可以任意選擇對角元素足夠大,保證是半正定的)。由於在稀疏情況下,沒有足夠的訓練資料來支撐模型訓練,一般選擇較小的k,雖然模型表達空間變小了,但是在稀疏情況下可以達到較好的效果,並且有很好的拓展性。上面我們對分解機產生的背景、具體的模型公式及特點做了簡單介紹,下面一節我們來講解怎麼估計分解機的引數以及簡單介紹一下分解機可以用於哪些機器學習任務。
本節我們從分解機為什麼可以解決稀疏場景下引數估計、計算複雜度、模型求解、分解機可以解決哪幾類學習任務四個方面來簡要說明。
對於稀疏資料場景,一般沒有足夠的資料來直接估計變數之間的互動,但是分解機可以很好地解決這個問題。通過將交叉特徵係數做分解,讓不同的交叉項之間不再獨立,因此一個交叉項的資料可以輔助來估計(訓練)另一個交叉項(只要這兩個交叉項有一個變數是相同的,比如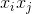 與
與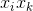 ,它們的係數
,它們的係數 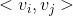 和
和 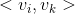 共用一個相同的向量)。分解機模型通過將二階交叉特徵係數做分解,讓二階交叉項的係數不再獨立,因此係數數量是遠遠小於直接線上性模型中整合二階交叉特徵的。分解機的係數個數為
共用一個相同的向量)。分解機模型通過將二階交叉特徵係數做分解,讓二階交叉項的係數不再獨立,因此係數數量是遠遠小於直接線上性模型中整合二階交叉特徵的。分解機的係數個數為 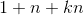 ,而整合兩兩二階交叉的線性模型的係數個數為
,而整合兩兩二階交叉的線性模型的係數個數為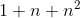 。分解機的係數個數是n的線性函式,而整合交叉項的線性模型係數個數是n的指數函式,當n非常大時,訓練分解機模型在儲存空間及迭代速度上是非常有優勢的。直接從公式1來看,因為我們需要處理所有特徵交叉,所以計算複雜度是
。分解機的係數個數是n的線性函式,而整合交叉項的線性模型係數個數是n的指數函式,當n非常大時,訓練分解機模型在儲存空間及迭代速度上是非常有優勢的。直接從公式1來看,因為我們需要處理所有特徵交叉,所以計算複雜度是 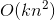 。但是我們可以通過適當的公式變換與數學計算,將模型複雜度降低到
。但是我們可以通過適當的公式變換與數學計算,將模型複雜度降低到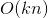 ,變成線性複雜度的預測模型,具體推導過程如下:公式2:FM交叉項的計算可以簡化為線性複雜度的計算從上面公式最後一步可以看到,括號裡面複雜度是
,變成線性複雜度的預測模型,具體推導過程如下:公式2:FM交叉項的計算可以簡化為線性複雜度的計算從上面公式最後一步可以看到,括號裡面複雜度是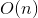 ,加上外層的
,加上外層的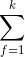 ,最終的時間複雜度是。進一步地,在資料稀疏情況下,大多數特徵x為0,我們只需要對非零的x求和,因此,時間複雜度其實是
,最終的時間複雜度是。進一步地,在資料稀疏情況下,大多數特徵x為0,我們只需要對非零的x求和,因此,時間複雜度其實是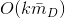 ,
,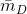 是訓練樣本中平均非零的特徵個數。後面我們會說明對於矩陣分解演算法來說=2,因此對於矩陣分解來說,計算量是非常小的。由於分解機模型可以線上性時間下計算出,對於我們做預測是非常有價值的,特別是對網際網路產品有海量使用者的情況。拿推薦來說,我們每天需要為每個使用者計算推薦(這是離線推薦,實時推薦計算量會更大),線性時間複雜度可以讓整個計算過程更加高效,可以在更短的時間完成計算,節省伺服器資源。
是訓練樣本中平均非零的特徵個數。後面我們會說明對於矩陣分解演算法來說=2,因此對於矩陣分解來說,計算量是非常小的。由於分解機模型可以線上性時間下計算出,對於我們做預測是非常有價值的,特別是對網際網路產品有海量使用者的情況。拿推薦來說,我們每天需要為每個使用者計算推薦(這是離線推薦,實時推薦計算量會更大),線性時間複雜度可以讓整個計算過程更加高效,可以在更短的時間完成計算,節省伺服器資源。
分解機模型公式相對簡單,完全可導,我們可以用平方損失函式、logit損失函式或者hinge損失函式來學習FM模型。從2的介紹我們知道分解機模型的值可以線上性時間複雜度計算出來,因此FM的模型引數(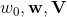 )可以在工程實現上高效地利用梯度下降演算法(SGD、ALS等)來訓練(即我們可以線性時間複雜度求出下面的
)可以在工程實現上高效地利用梯度下降演算法(SGD、ALS等)來訓練(即我們可以線性時間複雜度求出下面的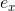 ,所以在迭代更新引數時是非常高效的,見下面的迭代更新引數的公式)。結合公式1和公式2,我們很容易計算出FM模型的梯度如下:我們記
,所以在迭代更新引數時是非常高效的,見下面的迭代更新引數的公式)。結合公式1和公式2,我們很容易計算出FM模型的梯度如下:我們記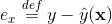 ,針對平方損失函式,具體的引數更新公式如下(未增加正則項,其他損失函式的迭代更新公式類似,也可以很容易推匯出):其中,
,針對平方損失函式,具體的引數更新公式如下(未增加正則項,其他損失函式的迭代更新公式類似,也可以很容易推匯出):其中,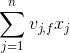 與i無關,因此可以事先計算出來(在做預測求
與i無關,因此可以事先計算出來(在做預測求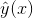 或者在更新引數前,這兩步都需要計算該量)。上面的梯度計算可以在常數時間複雜度
或者在更新引數前,這兩步都需要計算該量)。上面的梯度計算可以在常數時間複雜度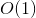 下計算出來。在模型訓練更新時,在時間複雜度下完成對樣本
下計算出來。在模型訓練更新時,在時間複雜度下完成對樣本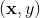 的更新(如果是稀疏情況下,更新時間複雜度是
的更新(如果是稀疏情況下,更新時間複雜度是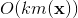 ,
, 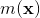 是特徵
是特徵 非零元素個數)。我們在第4節工程實現中會細講怎麼進行模型訓練。
非零元素個數)。我們在第4節工程實現中會細講怎麼進行模型訓練。
直接作為預測項,可以轉化為求最小值的最優化問題,具體如下:其中D是訓練資料集,y是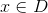 對應的真實值。
對應的真實值。
(2) 二元分類問題 (Binary Classification)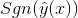 最為最終的分類,我們可以通過hinge loss或者logit loss來訓練二元分類問題。
最為最終的分類,我們可以通過hinge loss或者logit loss來訓練二元分類問題。
對於排序學習問題(如pairwise),我們可以利用排序演算法相關的loss函式來訓練FM模型,利用FM模型來做排序學習。在所有上面3類問題中,我們都可以通過增加正則項到目標函式中,避免模型過擬合。
分解機的思想是從線性模型中通過增加二階交叉項來擬合特徵之間的交叉,為了拓展到資料稀疏場景並便於計算,吸收了矩陣分解的思想。在這一節中我們來簡單講解一下分解機與其他模型之間的關係,特別是與矩陣分解和SVM之間的關係,讓讀者更好地瞭解他們之間的區別與聯絡,從而更好地理解分解機。對於隱式協同過濾來說,我們用使用者和標的物兩類特徵來作為FM的特徵,特徵的維度為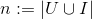 (使用者數+標的物數),其中
(使用者數+標的物數),其中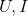 分別是使用者集和標的物集,我們可以將矩陣分解看成兩個類別變數U和I之間的互動(交叉)。顯然我們有下面的關係,其中
分別是使用者集和標的物集,我們可以將矩陣分解看成兩個類別變數U和I之間的互動(交叉)。顯然我們有下面的關係,其中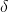 是指標變數(indicator variable)。
是指標變數(indicator variable)。
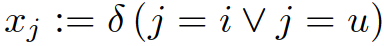
只有當特徵為u或者i時,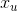 =1或者=1,這即是使用者u對標的物i進行了一次隱式反饋,每個樣本中有且只有2個特徵不為零(=1),如下圖。
=1或者=1,這即是使用者u對標的物i進行了一次隱式反饋,每個樣本中有且只有2個特徵不為零(=1),如下圖。
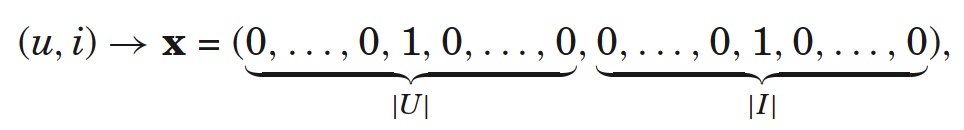
這時,FM模型可以表示為
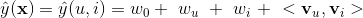
上面的公式跟包含使用者和標的物bias的矩陣分解演算法是一樣的,所以可以說矩陣分解演算法是FM的一種特例。3.2 FM與SVM的聯絡
SVM可以表示為輸入變換後的向量與模型引數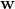 的內積:
的內積: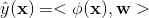 ,這裡
,這裡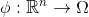 將輸入向量對映到一個複雜的空間,
將輸入向量對映到一個複雜的空間, 通過內積與核函式建立關聯:
通過內積與核函式建立關聯: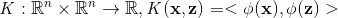
下面我們分線性核函式和多項式核函式兩種情況來說明SVM與FM之間的關係。
(1) 線性核
最簡單的線性核函式是: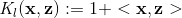 ,該核函式對應的對映為
,該核函式對應的對映為
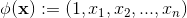
線性核的SVM模型方程可以寫為
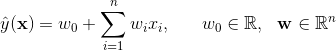
這對應無二階交叉項的FM,也即是第五節1高階分解機中的一階分解機。
(2) 多項式核
多項式核的SVM可以建模自變數的高階交叉特徵,它的核函式是
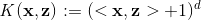
當d=2(二階交叉特徵),對應的對映(其中可行的一個)為
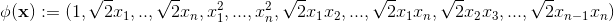
這時二階多項式核的SVM模型方程為
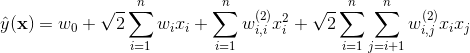
其中,
 。
。
從2階多項式核的SVM的模型方程來看,它與FM模型方程(公式1)的主要區別有2點,一是SVM二階交叉項的引數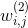 是獨立的(如與
是獨立的(如與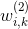 是獨立的),而FM中二階交叉項是有關聯的,
是獨立的),而FM中二階交叉項是有關聯的,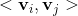 與
與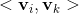 之間相關,都依賴
之間相關,都依賴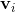 。二是SVM有變數與自己的交叉(如
。二是SVM有變數與自己的交叉(如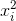 等)而FM沒有。
等)而FM沒有。
(3) 線性核和多項式核下SVM存在的問題
下面我們來說明在資料稀疏情況下,SVM無法很好地學習模型,我們拿隱式反饋的協同過濾(特徵的值為0或者1)來說,利用使用者特徵和標的物特徵兩類特徵來訓練模型,預估使用者對標的物的偏好。使用者特徵是n(使用者數)維的,標的物特徵是m(標的物數)維的,這時每一個樣本的特徵只有兩個特徵非零,其他都為零(該使用者所在的列及該使用者有過行為的標的物這列非零)。資料是相當稀疏的(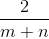 的資料非零,一般m、n是非常大的,所以非常稀疏)。
的資料非零,一般m、n是非常大的,所以非常稀疏)。
針對上面提到的協同過濾資料,線性SVM模型等價為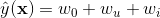 。從作者的上篇文章《協同過濾推薦系統》,可以知道,該模型非常簡單,僅僅整合了使用者和標的物的bias,沒有使用者和標的物嵌入向量的內積項,因此非常容易訓練,但是效果不會很好。
。從作者的上篇文章《協同過濾推薦系統》,可以知道,該模型非常簡單,僅僅整合了使用者和標的物的bias,沒有使用者和標的物嵌入向量的內積項,因此非常容易訓練,但是效果不會很好。
同樣地,針對上面的協同過濾案例,二階多項式核的SVM的模型方程現在變為
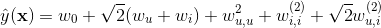
從上式可以看到,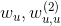 其實表達的都是使用者相關的特徵,我們可以將它們合併為一項,同理,
其實表達的都是使用者相關的特徵,我們可以將它們合併為一項,同理,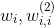 也可以歸併在一起。通過歸併,最終模型變為
也可以歸併在一起。通過歸併,最終模型變為
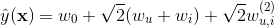
一般來說,大多數情況一個使用者只對某個標的物進行一次隱式反饋,因此針對劃分在測試集中的(u,i)對,在訓練集中沒有資料與之對應,這時,我們無資料用於訓練求引數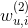 。因此在隱式協同過濾場景下,二階多項式核的SVM無法很好利用二階交叉特徵,只能訓練出使用者和標的物的bias(
。因此在隱式協同過濾場景下,二階多項式核的SVM無法很好利用二階交叉特徵,只能訓練出使用者和標的物的bias(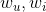 ),最終效果其實跟線性SVM是一樣的。
),最終效果其實跟線性SVM是一樣的。
通過上面的講解及案例介紹,下面總結一下FM與SVM的主要差異點:
(1) 在稀疏資料情況下,SVM模型相互獨立的高階交叉引數無法得到很好的訓練,而FM由於二階交叉項的引數是通過分解得到的,引數之間是有關聯的,所以更容易訓練出,特別是在稀疏資料情況下,其他交叉項的訓練資料可以用於訓練,因此效果相對更好。(2) FM模型可以直接學習,而SVM往往通過它的對偶形式進行學習;(3) FM的模型方程與訓練資料無關,而SVM在預測時依賴部分訓練資料(支援向量);到此,我們講完了FM與矩陣分解及SVM之間的關係及區別,參考文獻2中有關於FM與其他更多模型之間的關係介紹,感興趣的讀者可以閱讀進行深入學習。
前面幾節講解了FM的原理、引數估計方法、與其他模型之間的關係,我們知道FM是一個表達能力很強的模型,並且線上性時間複雜度下可求解,那麼具體在工程上怎麼訓練FM模型呢?本節我們試圖講解一般的方法,本節的思路來源於參考文獻1,FM的提出者Rendle給出了FM的工程實現,並且基於該文章的思路,Rendle開源了一個求解FM的高效C++庫:libFM,讀者可以參考http://www.libfm.org/。另外,參考文獻12提供了FM的一種實現,可以利用分解機解決各類迴歸、分類、排序問題,14、17講解了怎麼分散式訓練FM模型,也是比較好的參考文獻。
libFM通過SGD、ALS、MCMC三種方法來訓練FM模型,下面我們介紹利用SGD來求解FM模型,其他演算法讀者可以參考該論文,這裡不再講解。在講解具體的方法之前,我們先來統一符號化FM模型,將該模型的求解轉化為求極值的最優化問題,方面後面講解怎麼迭代訓練。通過定義訓練集S的損失函式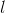 ,一般優化問題可以轉化為求所有損失的和的最小值問題,定義如下:對於迴歸問題,一般用最小平方損失,對應的損失函式為
,一般優化問題可以轉化為求所有損失的和的最小值問題,定義如下:對於迴歸問題,一般用最小平方損失,對應的損失函式為 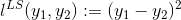 ,對於二分類問題,損失函式可以定義為:
,對於二分類問題,損失函式可以定義為: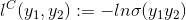 ,其中
,其中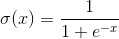 是logistic函式。直接學習上述最優化問題容易產生過擬合,一般會加入
是logistic函式。直接學習上述最優化問題容易產生過擬合,一般會加入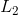 正則項,增加了正則化的最優化問題轉化為:上述增加了正則項的函式就是我們優化的目標函式,下面的講解都基於該目標函式。為了後面的演算法講解方便,下面我們先來求目標函式的導數,對於迴歸問題(最小平方損失)來說,導數為有了導數,下面我們來講解怎麼用SGD優化方法來求解FM模型。隨機梯度下降演算法(SGD)是分解類模型的常用迭代求解演算法,該方法簡單易懂,對各種損失函式效果都不錯,並且計算和儲存成本相對較低。下面的演算法1就是優化FM模型的SGD演算法。Output:模型引數
正則項,增加了正則化的最優化問題轉化為:上述增加了正則項的函式就是我們優化的目標函式,下面的講解都基於該目標函式。為了後面的演算法講解方便,下面我們先來求目標函式的導數,對於迴歸問題(最小平方損失)來說,導數為有了導數,下面我們來講解怎麼用SGD優化方法來求解FM模型。隨機梯度下降演算法(SGD)是分解類模型的常用迭代求解演算法,該方法簡單易懂,對各種損失函式效果都不錯,並且計算和儲存成本相對較低。下面的演算法1就是優化FM模型的SGD演算法。Output:模型引數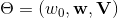 初始化:
初始化: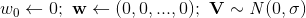 for
for 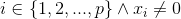 do for
do for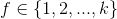 do上述演算法中可以針對不同的引數設定不同的正則化因子
do上述演算法中可以針對不同的引數設定不同的正則化因子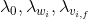 。對於一個訓練樣本,SGD演算法的時間複雜度是其中
。對於一個訓練樣本,SGD演算法的時間複雜度是其中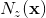 是特徵向量中非零元素個數。
是特徵向量中非零元素個數。
從應用的角度來說,讀者沒必要對求解FM的原理非常清楚,只要會用就可以了。libFM庫提供了一個方便的求解FM的工具,該庫在單機下執行,對於資料量大一次無法放入記憶體的情況,可以利用libFM二進位制的資料格式,它可以更快地讀取資料,並且一批只放部分資料到記憶體中進行訓練。如果資料量非常大,那麼我們就需要採用分散式FM模型了。業界有很多這樣的開源工具的,這裡推薦一個騰訊的Angel框架,它內建了很多FM演算法(及該演算法的變種)的實現,並且可以跟Spark配合使用,非常適合工業級FM模型的訓練。今年8月22日Angel釋出了全新的3.0版本,整合了PyTorch,它在 PyTorch On Angel 上實現了許多演算法:包括推薦領域常見的演算法(FM,DeepFM,Wide & Deep,xDeepFM,AttentionFM, DCN 和 PNN 等),Angel 擅長推薦模型和圖網路模型相關領域(如社交網路分析)。在騰訊內部,騰訊視訊,騰訊新聞和微信等都在使用 Angel ,我們公司也在嘗試使用Angel。
前面對分解機的算原理、工程實現等進行了介紹,我們知道分解機是一類非常有價值的模型,在工業界有大量應用,所以有很多人從各個維度對分解機進行了拓展與優化,讓分解機預測更加準確從而發揮更大的商業價值,本節我們就來講解分解機的各種拓展與變式,讓大家對分解機有更進一步的認識與瞭解。
傳統意義上講FM都是二階交叉,計算複雜度可通過數學變換將時間複雜度改進到線性時間,在實際應用中一般也只用到二階交叉。所謂高階分解機就是將交叉項拓展到最多d(d>2)個特徵的交叉,具體的模型如下: 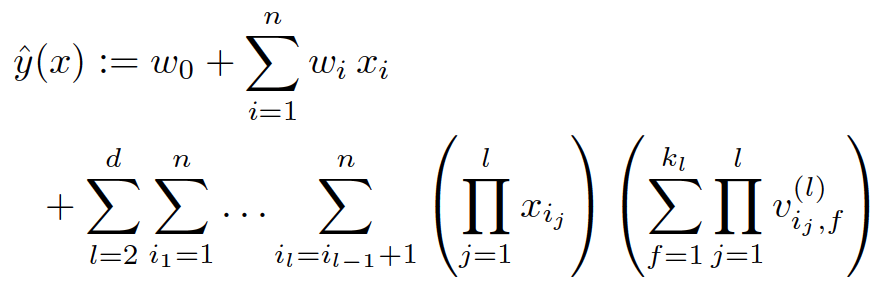
參考文獻2中有對高階分解機做簡單介紹,通過類似2階分解機的方法也可以將預測計算複雜度降低到線性時間複雜度,但是文章沒有細說怎麼做。參考文獻16對高階分解機進行了非常深入的介紹。這篇文章發表在NIPS 2016,它解決了三階甚至更高階的特徵交叉問題。有興趣的讀者可以參考閱讀。5.2 FFM(Field-aware Factoruzation Machine)5.3 DeepFM
DeepFM是2017年華為若亞方舟團隊提出的一個將FM與DNN有效結合的模型,主要借鑑Google的Wide&Deep;論文的思想並進行適當改進,將其中wide部分(logistic迴歸)換成FM與DNN進特徵交叉。wide和deep部分共享原始輸入特徵向量,這讓DeepFM可以直接從原始特徵中同時學習低階和高階特徵交叉,因此不像Wide&Deep;模型那樣,需要進行復雜的人工特徵工程(logistic迴歸部分需要人工特徵工程),同時訓練效率會更高(DeepFM的網路結構參考下面圖1)。參考文獻中的15、20、28也是關於FM與深度學習結合的拓展。 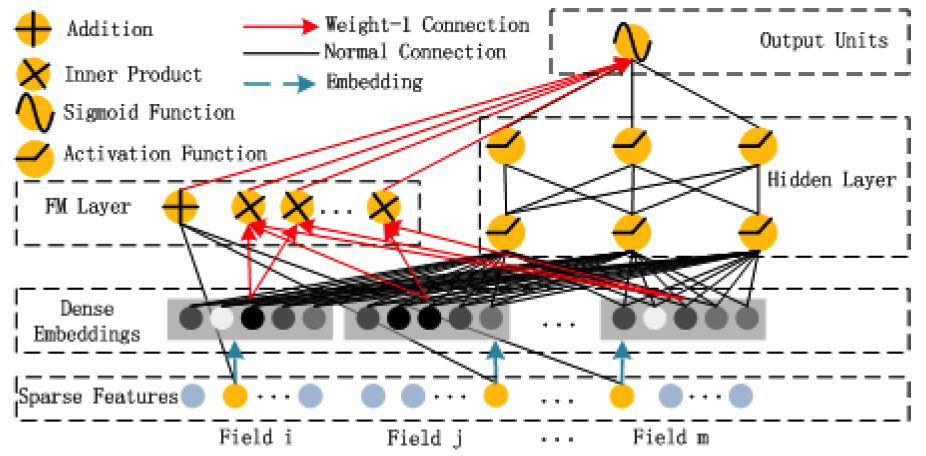
圖1:DeepFM的網路結構(圖片來源於參考文獻4)
該演算法從提出後,被工業界大量用於廣告點選預估和推薦系統(如美團將DeepFM用於CTR預估),有非常不錯的效果。該團隊在參考文獻5中進一步對DeepFM兩種變種進行了比較,並在華為的應用市場APP推薦真實業務場景中做AB測試,發現比原來的LR演算法有近10%的點選率提升。騰訊開源的Angel(Spark on Angel)中有DeepFM的實現,讀者可以嘗試將DeepFM應用到自己的推薦或者CTR預估業務中。
Google在2013年提出了FTRL(Follow-The-Regularized-Leader)用於廣告點選率預估,該方法可以高效地線上訓練LR模型,在Google及國內公司得到大規模工業應用,廣泛用於廣告點選率預估和推薦排序。想了解的讀者可以閱讀參考文獻25,Tensorflow上有FTRL演算法的具體實現。基於FTRL的思路,可以對FM離線訓練演算法進行改造,讓FM具備線上學習的能力,參考文獻3、21、26、27中有關於利用FTRL技術對FM進行線上訓練的介紹,這幾篇文章涉及到很多數學理論的證明和推導,感興趣的讀者可以自行學習。上述論文讀不懂也沒關係,也不要讀者自己重複造輪子了,很多機器學習平臺上是有FM演算法的FTRL實現的,騰訊開源的Angel平臺上可以直接利用Spark On Angel(構建在Spark平臺上的,利用Angel引數伺服器的技術,讓Spark具備提供引數服務能力)中的FTRL-FM演算法,訓練上百億維特徵的線上FM模型。分解機可以作為一般的預測模型,用於迴歸和分類,特別是用在推薦系統和廣告點選率預估等商業場景。在本節我們簡單講講分解機在推薦系統上的應用。分解機在推薦系統上的應用,可以採用迴歸和預測兩類方法。當我們預測使用者對標的物的評分時,就是迴歸問題,當我們預測使用者對標的物是否點選時,可以看成是一個二分類問題,這時可以通過增加一個logit變換,轉化為預測使用者點選的概率問題。下面我們講講怎麼構建FM需要的特徵,有哪些資訊可以作為模型的輸入。構建FM模型的特徵主要分為如下4大類,我們來分別介紹。
包括使用者的點選、播放、收藏、搜尋、點贊等各種(隱式)行為。這些行為可以通過平展化的方式整合為特徵。比如有n個使用者,m個標的物。那麼使用者對某個標的物的行為平展化為n+m維的特徵子向量,其中使用者和標的物所在的列非零,其他為零,如下圖。上圖是使用者行為的隱式操作轉化為特徵子向量,特徵用0或者1表示,有隱式操作則為1,否則為0。也可以採用將使用者的每一種操作作為一個維度,每個維度的值代表使用者是否操作過或者對應的操作得分(比如使用者播放時長佔視訊總時長的比例作為得分),如下圖。
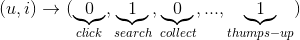
7.2 使用者相關資訊
使用者相關的資訊有很多,包括人口統計學資訊,如年齡、性別、職業、收入、地域、受教育程度等等。另外還可以包括使用者行為資訊,使用者是否是會員、什麼時候註冊過、最後一次登入時間、最後一次付費時間等。這些資訊都可以作為某一個維度的特徵灌入到FM模型中。標的物的metadata資訊都可以作為FM的特徵,拿電影推薦來說,電影的評分、年代、標籤、演職員、是否獲獎、是否高清、地區、語言、是否是付費節目等都可以作為特徵。其中評分、年代是數值特徵,標籤、演職員是類別特徵,可以採用n-hot編碼(每個電影有多個標籤,對應標籤上的值為1,所以這裡叫做n-hot編碼,而不是one-hot)。另外該節目的使用者行為也可以作為特徵,比如節目播放次數、節目平均播放完成度等。
使用者在操作標的物時,是包含上下文資訊的,這類上下文主要有時間、地點、上一步操作、所在路徑、甚至是天氣、心情等。時間可以是操作時間、是否是節日、是否是工作日、特殊事件(如雙十一)、作業系統、版本等。地域對於LBS類應用是非常重要的。對於像購物等具備漏斗行為轉化的產品或業務,使用者的上一步操作及所在路徑對訓練模型非常關鍵。
整合了上述4大類資訊,我們可以構建如下的訓練集,利用FM模型來訓練,求得引數,最終獲得訓練好的模型,用於線上預測。圖2:基於4類資訊構建分解機的訓練資料集
我們可以根據不同的業務形態、當前業務具備的資料等來按照上面的方式獲得模型特徵,最終構建分解機模型。參考文獻10、11、13、18中有怎麼利用FM來進行推薦的介紹,另外參考文獻23是一篇很長的博士畢業論文,綜述利用分解模型(主要是FM)做推薦的各種方法及細節介紹,值得大家學習參考。
在前面章節介紹FM時,我們零星提到了FM的各種特點。在本節,我們梳理一下FM的優勢,讓大家對FM的特性有一個更具體直觀的瞭解。FM之所以在學術界和工業界受到追捧,得益於它各種優點,這些優點主要體現在如下幾個方面。在真實業務場景中,往往特徵之間的交叉對模型預測是非常有幫助的,而分解機可以自動整合二階(高階)交叉特徵,免去了人工特徵工程(如logistic迴歸需要大量的人工特徵工程)的工作,從而(相比矩陣分解及logistic迴歸等模型)可以達到更好的訓練效果。
FM通過將預測函式做數學變換,將二階交叉特徵的計算從二階多項式的複雜度降低到線性複雜度,方便模型預測和通過SGD等迭代方法估計引數, 從而讓FM在工業界的大規模資料場景下的應用(推薦系統、CTR預估等)變得可行。
FM通過分解二階交叉特徵的係數到低維空間,避免了交叉特徵的係數獨立的情況,減少了引數空間,並且由於不同交叉項之間的係數是有關聯的,在高度稀疏的情況下,也可以容易估計模型係數,模型泛化能力強。
FM模型原理非常簡單,思想也很樸素,並且預測過程可以降低到線性時間複雜度,可以採用SGD等常用演算法來進行訓練,在工程實現上是相對容易的,有很多開源的工具都有FM的實現,我們可以直接拿來用。正因為工程實現簡單,才在工業界得到大規模的推廣和應用。
本文對分解機的演算法原理、引數估計、跟其他模型之間的關係、工程實現、分解機的拓展、近實時分解機、分解機在推薦上的應用、分解機優點等各個方面進行了綜合介紹。分解機類似SVM,是一個通用的預測器,適用於任何實值特徵向量的預測問題,不僅僅應用於推薦演算法,在廣告點選率預估等其他方面都有很大的商業應用價值。鑑於FM模型的巨大優勢和商業價值,自從FM被提出後,基於FM模型在學術界的研究和工業的實踐從未止步過,FM模型值得每一位做演算法的從業者研究、學習、實踐。
參考文獻:
Factorization Machines with libFM
factorization machines
Factorization Machines with Follow-The-Regularized-Leader for CTR prediction in Display Advertising
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction
http://github.com/srendle/libfm
http://www.libfm.org/
Scaling Factorization Machines to Relational Data
Bayesian Factorization Machines
Learning Recommender Systems with Adaptive Regularization
Fast Context-aware Recommendations with Factorization Machines
fastFM: A Library for Factorization Machines
Optimizing Factorization Machines for Top-N Context-Aware Recommendations
DiFacto — Distributed Factorization Machines
Attentional Factorization Machines- Learning the Weight of Feature Interactions via Attention Networks
Higher-Order Factorization Machines
F2M- Scalable Field-Aware Factorization Machines
Discrete Factorization Machines for Fast Feature-based Recommendation
Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
Neural Factorization Machines for Sparse Predictive Analytics
Sketched Follow-The-Regularized-Leader for Online Factorization Machine
Field-aware Factorization Machines for CTR Prediction
Advanced Factorization Models for Recommender Systems
http://github.com/Angel-ML/angel
Ad Click Prediction- a View from the Trenches
Compact convexified factorization machine: formulation and online algorithms
Online Compact Convexified Factorization Machine
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
推薦閱讀
邊界框的迴歸策略搞不懂?演算法太多分不清?看這篇就夠了
2億日活,日均千萬級視訊上傳,快手推薦系統如何應對技術挑戰
einsum,一個函式走天下
如何修改CentOS 6.x上預設Python版本
AI 假冒老闆騙取 24.3 萬美元
Android 10 重磅來襲:支援 5G 與摺疊屏、隱私安全全面升級!
今日頭條技術架構分析



 ,收到请求立即删除
,收到请求立即删除
朋友會在“發現-看一看”看到你“在看”的內容